济南酷火网站建设seo工资多少
Set
概念
- Redis的set是一个不重复、无序并唯一的键值集合。(方便管理无序集合)
- 它支持交集、并集、差集等等
set和list区别
- List 可以存储重复元素,Set 只能存储非重复元素;
- List 是按照元素的先后顺序存储元素的,而 Set 则是无序方式存储元素的。
常用命令
'Set常用操作'
# 往集合key中存入元素,元素存在则忽略,若key不存在则新建
SADD key member [member ...]
# 从集合key中删除元素
SREM key member [member ...]
# 获取集合key中所有元素
SMEMBERS key
# 获取集合key中的元素个数
SCARD key# 判断member元素是否存在于集合key中
SISMEMBER key member# 从集合key中随机选出count个元素,元素不从key中删除
SRANDMEMBER key [count]
# 从集合key中随机选出count个元素,元素从key中删除
SPOP key [count]'Set运算操作'
# 交集运算
SINTER key [key ...]
# 将交集结果存入新集合destination中
SINTERSTORE destination key [key ...]# 并集运算
SUNION key [key ...]
# 将并集结果存入新集合destination中
SUNIONSTORE destination key [key ...]# 差集运算
SDIFF key [key ...]
# 将差集结果存入新集合destination中
SDIFFSTORE destination key [key ...]
内部实现
Set 类型的底层数据结构是由哈希表或整数集合实现的:
- 如果集合中的元素都是整数且元素个数小于 512 (默认值,set-maxintset-entries配置)个,Redis 会使用整数集合作为 Set 类型的底层数据结构;
- 如果集合中的元素不满足上面条件,则 Redis 使用哈希表作为 Set 类型的底层数据结构。
INTSET(整数集合)
- 集群元素都是整数,且元素数量不超过512个,就可以使用INTSET编码,INTSET排列比较紧凑,内存占用少,但是查询时需要二分查找。
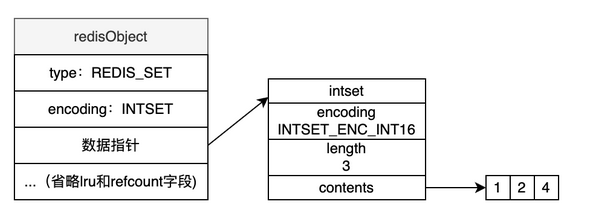
typedef struct intset{uint32_t encoding;uint32_t length; //元素数量int8_t contents[]; //保存元素的数组
}
- intset用来保存元素数组,默认是int16编码,后续如果插入更大的整数,才会升级到int32。但是升级也有弊端,整数数组的编码会变成与最大元素的类型一致,如果这时候元素数量非常多,就不节约内存了。
HASHTABLE(哈希表)
- 不满足INTSET条件,就需要使用HASHTABLE,能在O(1)时间找到一个元素是否存在

hashtable结构
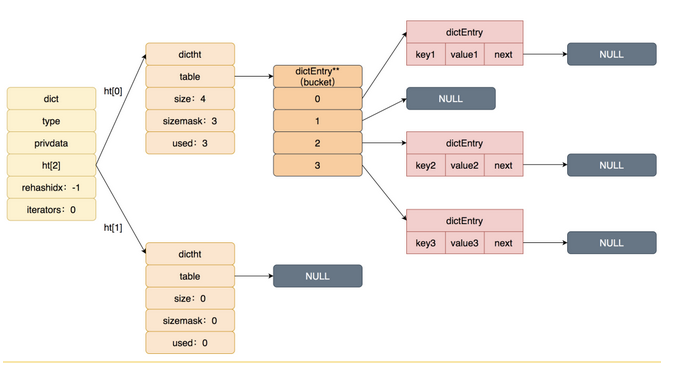
hashtable初始化为4- dictEntry是链表,是为了解决哈希冲突。
'dict底层结构'
typedef struct dict {dictType *type;void *private;dictht ht[2]; //包含了两个dictht结构,也就是两个hashtable.long rehashidx; //标志位,-1表示不再扩容,0代表rehashunsigned long iterators
}dict;'dictht底层结构'
typedef struct dictht {dictEntry **table; //指向实际hash存储(dictEntry看作数组,数组中都是一个个的bucket)unsigned long size; //哈希表大小,实际就行hidictEntry有多少元素空间unsigned long sizemask; //哈希表大小的掩码,总等于size-1unsigned long used; //表示已经使用的节点数量
}dictht;'dictEntry底层结构'
typedef struct dictEntry {void *key; // 键union {void *val;uint64_t u64;int64_t s64;double d;} v; // 值struct dictEntry *next; // 下一个节点
} dictEntry;
哈希算法原理
- 当向字典中添加一个元素时(假设此时 rehashidx = -1,也就是没有进行rehash),首先通过
hashFunction计算该元素的hash值,然后通过index=hash&sizemask。如果该元素对应的下标没有数据,则直接添加,否则采用链地址法添加到hash对应index元素的链表尾部。
渐进式rehash原理
渐进式rehash核心:定时迁移+顺带迁移
-
为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表
-
将rehashindex的值设置为0,表示rehash工作正式开始
-
在rehash期间,每次对字典执行增删改查操作是,程序除了执行指定的操作以外,还会顺带将ht[0]哈希表在rehashindex索引上的所有键值对rehash到ht[1],当rehash工作完成以后,rehashindex的值+1
-
随着字典操作的不断执行,最终会在某一时间段上ht[0]的所有键值对都会被rehash到ht[1],这时将rehashindex的值设置为-1,表示rehash操作结束
-
渐进式rehash采用的是一种分而治之的方式,将rehash的操作分摊在每一个的访问中,避免集中式rehash而带来的庞大计算量。
注意:
- 在渐进式rehash的过程,如果有增删改查操作时,如果index大于rehashindex,访问ht[0],否则访问ht[1]
- 新表的大小为第一个大于等于原表2倍used的2次方幂。
- 移动完一个index里面的entry list,就把rehashIndex++。
- 假设现在需要迁移table[0]上的某一个数据,迁移的是bucket,该bucket上的整条链表上的元素全部迁移过去。
问题
多线程问题:rehashidx = 9, 线程1:在对idx10的list进行写操作。线程2:在rehash idx10的list会不会丢失数据。还是说redis里面也有锁机制。
- Redis的多线程部分只是用来处理网络数据的读写和协议分析(网络处理是瓶颈),对于redis的读写命令,依然是单线程处理(因为单线程实现简单,而且不需要考虑线程安全问题)
扩容时机
- 负载因子k=ht[0].used/ht[0].size 使用空间和总空间的大小比例
- k >= 1时,空间已经紧张,越来越多的数据无法在O(1)时间复杂度找到,还需要遍历一次链表,如果此时服务器没有执行BGSAVE或BGREWRITEAOF这两个复制命令,就会发生扩容。
- k > 5,此时即使有复制命令进行,也要进行Rehash扩容
注意:如果进程正在执行BGSAVE或BGREWRITEAOF这两个复制命令,就会创建新的子进程,此时如果进行扩展哈希表,那么相当于往父进程写入数据,同时会导致子进程进行复制操作。
缩容
- Redis使用负载因子控制缩容,当负载因此小于0.1,即负载率小于10%,此时进行缩容,信标大小为第一个大于等于原表used的2次方幂。
应用场景
- Set 类型比较适合用来
数据去重和保障数据的唯一性,还可以用来统计多个集合的交集、错集和并集等
1. 点赞
- Set 类型可以保证一个用户只能点一个赞
# uid:1 用户对文章 article:1 点赞
> SADD article:1 uid:1
(integer) 1
# uid:2 用户对文章 article:1 点赞
> SADD article:1 uid:2
(integer) 1
# uid:3 用户对文章 article:1 点赞
> SADD article:1 uid:3
(integer) 1
2. 共同关注
- Set 类型支持交集运算,所以可以用来计算共同关注的好友、公众号等。
- key 可以是用户id,value 则是已关注的公众号的id。
# uid:1 用户关注公众号 id 为 5、6、7、8、9
> SADD uid:1 5 6 7 8 9
(integer) 5
# uid:2 用户关注公众号 id 为 7、8、9、10、11
> SADD uid:2 7 8 9 10 11
(integer) 5# 获取共同关注
> SINTER uid:1 uid:2
1) "7"
2) "8"
3) "9"
'给 uid:2 推荐 uid:1 关注的公众号:'
> SDIFF uid:1 uid:2
1) "5"
2) "6"
3. 抽奖活动
- Set 类型因为有去重功能,可以保证同一个用户不会中奖两次。
>SADD lucky Tom Jerry John Sean Marry Lindy Sary Mark
(integer) 5'重复抽奖'
# 抽取 1 个一等奖:
> SRANDMEMBER lucky 1
1) "Tom"
# 抽取 2 个二等奖:
> SRANDMEMBER lucky 2
1) "Mark"
2) "Jerry"
# 抽取 3 个三等奖:
> SRANDMEMBER lucky 3
1) "Sary"
2) "Tom"
3) "Jerry"'不重复抽奖'
# 抽取一等奖1个
> SPOP lucky 1
1) "Sary"
# 抽取二等奖2个
> SPOP lucky 2
1) "Jerry"
2) "Mark"
# 抽取三等奖3个
> SPOP lucky 3
1) "John"
2) "Sean"
3) "Lindy"
HSet
- HSET是HASH字典,可以存储多个field(集合) - value映射关系,但是都为string的hash表,存储在Redis的内存中。适用于O(1)的时间查找
底层原理
- HSET底层有俩种编码结构:压缩列表和HASHTABLE
- 当HSET对象保存的所有值和键的长度都小于64字节,并且HSET对象元素个数少于512个时,使用压缩列表。
- 当上述两个条件任何一条不满足时,编码结构就用HASHTABLE。
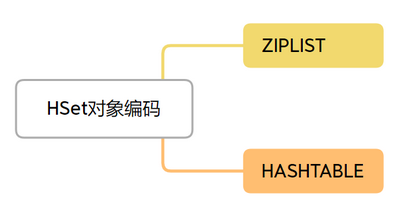
压缩列表 - 数据量较小时将数据紧凑排列,对应到HSET,就是将filed-value当作entry放入压缩列表。
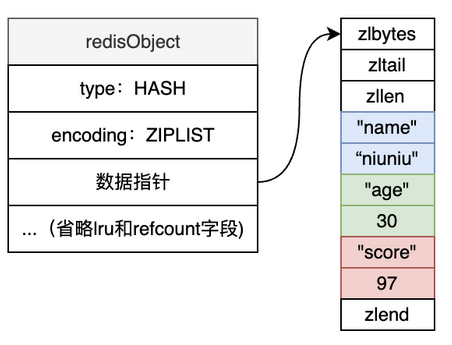
HASHTABLE
- HASHTABLE在之前无序集合Set中也有应用,和Set区别,在于,Set中的value始终为NULL(因为Set中只存储一个值),但是在HSET中,是有对应值的。