站内推广和站外推广的区别ip反查域名网站
由于Selenium流行已久,现在稍微有点反爬的网站都会对selenium和webdriver进行识别,网站只需要在前端js添加一下判断脚本,很容易就可以判断出是真人访问还是webdriver。虽然也可以通过中间代理的方式进行js注入屏蔽webdriver检测,但是webdriver对浏览器的模拟操作(输入、点击等等)都会留下webdriver的标记,同样会被识别出来,要绕过这种检测,只有重新编译webdriver,麻烦自不必说,难度不是一般大。
pyppeteer简介
由于Selenium具有这些严重的缺点。pyperteer成为了爬虫界的又一新星。
相比于selenium具有以下特点:
异步加载
速度快
具备有界面/无界面模式
伪装性更强不易被识别为机器人
同时可以伪装手机平板等终端
------------------->>>>
虽然支持的浏览器比较单一,但在安装配置的便利性和运行效率方面都要远胜selenium。
pyppeteer无疑为防爬墙撕开了一道大口子,针对selenium的淘宝、美团、文书网等网站,目前可通过该库使用selenium的思路继续突破,毫不费劲。
Pyppeteer是一个基于Python的浏览器自动化库,它使用了Puppeteer(谷歌开发的Node.js工具)的思路,通过JavaScript代码操纵Chrome浏览器完成数据爬取和Web程序自动测试等任务。Pyppeteer使用Python异步协程库asyncio,可以整合Scrapy进行分布式爬虫。
在Pyppeteer中,实际上背后有一个类似Chrome浏览器的Chromium浏览器在执行一些动作进行网页渲染。Chromium是谷歌为了研发Chrome而启动的项目,是完全开源的。二者基于相同的源代码构建,功能上基本没有太大区别。

总之,Pyppeteer依赖于Chromium这个浏览器来运行的。
pyppeteer安装及配置
由于 Pyppeteer 采用了 Python 的 async 机制,所以其运行要求的 Python 版本为 3.5 及以上。
第一步:在python中安装pyppeteer第三库
安装方式很简单,命令行 pip 安装即可。
pip3 install pyppeteer或者直接在IDE中进行安装:
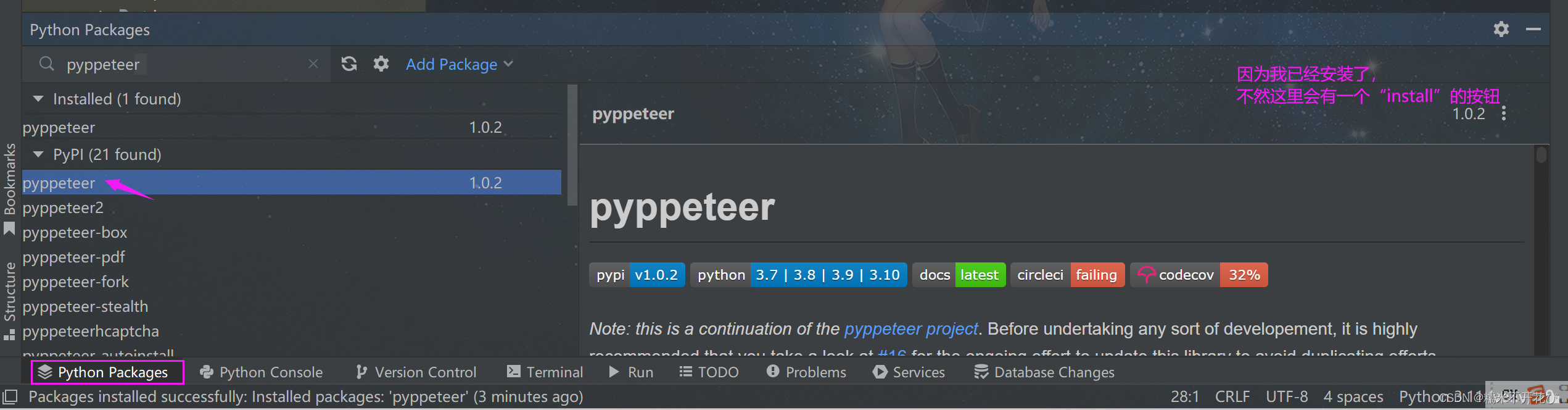
第二步:输入以下两行代码
import pyppeteer
print(pyppeteer.chromium_downloader.chromiumExecutable)记住打印结果中圈出的数字,这是chromium的borwser驱动版本号
 第三步:去下载对应版本的chromium的borwser
第三步:去下载对应版本的chromium的borwser
在这里使用的是淘宝镜像中的chromium
进入这个网址:CNPM Binaries Mirror

选择对应系统和对应的版本(我这里是windows系统,选择了我系统默认的588429)
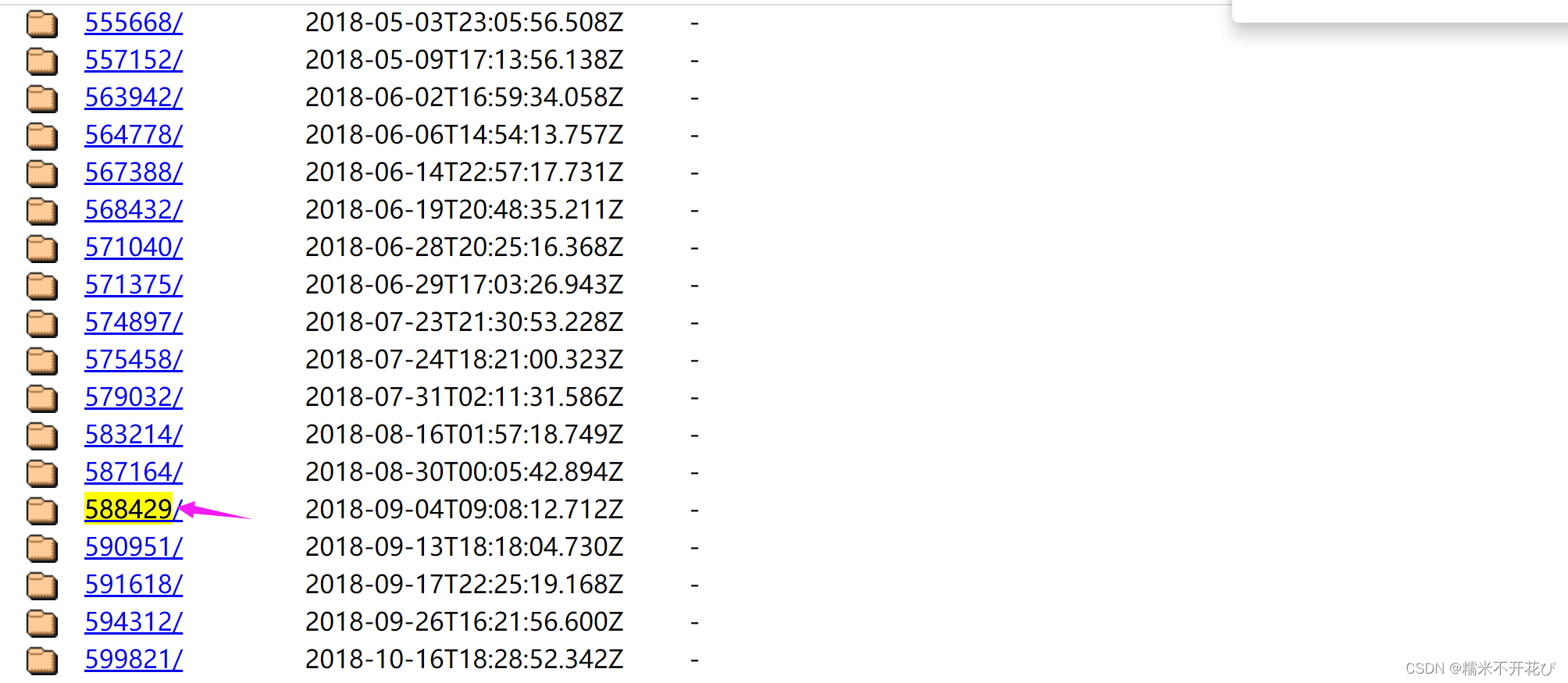
第四步:borwser驱动下载之后,将文件解压,放入上面pycharam中指定的路径中
也就是‘C:/Users/xiaohuamiao/AppData/Local/pyppeteer/pyppeteer/local-chromium/588429/chrome-win32/chrome.exe’这个路径;
需要手动在/pyppeteer/pyppeteer/文件下新建‘local-chromium’的文件夹、再新建'588429'的文件夹,然后将解压的文件'chrome-win32'放在‘588429’这个文件下

第五步:在python的库管理文件夹site-packages中pyppeteer文件:

进入chromium_downloader.py文件并打开修改代码:

这里是什么系统的就改什么后面的,我是windows,所以改windows的;
还有要注意,一定是要把https改成http,不然会报ssl的错
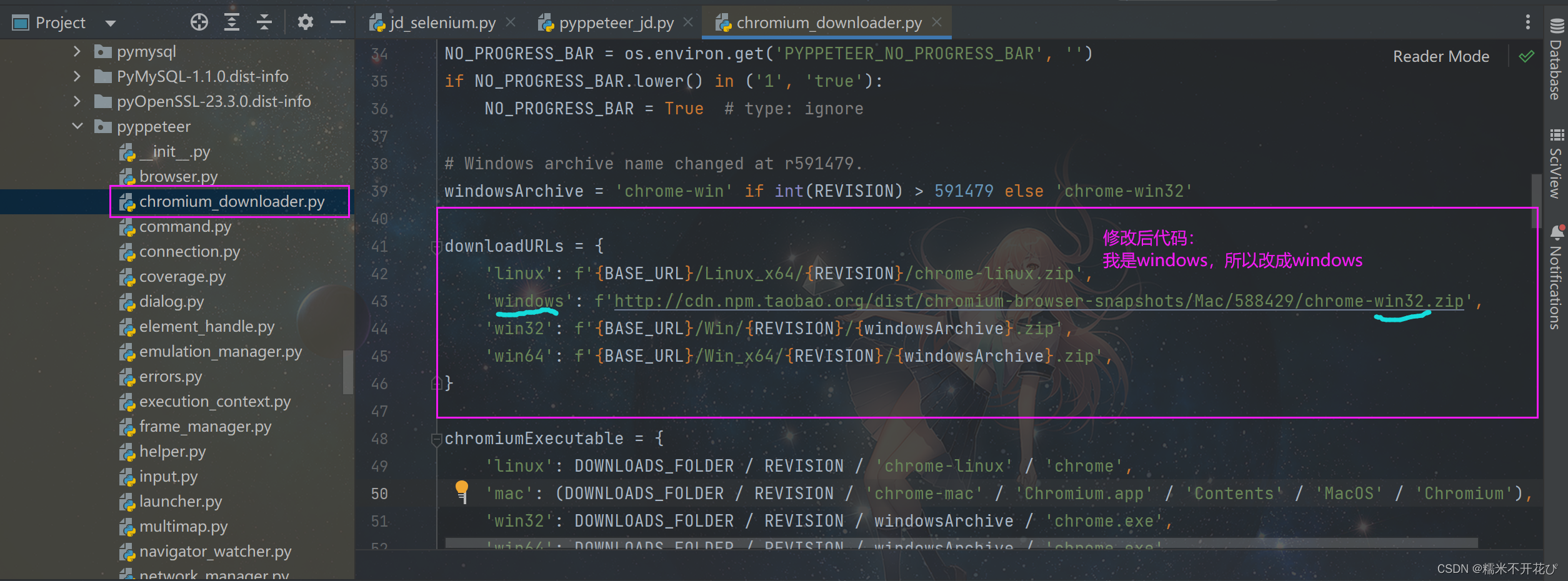
#修改后代码:
downloadURLs = {'linux': f'{BASE_URL}/Linux_x64/{REVISION}/chrome-linux.zip','windows': f'http://cdn.npm.taobao.org/dist/chromium-browser-snapshots/Mac/588429/chrome-win32.zip','win32': f'{BASE_URL}/Win/{REVISION}/{windowsArchive}.zip','win64': f'{BASE_URL}/Win_x64/{REVISION}/{windowsArchive}.zip',
}第六步:在pycharm中执行安装:
import pyppeteer.chromium_downloader
pyppeteer.chromium_downloader.download_chromium()等待安装、显示安装100%即可

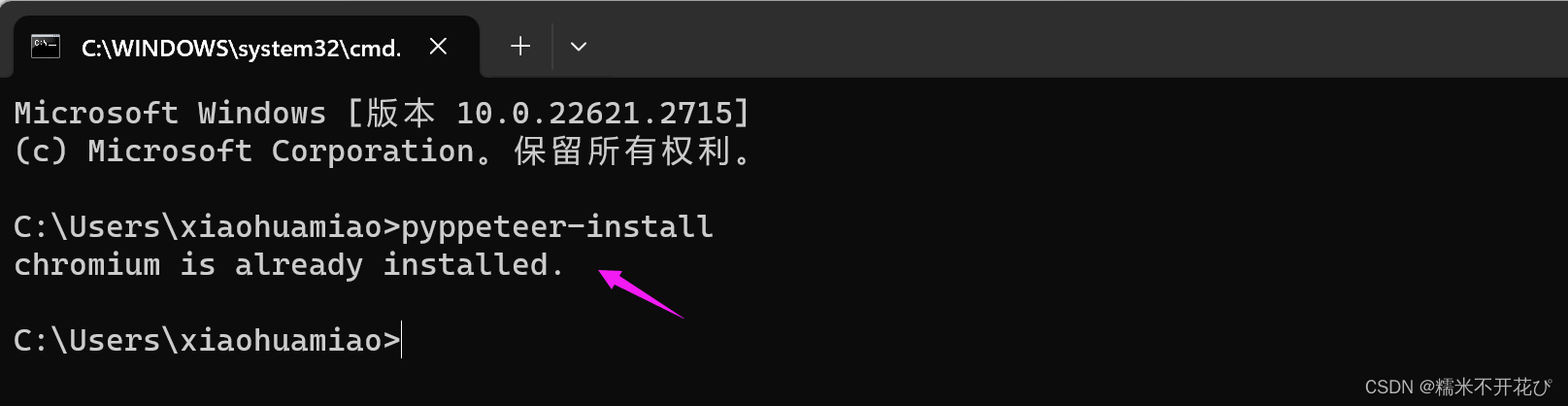
验证一下,是否安装成功:在cmd中再次pyppeteer-install,出现以下提示,说明安装成功:
pyppeteer的使用
pyppeteer的用法与Selenium基本一致,这里就不再一一介绍了
滑动验证登陆demo
在上一篇Selenium的滑动验证登陆demo中,web自动化 -- selenium及应用-CSDN博客
使用opencv简单快捷实现了计算缺口图片在背景图中的距离,但是由于没有进行拟人化处理,导致太快滑动对接上,从而被京东识别到是爬虫程序,呗拦截了,这里继续使用pyppeteer,以及做一下拟人化处理,进行完整的滑动验证到登陆:
完整代码如下:
import random
from pyppeteer import launch
import asyncio
import cv2
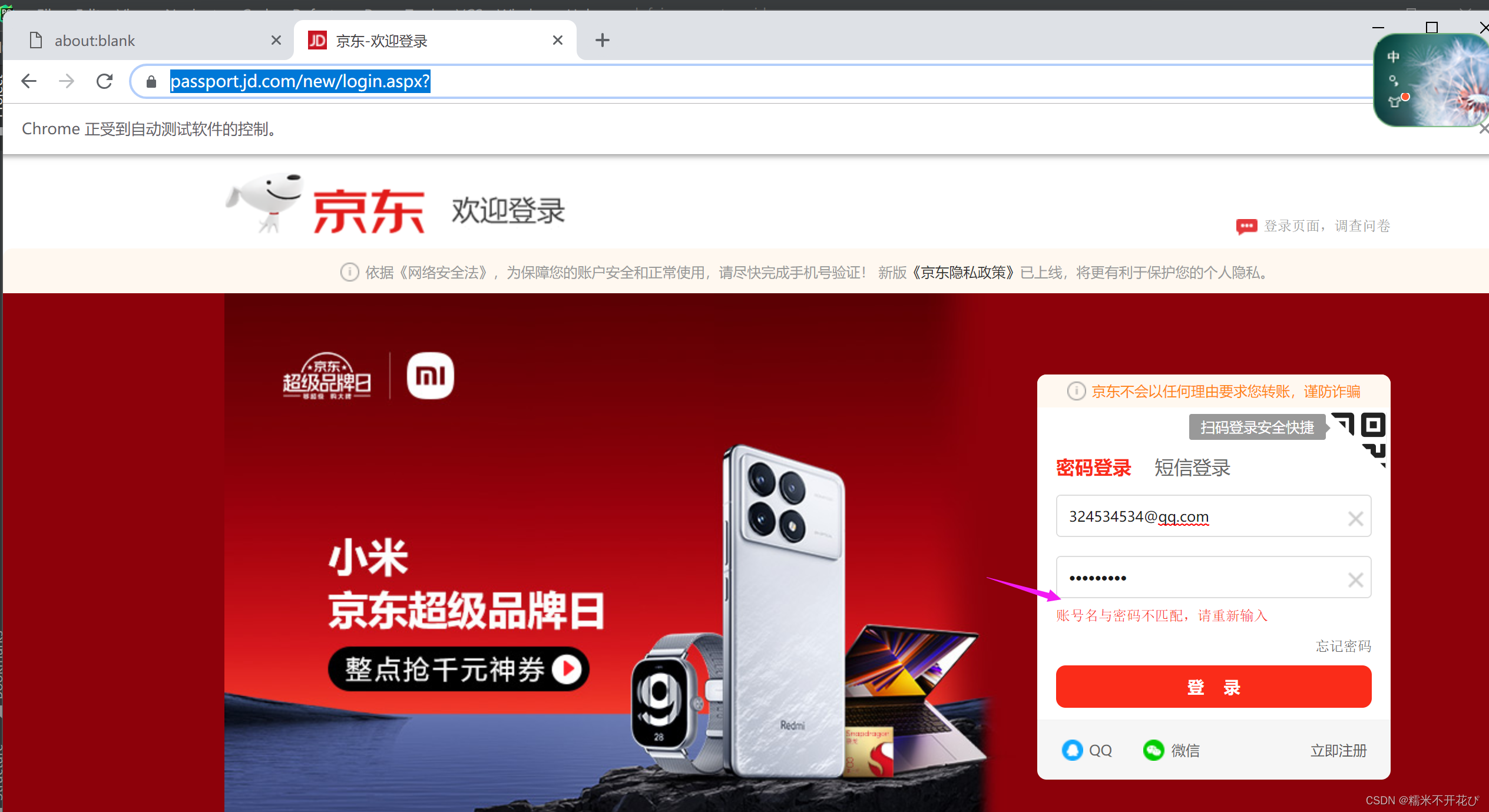
from urllib import requestasync def get_track():background = cv2.imread("background.png", 0)gap = cv2.imread("gap.png", 0)res = cv2.matchTemplate(background, gap, cv2.TM_CCOEFF_NORMED)value = cv2.minMaxLoc(res)[2][0]print(value)return value * 242 / 360async def main():browser = await launch({"headless": False, # headless指定浏览器是否以无头模式运行,默认是True。"args": ['--window-size=1366,768'],})# 打开新的标签页page = await browser.newPage()# 设置页面大小一致await page.setViewport({"width": 1366, "height": 768})# 访问主页await page.goto('https://passport.jd.com/new/login.aspx?')# evaluate()是执行js的方法,js逆向时如果需要在浏览器环境下执行js代码的话可以利用这个方法# js为设置webdriver的值,防止网站检测# await page.evaluate('''alert("马上输入用户名密码了!")''')# await page.evaluate('''() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }''')# await page.screenshot({'path': './1.jpg'}) # 截图保存路径# 模拟输入用户名和密码,输入每个字符的间隔时间delay msawait page.type("#loginname", '324534534@qq.com', {"c": random.randint(30, 60)})await page.type("#nloginpwd", '345653332', {"delay": random.randint(30, 60)})# page.waitFor 通用等待方式,如果是数字,则表示等待具体时间(毫秒): 等待2秒await page.waitFor(2000)await page.click("div.login-btn")await page.waitFor(2000)# page.jeval(selector,pageFunction)#定位元素,并调用js函数去执行img_src = await page.Jeval(".JDJRV-bigimg > img", "el=>el.src")temp_src = await page.Jeval(".JDJRV-smallimg > img", "el=>el.src")request.urlretrieve(img_src, "background.png")request.urlretrieve(temp_src, "gap.png")# 获取gap的距离distance = await get_track()"""# Pyppeteer 三种解析方式Page.querySelector() # 选择器Page.querySelectorAll()Page.xpath() # xpath 表达式# 简写方式为:Page.J(), Page.JJ(), and Page.Jx()"""el = await page.J("div.JDJRV-slide-btn")# 获取元素的边界框,包含x,y坐标box = await el.boundingBox()await page.hover("div.JDJRV-slide-btn")await page.mouse.down()# steps 是指分成几步来完成,steps越大,滑动速度越慢await page.mouse.move(box["x"] + distance + random.uniform(30, 33), box["y"], {"steps": 100})await page.waitFor(1000)await page.mouse.move(box["x"] + distance + 29, box["y"], {"steps": 100})await page.mouse.up()await page.waitFor(2000)await asyncio.sleep(3600)if __name__ == '__main__':asyncio.run(main())代码执行后,如下:
因为我输入的账号和密码都是错误的,所以滑块验证成功之后,得到响应提示账号密码不匹配
说明登陆已经发送成功了