wordpress不允许复制百度sem优化师
目录
排序函数
nlargest函数
nsmallest函数
sort_values函数
df.sort_values
Series.sort_values
聚合函数
corr函数-相关性
min函数-最小值
max函数-最大值
mean函数-平均值
sum函数-求和
count函数-统计非空数据
std函数-标准偏差
quantile函数-分位数
排序函数
准备函数
# 加载csv数据, 返回df对象
import pandas as pddf = pd.read_csv('../data/b_LJdata.csv')
# print(df.head())
# 获取前10条数据
df2 = df.head(10)
df2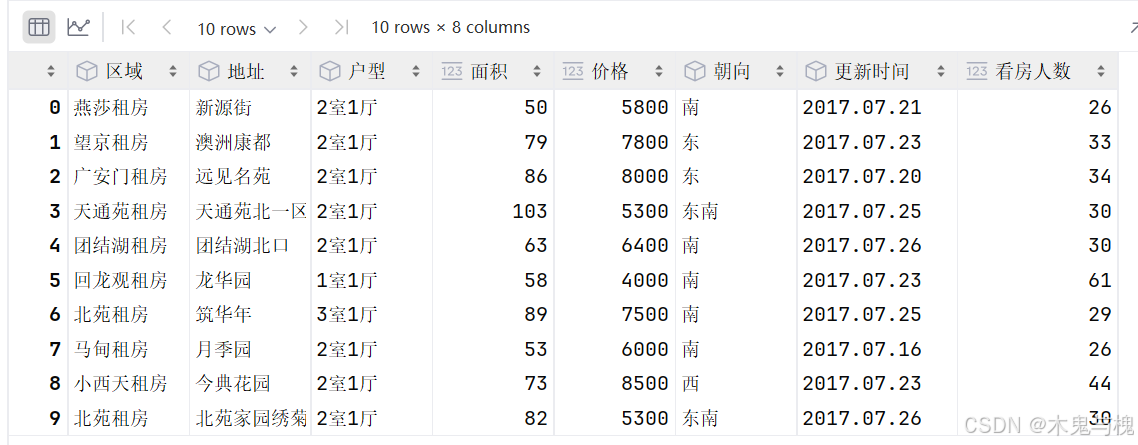
nlargest函数
通过 df.nlargest(n, 列名) 方法实现对指定列的值由大到小排序, 返回前n行数据
# df.nsmallest(n, '列名') # 根据指定列的值由小到大排列,返回n行数据
print(df2.nsmallest(5, '看房人数'))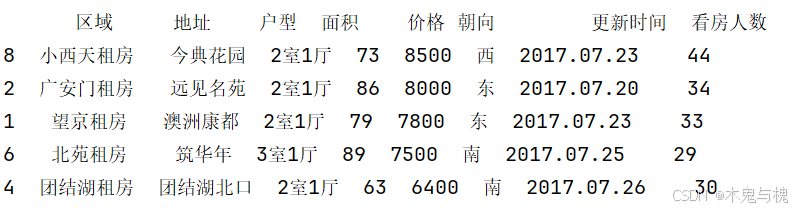
nsmallest函数
通过 df.nsmallest(n, 列名) 方法实现对指定列的值由小到大排序, 返回前n行数据
# df.nsmallest(n, '列名') # 根据指定列的值由小到大排列,返回n行数据
print(df2.nsmallest(5, '看房人数'))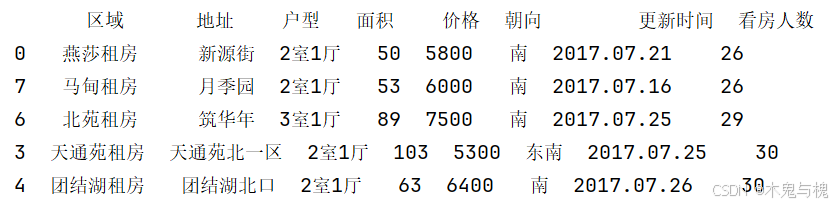
sort_values函数
通过 df.sort_values(列名列表, ascending=) 方法根据指定列指定排序方式排序
ascending: True或False, 默认True->升序, 也可以接收布尔值列表, 每列指定排序方式
df.sort_values
-
df.sort_values函数可以按照指定的一列或多列的值进行排序
1) 按价格列的数值由小到大进行排序
print(df2.sort_values(['价格']))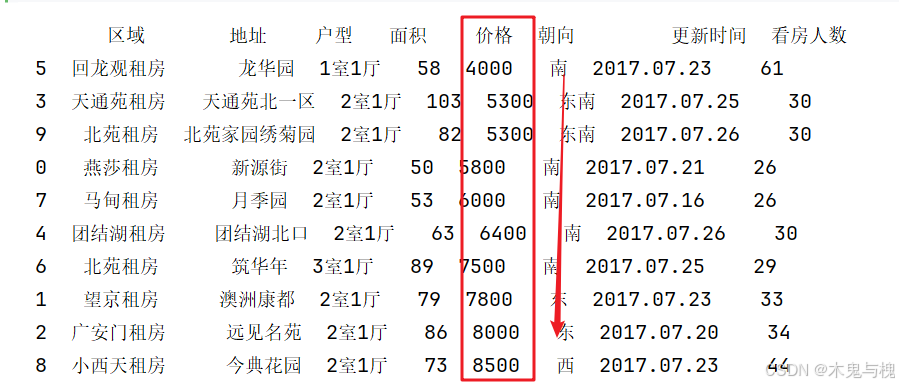
2) 按价格列的数值由大到小进行排序
print(df2.sort_values(['价格'], ascending=False))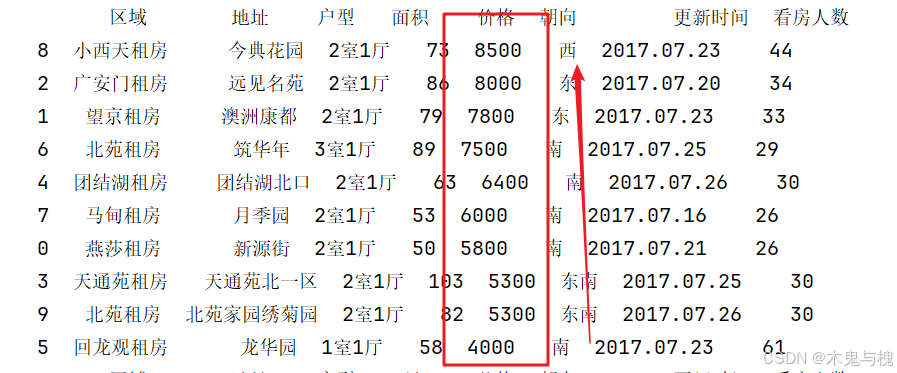
3) 先对看房人数列由小到大排序, 再对价格列由大到小排序
print(df2.sort_values(['看房人数', '价格'], ascending=[True, False]))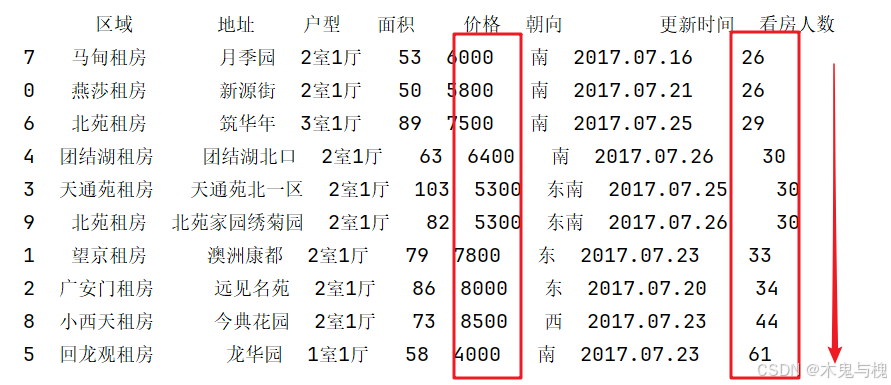
Series.sort_values
Series.sort_values 函数可以按照指定的一列或多列的值进行排序
1) 按价格列的数值由小到大进行排序
print(df2['价格'].sort_values())

2) 按价格列的数值由大到小进行排序
print(df2['价格'].sort_values(ascending=False))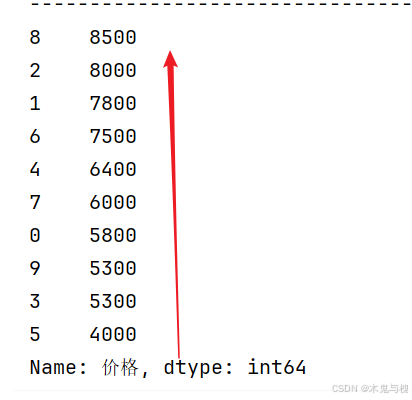
聚合函数
corr函数-相关性
相关性得分越接近1, 代表正相关性越强; 越接近-1, 代表负相关性越强 自己和自己相关性为1 面积和价格呈现正相关, 面积越大, 价格越贵
df.corr()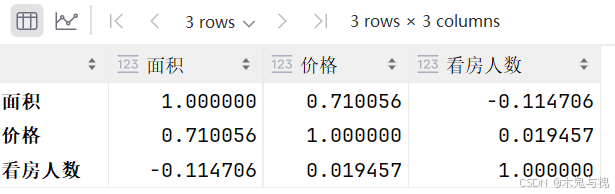
-
“面积” 与 “面积” 的相关系数为 1.000000,这是必然的,因为一个变量与自身完全相关。
-
“面积” 与 “价格” 的相关系数为 0.710056,呈正相关关系。这表明在该数据集中,一般情况下,房屋面积越大,价格越高。但需要注意的是,相关系数为 0.710056 表明这种关系并非完全线性相关,可能存在其他因素影响价格。
-
“面积” 与 “看房人数” 的相关系数为 -0.114706,呈较弱的负相关关系。这意味着房屋面积的大小与看房人数之间的关系不是很密切,面积的增加不一定会导致看房人数的减少,反之亦然。
-
“价格” 与 “价格” 的相关系数为 1.000000,同理,一个变量与自身完全相关。
-
“价格” 与 “看房人数” 的相关系数为 0.019457,接近 0,表明价格与看房人数之间几乎没有线性关系。房屋价格的高低对看房人数的影响不明显。
-
“看房人数” 与 “看房人数” 的相关系数为 1.000000,自身完全相关。
min函数-最小值
print(df2.min())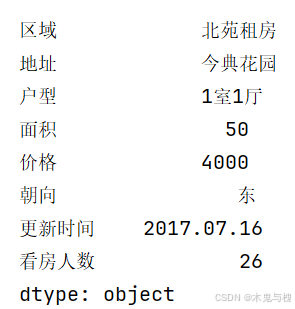
max函数-最大值
print(df2.max())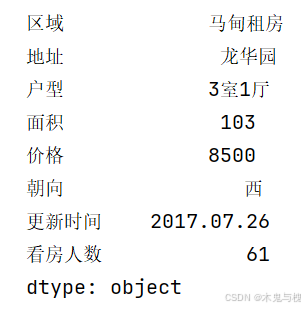
mean函数-平均值
print(df2.mean())
sum函数-求和
print(df2.sum())
print('======================')
print(df2['看房人数'].sum())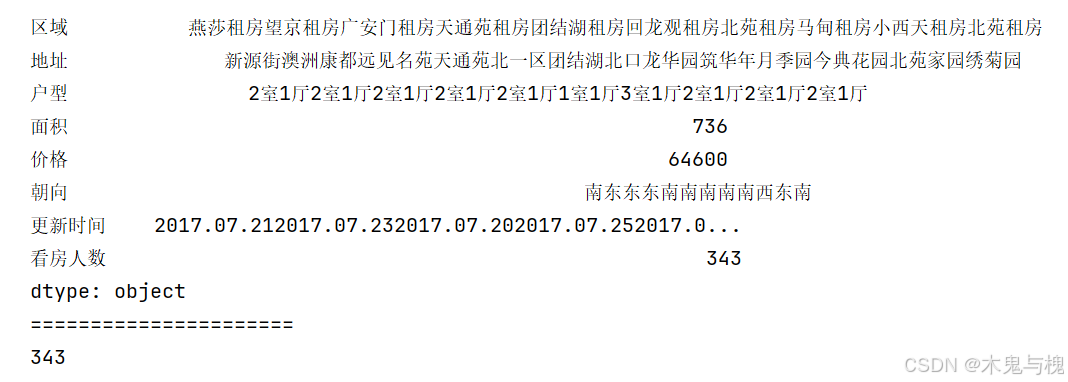
count函数-统计非空数据
# 构造空值
df2.loc[0, '看房人数'] = None
print(df2.count())
print(df2['看房人数'].count())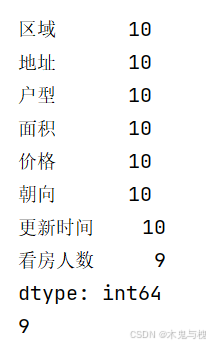
std函数-标准偏差
一、方差
方差是用来衡量一组数据离散程度的统计量。具体计算方法是先求出这组数据的平均值,然后对于每个数据值,计算它与平均值的差值,再将这个差值进行平方,最后把所有数据值的差值平方加起来求平均。

方差越大,说明这组数据的波动越大,数据点相对平均值的分散程度越高;方差越小,说明数据相对更加集中在平均值附近。
二、标准差
标准差是方差的算术平方根。
即标准差
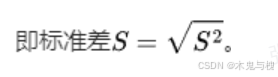
print(df2.std())
quantile函数-分位数
-
分位数(Quantile),亦称分位点,常用的有中位数(即二分位数)、四分位数、百分位数等;那什么是分位数呢?我们以中位数为例:通过把一堆数字按大小排序后找出正中间的一个数字作为中位数,如果这一堆数字有偶数个,则中位数不唯一,通常取最中间的两个数值的平均数作为中位数,即二分位数。
-
quantile函数默认返回二分位数;可以通过传入参数来控制返回的四分位数,或其他分位数
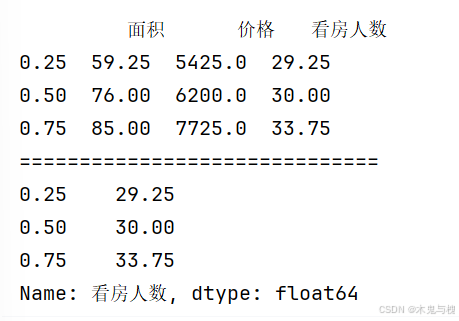
print(df2.quantile())
print(df2['看房人数'].quantile())
print(df2.quantile([0.25, 0.5, 0.75]))
print('==============================')
print(df2['看房人数'].quantile([0.25, 0.5, 0.75]))