wordpress 快速编辑武汉seo群
目录
- 前言
- 引言
- 总体设计
- 系统整体结构图
- 系统流程图
- 运行环境
- 模块实现
- 1. 数据预处理
- 2. 模型构建
- 1)定义模型结构
- 2)优化损失函数
- 3. 模型训练及保存
- 1)模型训练
- 2)模型保存
- 3)映射保存
- 相关其它博客
- 工程源代码下载
- 其它资料下载

前言
博主前段时间发布了一篇有关方言识别和分类模型训练的博客,在读者的反馈中发现许多小伙伴对方言的辨识和分类表现出浓厚兴趣。鉴于此,博主决定专门撰写一篇关于方言分类的博客,以满足读者对这一主题的进一步了解和探索的需求。上篇博客可参考:
《基于Python+WaveNet+CTC+Tensorflow智能语音识别与方言分类—深度学习算法应用(含全部工程源码)》
引言
本项目以科大讯飞提供的数据集为基础,通过特征筛选和提取的过程,选用WaveNet模型进行训练。旨在通过语音的梅尔频率倒谱系数(MFCC)特征,建立方言和相应类别之间的映射关系,解决方言分类问题。
首先,项目从科大讯飞提供的数据集中进行了特征筛选和提取。包括对语音信号的分析,提取出最能代表语音特征的MFCC,为模型训练提供有力支持。
其次,选择了WaveNet模型进行训练。WaveNet模型是一种序列生成器,用于语音建模,在语音合成的声学建模中,可以直接学习采样值序列的映射,通过先前的信号序列预测下一个时刻点值的深度神经网络模型,具有自回归的特点。
在训练过程中,利用语音的MFCC特征,建立了方言和相应类别之间的映射关系。这样,模型能够识别和分类输入语音的方言,并将其划分到相应的类别中。
最终,通过这个项目,实现了方言分类问题的解决方案。这对于语音识别、语音助手等领域具有实际应用的潜力,也有助于保护和传承各地区的语言文化。
总体设计
本部分包括系统整体结构图和系统流程图。
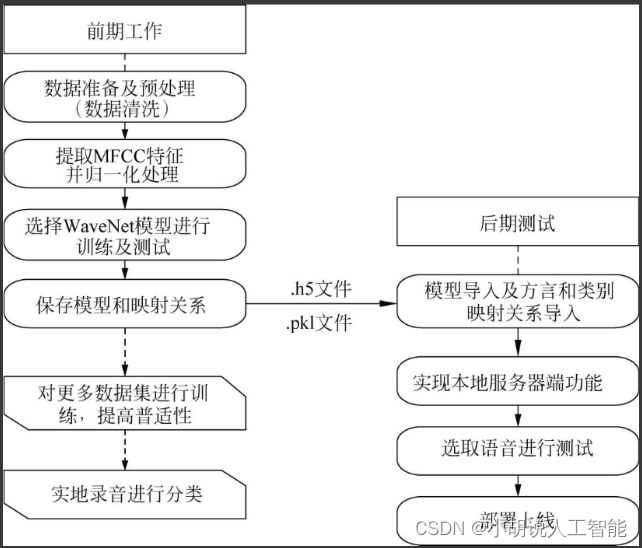
系统整体结构图
系统整体结构如图所示。
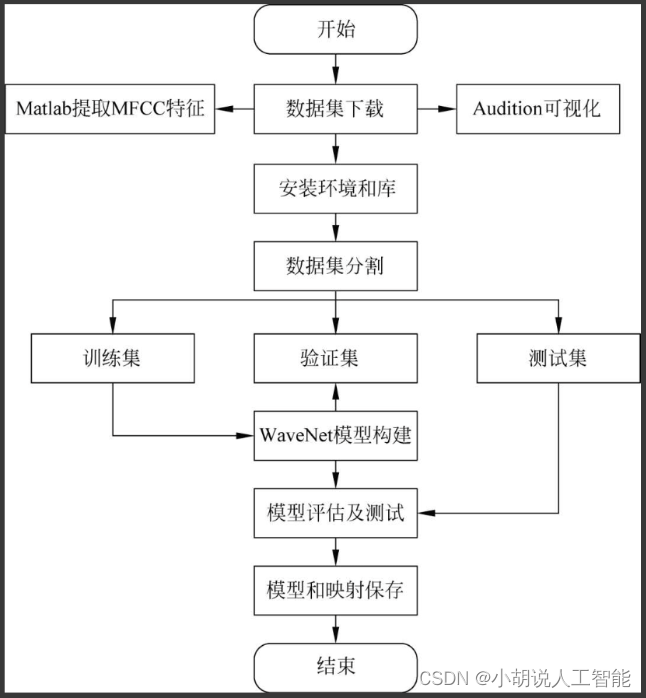
系统流程图
系统流程如图所示。
运行环境
本部分包括Python环境、TensorFlow环境、JupyterNotebook环境、PyCharm环境。
详见博客。
模块实现
本项目包括4个模块:数据预处理、模型构建、模型训练及保存、模型生成。下面分别给出各模块的功能介绍及相关代码。
1. 数据预处理
本部分包括数据介绍、数据测试和数据处理。
详见博客。
2. 模型构建
数据加载进模型之后,需要定义模型结构并优化损失函数。
1)定义模型结构
卷积层使用带洞因果卷积,卷积后的感知范围与卷积层数呈现指数级增长关系。WaveNet模型是一种序列生成器,用于语音建模,在语音合成的声学建模中,可以直接学习采样值序列的映射,通过先前的信号序列预测下一个时刻点值的深度神经网络模型,具有自回归的特点。相关代码如下:
epochs = 10#迭代次数
num_blocks = 3
filters = 128
#层叠
drop_rate = 0.25
#防止过拟合
X = Input(shape=(None, mfcc_dim,), dtype='float32')
#一维卷积
def conv1d(inputs, filters, kernel_size, dilation_rate):return Conv1D(filters=filters, kernel_size=kernel_size, strides=1, padding='causal', activation=None, dilation_rate=dilation_rate)(inputs)
#步长strides为1
#参数padding=’causal’即为采用因果卷积
def batchnorm(inputs):#批规范化函数return BatchNormalization()(inputs)#BN算法,每一层后增加了归一化层
def activation(inputs, activation):
#定义激活函数,实现神经元输入/输出之间的非线性化return Activation(activation)(inputs)
def res_block(inputs, filters, kernel_size, dilation_rate):
#残差块hf = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'tanh')hg = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'sigmoid')h0 = Multiply()([hf, hg])ha = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')hs = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')return Add()([ha, inputs]), hs
2)优化损失函数
通过Adam()方法进行梯度下降,动态调整每个参数的学习率,进行模型参数优化。
(“loss='categorical_crossentropy'”)。
#定义损失函数和优化器
optimizer = Adam(lr=0.01, clipnorm=5)
#Adam利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率
model = Model(inputs=X, outputs=Y)
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
#模块编译,采用交叉熵损失函数
lr_decay = ReduceLROnPlateau(monitor='loss', factor=0.2, patience=1, min_lr=0.000)
#ReduceLROnPlateau基于训练过程中的某些测量值对学习率进行动态下降
history = model.fit_generator( #使用fit_generator函数来进行训练generator=batch_generator(X_train, Y_train), steps_per_epoch=len(X_train) // batch_size,epochs=epochs, validation_data=batch_generator(X_dev, Y_dev), validation_steps=len(X_dev) // batch_size,
callbacks=[checkpointer, lr_decay])
3. 模型训练及保存
本部分包括模型训练、模型保存和映射保存。
1)模型训练
模型相关代码如下:
epochs = 10 #参数设置
num_blocks = 3
filters = 128
drop_rate = 0.25
X = Input(shape=(None, mfcc_dim,), dtype='float32') #输入数据
def conv1d(inputs, filters, kernel_size, dilation_rate): #卷积return Conv1D(filters=filters, kernel_size=kernel_size, strides=1, padding='causal', activation=None, dilation_rate=dilation_rate)(inputs)
def batchnorm(inputs): #批标准化return BatchNormalization()(inputs)
def activation(inputs, activation): #激活定义return Activation(activation)(inputs)
def res_block(inputs, filters, kernel_size, dilation_rate): #残差层hf = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'tanh')hg = activation(batchnorm(conv1d(inputs, filters, kernel_size, dilation_rate)), 'sigmoid')h0 = Multiply()([hf, hg])ha = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')hs = activation(batchnorm(conv1d(h0, filters, 1, 1)), 'tanh')return Add()([ha, inputs]), hs
#模型训练
h0 = activation(batchnorm(conv1d(X, filters, 1, 1)), 'tanh')
shortcut = []
for i in range(num_blocks):for r in [1, 2, 4, 8, 16]:h0, s = res_block(h0, filters, 7, r)shortcut.append(s) #直连
h1 = activation(Add()(shortcut), 'relu')
h1 = activation(batchnorm(conv1d(h1, filters, 1, 1)), 'relu')
#参数batch_size, seq_len, filters
h1 = batchnorm(conv1d(h1, num_class, 1, 1))
#参数batch_size, seq_len, num_class
#池化
h1 = GlobalMaxPooling1D()(h1) #参数batch_size,num_class
Y = activation(h1, 'softmax')
h1 = activation(Add()(shortcut), 'relu')
h1 = activation(batchnorm(conv1d(h1, filters, 1, 1)), 'relu')
#参数batch_size, seq_len, filters
h1 = batchnorm(conv1d(h1, num_class, 1, 1))
#参数batch_size, seq_len, num_class
h1 = GlobalMaxPooling1D()(h1) #参数batch_size, num_class
Y = activation(h1, 'softmax')
optimizer = Adam(lr=0.01, clipnorm=5)
model = Model(inputs=X, outputs=Y) #模型
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy'])
checkpointer = ModelCheckpoint(filepath='fangyan.h5', verbose=0)
lr_decay = ReduceLROnPlateau(monitor='loss', factor=0.2, patience=1, min_lr=0.000)
history = model.fit_generator( #训练generator=batch_generator(X_train, Y_train), steps_per_epoch=len(X_train) // batch_size,epochs=epochs, validation_data=batch_generator(X_dev, Y_dev), validation_steps=len(X_dev) // batch_size, callbacks=[checkpointer, lr_decay])
训练输出结果如图所示。

通过观察训练集和测试集的损失函数、准确率大小来评估模型的训练程度,进行模型训练的进一步决策。训练集和测试集的损失函数(或准确率)不变且基本相等为模型训练的最佳状态。
可以将训练过程中保存的准确率和损失函数以图的形式表现出来,方便观察。
import matplotlib.pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
#解决保存图像中负号"-"显示为方块的问题
#指定默认字体
2)模型保存
为了能够在本地服务器调用模型,将模型保存为.h5格式的文件,Keras使用HDF5文件系统来保存模型,在使用过程中,需要Keras提供好的模型导入功能,即可加载模型。h5文件是层次结构。在数据集中还有元数据,即metadata对于每一个dataset而言,除了数据本身之外,这个数据集还有很多的属性信息。HDF5同时支持存储数据集对应的属性信息,所有属性信息的集合叫metadata。
相关代码如下:
model = Model(inputs=X, outputs=Y) #模型
model.compile(loss='categorical_crossentropy', optimizer=optimizer, metrics=['accuracy']) #参数输出
checkpointer = ModelCheckpoint(filepath='fangyan.h5', verbose=0)
#模型的保存,保存路径是filepath
3)映射保存
保存方言与类别之间的映射关系,将映射文件保存为.pkl格式,以便调用,pkl是Python保存文件的一种格式,该存储方式可以将Python项目过程中用到的一些临时变量或者需要提取、暂存的字符串、列表、字典等数据保存,使用pickle模块可将任意一个Python对象转换成系统字节。
相关代码如下:
with open('resources.pkl', 'wb') as fw:pickle.dump([class2id, id2class, mfcc_mean, mfcc_std], fw)
相关其它博客
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(一)
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(二)
基于Python+WaveNet+MFCC+Tensorflow智能方言分类—深度学习算法应用(含全部工程源码)(四)
工程源代码下载
详见本人博客资源下载页
其它资料下载
如果大家想继续了解人工智能相关学习路线和知识体系,欢迎大家翻阅我的另外一篇博客《重磅 | 完备的人工智能AI 学习——基础知识学习路线,所有资料免关注免套路直接网盘下载》
这篇博客参考了Github知名开源平台,AI技术平台以及相关领域专家:Datawhale,ApacheCN,AI有道和黄海广博士等约有近100G相关资料,希望能帮助到所有小伙伴们。