做脚本从网站引流最近的疫情情况最新消息
- SVG 生成系列论文(一) 和 SVG 生成系列论文(二) 分别介绍了 StarVector 的大致背景和详细的模型细节。
- SVG 生成系列论文(三)和 SVG 生成系列论文(四)则分别介绍实验、数据集和数据增强细节。
- SVG 生成系列论文(五)介绍了从光栅图像(如 PNG、JPG 格式)转换为矢量图形(如 SVG、EPS 格式)的关键技术-像素预过滤(pixel prefiltering), Diffvg 这篇论文也是 SVG 生成与编辑领域中 “基于优化”方法的开创性研究。
- SVG 生成系列论文(六) 和 SVG 生成系列论文(七) 简要介绍了 IconShop 的背景、应用和部分细节。
- SVG 生成系列论文(八)则介绍了模型架构和具体的训练技巧。
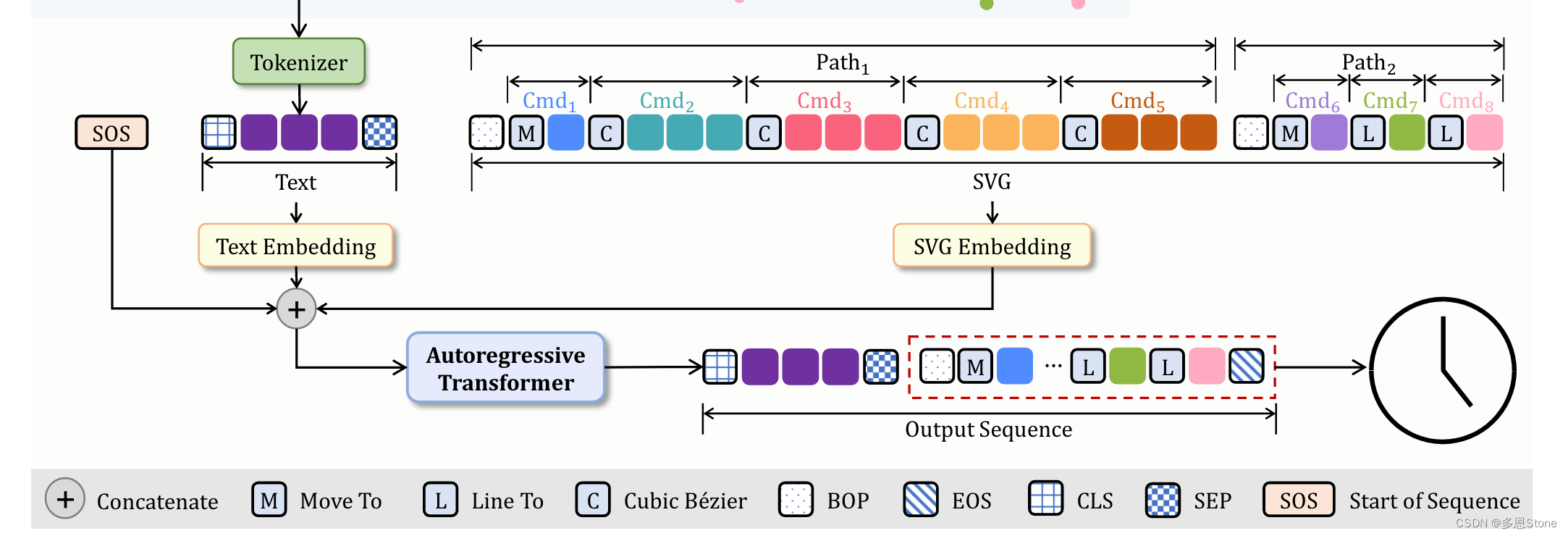
本文将详细拆解 IconShop(论文原文以及代码🔗)的模型结构和对应开源代码。上篇有提到过模型架构如下所示,本篇则从代码的逻辑进行解释,主要是 /path/to/IconShop/model/decoder.py 中的 sample 以及 forward 两个函数。
模型架构
架构整体分为 4 个部分:SVG 图标嵌入(SVG Icon Embedding),文本嵌入(Text Embedding),输入准备和输出生成。
sample 函数
在原项目中,调用模型推理是从 sample_pixels = sketch_decoder.sample(n_samples=BS, text=tokenized_text) 中进行的,因此重点解读这部分代码。
- 输入部分:
self: 指代调用该方法的对象,意味着可以访问类的属性和方法。
n_samples: 要生成的样本数量,这里是 batchsize。
text: 输入的文本数据,用于条件生成。形状为[batch_size, text_len],其中text_len是文本序列的长度,默认是 50。
pixel_seq: 已有的像素序列,初始化为None,形状为[batch_size, max_len]。
xy_seq: 已有的坐标序列,初始化为None,形状为[batch_size, max_len, 2]。
def sample(self, n_samples, text, pixel_seq=None, xy_seq=None):""" sample from distribution (top-k, top-p) """pix_samples = []xy_samples = []# latent_ext_samples = []top_k = 0top_p = 0.5
- 初始化:
定义了空列表pix_samples和xy_samples以存储采样的像素和坐标序列。
同时定义了 top_k 和 top_p 作为采样策略的参数,默认使用“Top-P”策略(top_p=0.5),不使用“Top-K”。了解更多,可参见大模型推理常见采样策略(Top-k, Top-p)
# Mapping from pixel index to xy coordiantepixel2xy = {}x=np.linspace(0, BBOX-1, BBOX)y=np.linspace(0, BBOX-1, BBOX)xx,yy=np.meshgrid(x,y)xy_grid = (np.array((xx.ravel(), yy.ravel())).T).astype(int)for pixel, xy in enumerate(xy_grid):pixel2xy[pixel] = xy+COORD_PAD+SVG_END
-
像素到坐标映射:
创建一个从像素索引到坐标(x, y)的映射。这里假设有一个固定大小的边界框(BBOX=200),通过网格生成所有可能的坐标组合,并将这些坐标与像素索引关联起来。其中,COORD_PAD= NUM_END_TOKEN + NUM_MASK_AND_EOM(NUM_END_TOKEN = 3,NUM_MASK_AND_EOM = 2),SVG_END= 1 -
处理文本输入: 确保文本序列的长度不超过预设的最大长度
self.text_len -
循环采样:
- for k in range(
text.shape[1] + pixlen, self.total_seq_len): 是开始对文本之后的 SVG 序列进行采样(预测)。 - 初始化或更新像素
pixel_seq和坐标序列xy_seq的长度。 - 使用模型的
forward方法计算当前状态下下一个token的概率分布。 - 应用“Top-K”和“Top-P”过滤策略(
top_k_top_p_filtering)到概率分布上,仅保留最可能的token。 - 从过滤后的分布中多分类采样得到下一个像素值。
- 将采样的像素索引转换为实际的坐标。其中
PIX_PAD= NUM_END_TOKEN + NUM_MASK_AND_EOM,SVG_END= 1
- 序列更新和早停条件:
- 将生成的像素和坐标序列加入现有序列中。
- 检查生成是否完成(例如生成到结束符),如果有完成的样本则记录并移除。
- 如果所有样本都生成完毕,提前停止循环。
- 返回结果:
返回生成的坐标序列xy_samples。
# Sample per tokentext = text[:, :self.text_len]pixlen = 0 if pixel_seq is None else pixel_seq.shape[1]for k in range(text.shape[1] + pixlen, self.total_seq_len):if k == text.shape[1]:pixel_seq = [None] * n_samplesxy_seq = [None, None] * n_samples# pass through modelwith torch.no_grad():p_pred = self.forward(pixel_seq, xy_seq, None, text)p_logits = p_pred[:, -1, :]next_pixels = []# Top-p sampling of next pixelfor logit in p_logits: filtered_logits = top_k_top_p_filtering(logit, top_k=top_k, top_p=top_p)next_pixel = torch.multinomial(F.softmax(filtered_logits, dim=-1), 1)next_pixel -= self.num_text_tokennext_pixels.append(next_pixel.item())# Convert pixel index to xy coordinatenext_xys = []for pixel in next_pixels:if pixel >= PIX_PAD+SVG_END:xy = pixel2xy[pixel-PIX_PAD-SVG_END]else:xy = np.array([pixel, pixel]).astype(int)next_xys.append(xy)next_xys = np.vstack(next_xys) # [BS, 2]next_pixels = np.vstack(next_pixels) # [BS, 1]# Add next tokensnextp_seq = torch.LongTensor(next_pixels).view(len(next_pixels), 1).cuda()nextxy_seq = torch.LongTensor(next_xys).unsqueeze(1).cuda()if pixel_seq[0] is None:pixel_seq = nextp_seqxy_seq = nextxy_seqelse:pixel_seq = torch.cat([pixel_seq, nextp_seq], 1)xy_seq = torch.cat([xy_seq, nextxy_seq], 1)# Early stoppingdone_idx = np.where(next_pixels==0)[0]if len(done_idx) > 0:done_pixs = pixel_seq[done_idx] done_xys = xy_seq[done_idx]# done_ext = latent_ext[done_idx]# for pix, xy, ext in zip(done_pixs, done_xys, done_ext):for pix, xy in zip(done_pixs, done_xys):pix = pix.detach().cpu().numpy()xy = xy.detach().cpu().numpy()pix_samples.append(pix)xy_samples.append(xy)# latent_ext_samples.append(ext.unsqueeze(0))left_idx = np.where(next_pixels!=0)[0]if len(left_idx) == 0:break # no more jobs to doelse:pixel_seq = pixel_seq[left_idx]xy_seq = xy_seq[left_idx]text = text[left_idx]# return pix_samples, latent_ext_samplesreturn xy_samplesforward
这个函数的主要作用是前向传播(或称推理),根据输入的像素序列、坐标序列、掩码和文本,计算模型的输出。具体过程如下:
- 准备输入:
- 如果需要计算损失
return_loss,则去掉最后一个时间步的数据。 - 计算上下文序列的长度
c_seqlen,包括文本和像素序列的长度。
def forward(self, pix, xy, mask, text, return_loss=False):'''pix.shape [batch_size, max_len]xy.shape [batch_size, max_len, 2]mask.shape [batch_size, max_len]text.shape [batch_size, text_len]'''pixel_v = pix[:, :-1] if return_loss else pixxy_v = xy[:, :-1] if return_loss else xypixel_mask = mask[:, :-1] if return_loss else maskc_bs, c_seqlen, device = text.shape[0], text.shape[1], text.deviceif pixel_v[0] is not None:c_seqlen += pixel_v.shape[1]
- 嵌入计算:
对输入的文本进行嵌入计算text_emb。
如果有像素和坐标序列,则分别对它们进行嵌入计算(coord_embed_x, pixel_embed),并与文本嵌入拼接。
# Context embedding valuescontext_embedding = torch.zeros((1, c_bs, self.embed_dim)).to(device) # [1, bs, dim]# tokens.shape [batch_size, text_len, emb_dim]tokens = self.text_emb(text)# Data input embeddingif pixel_v[0] is not None:# coord_embed.shape [batch_size, max_len-1, emb_dim]# pixel_embed.shape [batch_size, max_len-1, emb_dim] coord_embed = self.coord_embed_x(xy_v[...,0]) + self.coord_embed_y(xy_v[...,1]) # [bs, vlen, dim]pixel_embed = self.pixel_embed(pixel_v)embed_inputs = pixel_embed + coord_embed# tokens.shape [batch_size, text_len+max_len-1, emb_dim]tokens = torch.cat((tokens, embed_inputs), dim=1)
- 位置编码和掩码计算:
计算位置编码,并与嵌入后的输入序列拼接。
生成用于Transformer的掩码nopeak_mask,确保模型不会看到未来的时间步。
如果有像素掩码pixel_mask,则将其扩展到与嵌入序列匹配的形状。
# nopeak_mask.shape [c_seqlen+1, c_seqlen+1]nopeak_mask = torch.nn.Transformer.generate_square_subsequent_mask(c_seqlen+1).to(device) # masked with -infif pixel_mask is not None:# pixel_mask.shape [batch_size, text_len+max_len]pixel_mask = torch.cat([(torch.zeros([c_bs, context_embedding.shape[0]+self.text_len])==1).to(device), pixel_mask], axis=1) - Transformer解码:
将处理后的输入序列送入Transformer解码器,得到输出序列。
decoder_out = self.decoder(tgt=decoder_inputs, memory=memory_encode, memory_key_padding_mask=None,tgt_mask=nopeak_mask, tgt_key_padding_mask=pixel_mask)
- 计算logits和损失:
通过全连接层logit_fc计算输出的logits。
如果需要计算损失,则分别计算文本和像素的损失cross_entropy,并返回总损失。
如果不需要计算损失,则直接返回logits。
# Logits fclogits = self.logit_fc(decoder_out) # [seqlen, bs, dim] logits = logits.transpose(1,0) # [bs, textlen+seqlen, total_token] logits_mask = self.logits_mask[:, :c_seqlen+1]max_neg_value = -torch.finfo(logits.dtype).maxlogits.masked_fill_(logits_mask, max_neg_value)if return_loss:logits = rearrange(logits, 'b n c -> b c n')text_logits = logits[:, :, :self.text_len]pix_logits = logits[:, :, self.text_len:]pix_logits = rearrange(pix_logits, 'b c n -> (b n) c')pix_mask = ~mask.reshape(-1)pix_target = pix.reshape(-1) + self.num_text_tokentext_loss = F.cross_entropy(text_logits, text)pix_loss = F.cross_entropy(pix_logits[pix_mask], pix_target[pix_mask], ignore_index=MASK+self.num_text_token)loss = (text_loss + self.loss_img_weight * pix_loss) / (self.loss_img_weight + 1)return loss, pix_loss, text_losselse:return logits