池州哪家做网站深圳网站优化推广
arxiv 2023 08的论文
1 intro
1.1 人类流动性的独特性
- 人类流动性的独特特性在于其固有的规律性、随机性以及复杂的时空依赖性
- ——>准确预测人们的行踪变得困难
- 近期的研究利用深度学习模型的时空建模能力实现了更好的预测性能
- 但准确性仍然不足,且产生的结果不能直接完全解释
1.2 本文

- LMM+位置预测
- 提出了一个名为LLM-Mob的框架
- 将流动性数据组织成历史停留和上下文停留,以解释人们移动中的长期和短期依赖性
- 利用目标停留的时间信息进行时间感知预测
- 设计了有效的prompt策略来帮助LLM理解流动性数据,最大化它们的推理能力,使预测结果的解释成为可能。
- 提出了一个名为LLM-Mob的框架
2 Preliminary
2.1 术语和符号
- 用户的轨迹被表示为一系列停留,一个停留被表示为 (st, dow, dur, pid)
- st 表示停留开始的时间,dow 表示星期几,dur 表示停留的持续时间,pid 表示停留发生地点的唯一标识符。
- 一个停留的例子可以是 (17:30, 星期二, 35分钟, 地点1),表示用户在星期二的17:30到18:05期间停留在地点1。
2.2 问题定义(next-location prediction)
- 给定一个用户到时间 n 为止的停留序列 S = (Sn−Q+1, ..., Sn),目标是预测用户在下一个时间步骤将要访问的下一个位置/地点(即 pidn+1)
3 模型
3.1 数据整体

3.2 数据格式化

3.3 任务独特的prompt

4 实验
4.1 数据集和预处理
- Geolife、纽约Foursquare 数据集(FSQ-NYC)
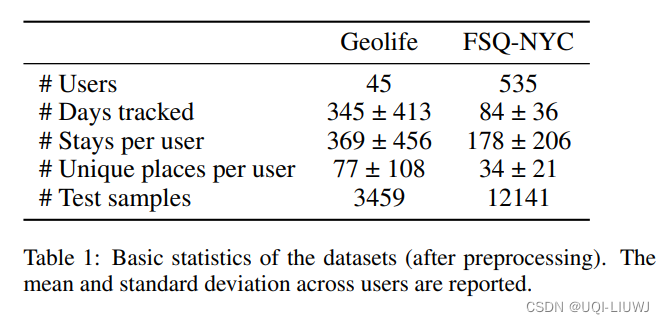
- 预处理步骤,包括过滤记录很少的用户、处理原始轨迹成停留点,将数据集分为训练和测试集
4.2 实验细节
- 使用的特定 LLM 是 GPT-3.51( gpt-3.5-turbo-0613)
- 将温度设置为 0 以避免输出中的随机性
- 史停留点 M 的长度和上下文停留点 N 的长度分别设置为 40 和 5
4.3 评估指标
- 准确率(Accuracy)。
- 预测按照成为下一个位置的概率降序排列,Acc@k 衡量真实位置出现在前k个预测中的比例。
- 报告了 Acc@1、Acc@5 和 Acc@10 以进行比较
- 加权F1分数(Weighted F1)
- 个人访问位置的次数高度不平衡,一些位置出现的频率比其他位置更高。
- 使用按访问次数加权的 F1 分数来强调模型在更重要位置的性能
- nDCG@k
- 归一化折扣累积增益(normalized discounted cumulative gain,简称 nDCG,以排名位置k为基准)
- 通过折扣累积增益(DCG)与理想折扣累积增益(IDCG)之比来衡量预测向量的质量

- rj 表示位置j的相关性值。
- 在位置预测的上下文中,rj∈{0,1},并且当且仅当排名预测向量中的第j个项目对应于真实的下一个位置时,rj=1
- rj 表示位置j的相关性值。
4.4 实验结果



5 讨论
5.1 LLM-Mob 为什么表现得如此出色?
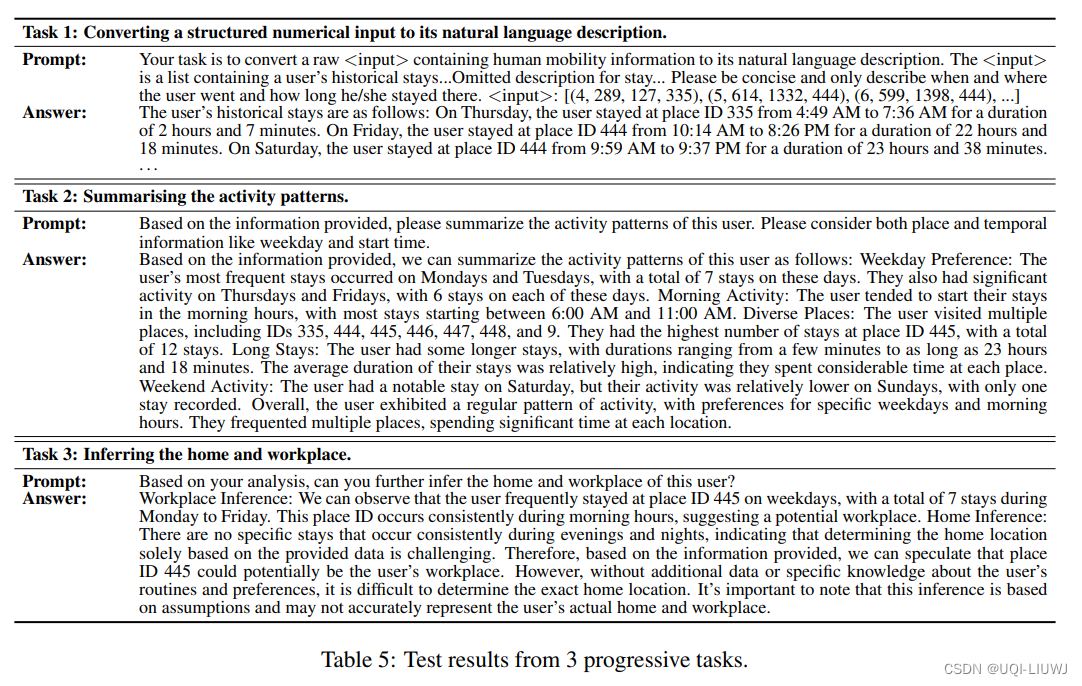
- 论文测试了 LLM 在三个逐步任务上的性能,以展示论文认为对成功预测人类移动性至关重要的其能力的不同方面
- 表 5 中展示的结果显示 LLM 在所有三个任务中都做得非常好
- 生成数字和结构化输入的自然语言描述
- 总结用户的活动模式
- 以及对用户的家庭和工作场所进行推断
- 这显示了三个主要能力:
- 不仅能理解自然语言,还能理解如代表轨迹的数字列表这样的结构化数字输入
- 总结历史移动性/活动模式的能力,以便模型能有效地利用过去的信息来预测未来情况
- 强大的推理能力,意味着模型可以像人类一样“思考”并做出合理的推断
- 除了 LLM 本身的能力外,LLM-Mob 的成功还在于数据的有效格式化和实用的提示工程,其中提示已通过迭代测试仔细设计和改进
5.2 限制
- 效率问题。
- 对每个测试样本独立调用 OpenAI API,这种做法效率低下,难以应用于大规模预测
- 幻觉问题
- 这是 LLM 面临的一个常见问题。
- 如表 4 中标记为蓝色的声明所示,模型声明地点 1 是一家餐厅,这是虚构的,可能会误导用户
- 来自专有 LLM 的限制
- 首先,调用 OpenAI API 需要花费金钱,当数据量大时,成本可能会很高
- 此外,OpenAI 不断更新 GPT 模型系列,导致最新模型的性能漂移
- 在旧模型上表现良好的提示可能在新模型上不起作用,需要在提示工程上做额外工作