吴江设计网站公司外链吧官网
大纲
- Souce
- schema
- descriptor
- Sink
- schema
- descriptor
- Execute
- 完整代码
- 参考资料
《0基础学习PyFlink——使用PyFlink的Sink将结果输出到Mysql》一文中,我们讲到如何通过定义Souce、Sink和Execute三个SQL,来实现数据读取、清洗、计算和入库。
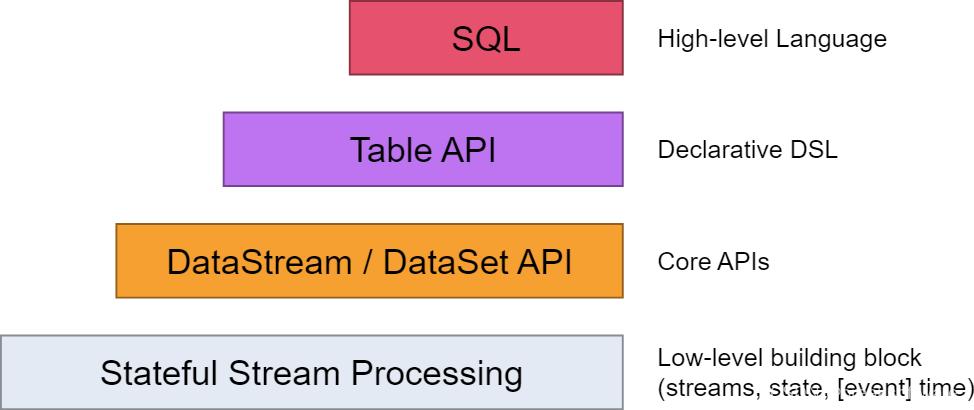
如下图所示SQL是最高层级的抽象,在它之下是Table API。本文我们会将例子中的SQL翻译成Table API来实现等价的功能。
Souce
# """create table source (# word STRING# ) with (# 'connector' = 'filesystem',# 'format' = 'csv',# 'path' = '{}'# )# """.format(input_path)
下面的SQL分为两部分:
- Table结构:该表只有一个名字为word,类型为string的字段。
- 连接器:是“文件系统”(filesystem)类型,格式是csv的文件。这样输入就会按csv格式进行解析。
SQL中的Table对应于Table API中的schema。它用于定义表的结构,比如有哪些类型的字段和主键等。
上述整个SQL整体对应于descriptor。即我们可以认为descriptor是表结构+连接器。
我们可以让不同的表和不同的连接器结合,形成不同的descriptor。这是一个组合关系,我们将在下面看到它们的组合方式。
schema
# define the source schemasource_schema = Schema.new_builder() \.column("word", DataTypes.STRING()) \.build()
new_builder()会返回一个Schema.Builder对象;
column(self, column_name: str, data_type: Union[str, DataType])方法用于声明该表存在哪些类型、哪些名字的字段,同时返回之前的Builder对象;
最后的build(self)方法返回Schema.Builder对象构造的Schema对象。
descriptor
# Create a source descriptorsource_descriptor= TableDescriptor.for_connector("filesystem") \.schema(source_schema) \.option('path', input_path) \.format("csv") \.build()
for_connector(connector: str)方法返回一个TableDescriptor.Builder对象;
schema(self, schema: Schema)将上面生成的source_schema 对象和descriptor关联;
option(self, key: Union[str, ConfigOption], value)用于指定一些参数,比如本例用于指定输入文件的路径;
format(self, format: Union[str, ‘FormatDescriptor’], format_option: ConfigOption[str] = None)用于指定内容的格式,这将指导怎么解析和入库;
build(self)方法返回TableDescriptor.Builder对象构造的TableDescriptor对象。
Sink
# """CREATE TABLE WordsCountTableSink (# `word` STRING,# `count` BIGINT,# PRIMARY KEY (`word`) NOT ENFORCED# ) WITH (# 'connector' = 'jdbc',# 'url' = 'jdbc:mysql://127.0.0.1:3306/words_count_db?useSSL=false',# 'table-name' = 'WordsCountTable',# 'driver'='com.mysql.jdbc.Driver',# 'username'='admin',# 'password'='pwd123'# );# """
schema
sink_schema = Schema.new_builder() \.column("word", DataTypes.STRING().not_null()) \.column("count", DataTypes.BIGINT()) \.primary_key("word") \.build()
大部分代码在之前已经解释过了。我们主要关注于区别点:
- primary_key(self, *column_names: str) 用于指定表的主键。
- 主键的类型需要使用调用not_null(),以表明其非空。
descriptor
# Create a sink descriptorsink_descriptor = TableDescriptor.for_connector("jdbc") \.schema(sink_schema) \.option("url", "jdbc:mysql://127.0.0.1:3306/words_count_db?useSSL=false") \.option("table-name", "WordsCountTable") \.option("driver", "com.mysql.jdbc.Driver") \.option("username", "admin") \.option("password", "pwd123") \.build()
这块代码主要是通过option来设置一些连接器相关的设置。可以看到这是用KV形式设计的,这样就可以让option方法有很大的灵活性以应对不同连接器千奇百怪的设置。
Execute
使用下面的代码将表创建出来,以供后续使用。
t_env.create_table("source", source_descriptor)
tab = t_env.from_path('source')
t_env.create_temporary_table("WordsCountTableSink", sink_descriptor)
# execute insert# """insert into WordsCountTableSink# select word, count(1) as `count`# from source# group by word# """
tab.group_by(col('word')) \.select(col('word'), lit(1).count) \.execute_insert("WordsCountTableSink") \.wait()
这儿需要介绍的就是lit。它用于生成一个表达式,诸如sum、max、avg和count等。
execute_insert(self, table_path_or_descriptor: Union[str, TableDescriptor], overwrite: bool = False)用于将之前的计算结果插入到Sink表中
完整代码
import argparse
import logging
import sysfrom pyflink.common import Configuration
from pyflink.table import (EnvironmentSettings, TableEnvironment, Schema)
from pyflink.table.types import DataTypes
from pyflink.table.table_descriptor import TableDescriptor
from pyflink.table.expressions import lit, coldef word_count(input_path):config = Configuration()# write all the data to one fileconfig.set_string('parallelism.default', '1')env_settings = EnvironmentSettings \.new_instance() \.in_batch_mode() \.with_configuration(config) \.build()t_env = TableEnvironment.create(env_settings)# """create table source (# word STRING# ) with (# 'connector' = 'filesystem',# 'format' = 'csv',# 'path' = '{}'# )# """# define the source schemasource_schema = Schema.new_builder() \.column("word", DataTypes.STRING()) \.build()# Create a source descriptorsource_descriptor = TableDescriptor.for_connector("filesystem") \.schema(source_schema) \.option('path', input_path) \.format("csv") \.build()t_env.create_table("source", source_descriptor)# """CREATE TABLE WordsCountTableSink (# `word` STRING,# `count` BIGINT,# PRIMARY KEY (`word`) NOT ENFORCED# ) WITH (# 'connector' = 'jdbc',# 'url' = 'jdbc:mysql://127.0.0.1:3306/words_count_db?useSSL=false',# 'table-name' = 'WordsCountTable',# 'driver'='com.mysql.jdbc.Driver',# 'username'='admin',# 'password'='pwd123'# );# """# define the sink schemasink_schema = Schema.new_builder() \.column("word", DataTypes.STRING().not_null()) \.column("count", DataTypes.BIGINT()) \.primary_key("word") \.build()# Create a sink descriptorsink_descriptor = TableDescriptor.for_connector("jdbc") \.schema(sink_schema) \.option("url", "jdbc:mysql://127.0.0.1:3306/words_count_db?useSSL=false") \.option("table-name", "WordsCountTable") \.option("driver", "com.mysql.jdbc.Driver") \.option("username", "admin") \.option("password", "pwd123") \.build()t_env.create_temporary_table("WordsCountTableSink", sink_descriptor)# execute insert# """insert into WordsCountTableSink# select word, count(1) as `count`# from source# group by word# """tab = t_env.from_path('source')tab.group_by(col('word')) \.select(col('word'), lit(1).count) \.execute_insert("WordsCountTableSink") \.wait()if __name__ == '__main__':logging.basicConfig(stream=sys.stdout, level=logging.INFO, format="%(message)s")parser = argparse.ArgumentParser()parser.add_argument('--input',dest='input',required=False,help='Input file to process.')argv = sys.argv[1:]known_args, _ = parser.parse_known_args(argv)word_count(known_args.input)
参考资料
- https://nightlies.apache.org/flink/flink-docs-master/zh/docs/concepts/overview/
- https://nightlies.apache.org/flink/flink-docs-release-1.17/api/python//reference/pyflink.table/descriptors.html