个人接单做网站挣钱不营销策略有哪些4种
缓存击穿
缓存击穿是指某个热点数据存储在redis中,该数据在高并发的场景下,当该key过期时就会有大量的请求去查询数据库,对数据库的压力非常大,可能会导致数据库压垮。
解决方案
1.不为热点的key设置过期时间。
2.使用分布式锁。
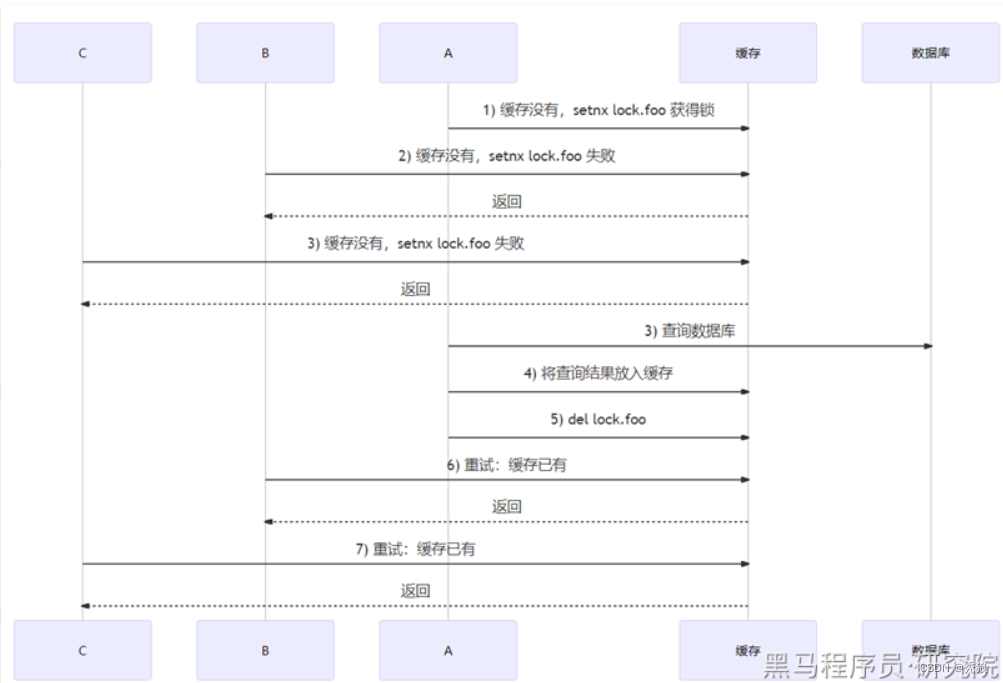
在查询数据库前需要获取锁,没有获取锁的请求会一直在重试,这样保证只有一条请求访问数据库,在该请求访问数据库后会将获得的信息重新存放到redis中,并将锁释放,在每次获取锁并访问数据库前还会再去redis中查询一次数据,这样就可以实现在第一个请求访问数据库后,后续的请求会直接从redis中查询出数据,解决了缓存击穿。
缓存雪崩
缓存雪崩存在两种情况
情况1:在redis中存的大量缓存的key设置了相同的过期时间,在这些key过期后就会大量请求访问数据库。
1情况2:redis服务宕机了,导致大量的请求访问数据库。
解决方案
情况1的解决方案
1.错开过期时间:在过期时间上添加(1~5分钟)的随机时间。
2.服务降级:停止非核心数据查询缓存,返回预定义信息。(就是实现FallbackFactory接口)
情况2的解决方案
1.搭建redis集群
2.构建二级缓存。(目前使用的就是 Caffeine作为一级缓存,redis做二级缓存)
3.熔断:通过监控一旦雪崩出现,暂停缓存访问待实例恢复,返回预定义信息。(有损方案)
4.限流:通过监控一旦数据库的访问量超出阈值,就限制访问数据库的请求数。(有损方案)
实现步骤
错开过期时间的实现为下:
自定义 MyRedisCacheManager类继承RedisCacheManager
import cn.hutool.core.util.ObjectUtil;
import cn.hutool.core.util.RandomUtil;
import org.springframework.data.redis.cache.RedisCache;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.cache.RedisCacheWriter;import java.time.Duration;/*** 自定义CacheManager,用于设置不同的过期时间,防止雪崩问题的发生*/
public class MyRedisCacheManager extends RedisCacheManager {public MyRedisCacheManager(RedisCacheWriter cacheWriter, RedisCacheConfiguration defaultCacheConfiguration) {super(cacheWriter, defaultCacheConfiguration);}@Overrideprotected RedisCache createRedisCache(String name, RedisCacheConfiguration cacheConfig) {//获取到原有过期时间Duration duration = cacheConfig.getTtl();if (ObjectUtil.isNotEmpty(duration)) {//在原有时间上随机增加1~10分钟//后续使用时需要修改的就是这里的时间Duration newDuration = duration.plusMinutes(RandomUtil.randomInt(1, 11));cacheConfig = cacheConfig.entryTtl(newDuration);}return super.createRedisCache(name, cacheConfig);}
}
在RedisConfig中使用MyRedisCacheManager作自定义缓存管理器配置。
@Beanpublic RedisCacheManager redisCacheManager(RedisTemplate redisTemplate) {// 默认配置RedisCacheConfiguration defaultCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()// 设置key的序列化方式为字符串.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()))// 设置value的序列化方式为json格式.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer())).disableCachingNullValues() // 不缓存null.entryTtl(Duration.ofHours(redisTtl)); // 默认缓存数据保存1小时//使用自定义缓存管理器RedisCacheWriter redisCacheWriter = RedisCacheWriter.nonLockingRedisCacheWriter(redisTemplate.getConnectionFactory());MyRedisCacheManager myRedisCacheManager = new MyRedisCacheManager(redisCacheWriter, defaultCacheConfiguration);myRedisCacheManager.setTransactionAware(true); // 只在事务成功提交后才会进行缓存的put/evict操作return myRedisCacheManager;}缓存穿透
一个key在缓存和数据库中都不存在,这样每次查询该key都需要访问数据库。
- 很可能被恶意请求利用
- 缓存雪崩与缓存击穿都是数据库中有,但缓存暂时缺失
- 缓存雪崩与缓存击穿都能自然恢复,但缓存穿透则不能
解决方案
1. 如果数据库中没有,也将此key关联null存入缓存中,缺点就是这样的key没有作用,白白浪费空间。
2. 采用BloomFilter(布隆过滤器)解决,基本思路就是将存在数据的哈希值存储到一个足够大的Bitmap(Bit为单位存储数据,可以大大节省存储空间)中,在查询redis时,先查询布隆过滤器,如果数据不存在直接返回即可,如果存在的话,再执行缓存中命中、数据库查询等操作。(通过hash函数计算出key对应的位置,如果有值就将对应位置改为1,在后续查询redis前先从布隆过滤器中查询数据是否存在),适合用来做判断不存在的操作。
实现步骤
布隆过滤器
需要将数据存入布隆过滤器中,才能判断数据是否存在,存入时要通过hash算法函数计算出hash值,通过hash值确定存储的位置。
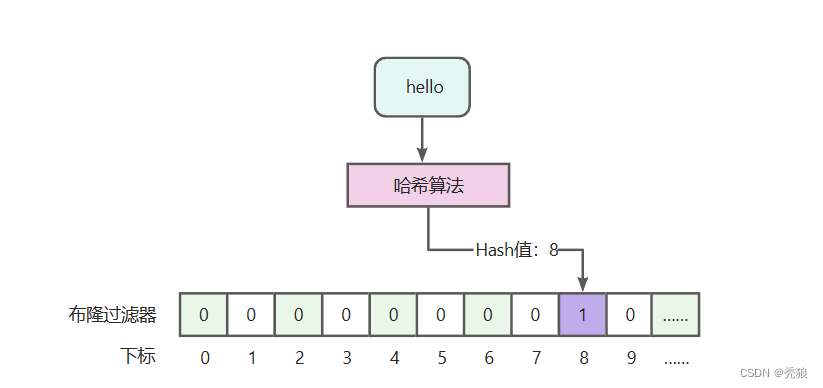 看到这里,你一定会有这样的疑问,不同的数据经过哈希算法计算,可能会得到相同的值,也就是,【张三】和【王五】可能会得到相同的hash值,会在同一个位置标记为1,这样的话,1个位置可能会代表多个数据,也就是会出现误判,没错,这个就是布隆过滤器最大的一个缺点,也是不可避免的特性。正因为这个特性,所以布隆过滤器基本是不能做删除动作的。
看到这里,你一定会有这样的疑问,不同的数据经过哈希算法计算,可能会得到相同的值,也就是,【张三】和【王五】可能会得到相同的hash值,会在同一个位置标记为1,这样的话,1个位置可能会代表多个数据,也就是会出现误判,没错,这个就是布隆过滤器最大的一个缺点,也是不可避免的特性。正因为这个特性,所以布隆过滤器基本是不能做删除动作的。
总结:使用布隆过滤器能够判断一定不存在,而不能用来判断一定存在。
为了降低误判率我们可以使用多哈希法。
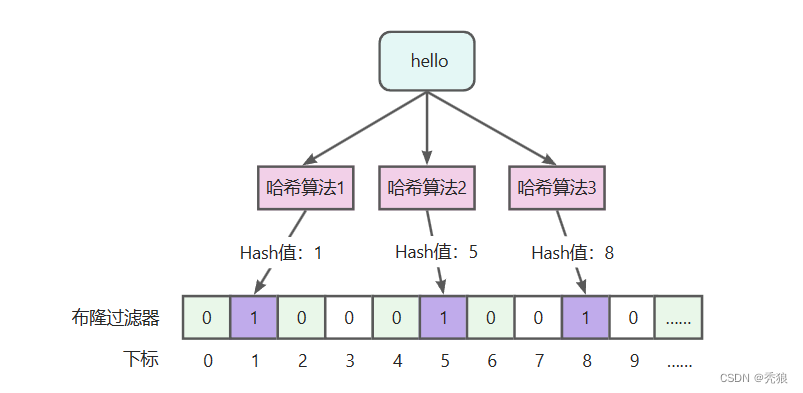 通过多个哈希算法计算参数多个位置,在这多个位置上进行标记,在后续查找时只有这多个位置同时为1时才说明存在数据,虽然降低了误判率,但误判数据存在还是存在的。
通过多个哈希算法计算参数多个位置,在这多个位置上进行标记,在后续查找时只有这多个位置同时为1时才说明存在数据,虽然降低了误判率,但误判数据存在还是存在的。
布隆过滤器的优缺点
- 优点
-
- 存储的二进制数据,1或0,不存储真实数据,空间占用比较小且安全。
- 插入和查询速度非常快,因为是基于数组下标的,类似HashMap,其时间复杂度是O(K),其中k是指哈希算法个数。
- 缺点
-
- 存在误判,可以通过增加哈希算法个数降低误判率,不能完全避免误判。
- 删除困难,因为一个位置可能会代表多个值,不能做删除。
牢记结论:布隆过滤器能够判断一定不存在,而不能用来判断一定存在 。
Redission基于Redis,使用string类型数据,生成二进制数组进行存储,最大可用长度为:4294967294。
引入依赖
<dependency><groupId>org.redisson</groupId><artifactId>redisson</artifactId></dependency>设置redission配置
import cn.hutool.core.convert.Convert;
import cn.hutool.core.util.StrUtil;
import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.redisson.config.SingleServerConfig;
import org.springframework.boot.autoconfigure.data.redis.RedisProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import javax.annotation.Resource;@Configuration
public class RedissonConfiguration {@Resourceprivate RedisProperties redisProperties;@Beanpublic RedissonClient redissonSingle() {Config config = new Config();SingleServerConfig serverConfig = config.useSingleServer().setAddress("redis://" + redisProperties.getHost() + ":" + redisProperties.getPort());if (null != (redisProperties.getTimeout())) {serverConfig.setTimeout(1000 * Convert.toInt(redisProperties.getTimeout().getSeconds()));}if (StrUtil.isNotEmpty(redisProperties.getPassword())) {serverConfig.setPassword(redisProperties.getPassword());}return Redisson.create(config);}}
自定义布隆过滤器配置
import lombok.Getter;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;/*** 布隆过滤器相关配置*/
@Getter
@Configuration
public class BloomFilterConfig {/*** 名称,默认:sl-bloom-filter*/@Value("${bloom.name:sl-bloom-filter}")private String name;/*** 布隆过滤器长度,最大支持Integer.MAX_VALUE*2,即:4294967294,默认:1千万*/@Value("${bloom.expectedInsertions:10000000}")private long expectedInsertions;/*** 误判率,默认:0.05*/@Value("${bloom.falseProbability:0.05d}")private double falseProbability;}
创建布隆过滤器的Service接口
/*** 布隆过滤器服务*/
public interface BloomFilterService {/*** 初始化布隆过滤器*/void init();/*** 向布隆过滤器中添加数据** @param obj 待添加的数据* @return 是否成功*/boolean add(Object obj);/*** 判断数据是否存在** @param obj 数据* @return 是否存在*/boolean contains(Object obj);}
编写Service的实现类
import com.sl.transport.info.config.BloomFilterConfig;
import com.sl.transport.info.service.BloomFilterService;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.stereotype.Service;import javax.annotation.PostConstruct;
import javax.annotation.Resource;@Service
public class BloomFilterServiceImpl implements BloomFilterService {@Resourceprivate RedissonClient redissonClient;@Resourceprivate BloomFilterConfig bloomFilterConfig;private RBloomFilter<Object> getBloomFilter() {return this.redissonClient.getBloomFilter(this.bloomFilterConfig.getName());}@Override@PostConstruct // spring启动后进行初始化public void init() {RBloomFilter<Object> bloomFilter = this.getBloomFilter();bloomFilter.tryInit(this.bloomFilterConfig.getExpectedInsertions(), this.bloomFilterConfig.getFalseProbability());}@Overridepublic boolean add(Object obj) {return this.getBloomFilter().add(obj);}@Overridepublic boolean contains(Object obj) {return this.getBloomFilter().contains(obj);}
}
改造Controller的查询逻辑,如果布隆过滤器中不存在直接返回即可,无需进行缓存命中。
@ApiImplicitParams({@ApiImplicitParam(name = "transportOrderId", value = "运单id")})@ApiOperation(value = "查询", notes = "根据运单id查询物流信息")@GetMapping("{transportOrderId}")public TransportInfoDTO queryByTransportOrderId(@PathVariable("transportOrderId") String transportOrderId) {//如果布隆过滤器中不存在,无需缓存命中,直接返回即可boolean contains = this.bloomFilterService.contains(transportOrderId);if (!contains) {throw new SLException(ExceptionEnum.NOT_FOUND);}TransportInfoDTO transportInfoDTO = transportInfoCache.get(transportOrderId, id -> {//未命中,查询MongoDBTransportInfoEntity transportInfoEntity = this.transportInfoService.queryByTransportOrderId(id);//转化成DTOreturn BeanUtil.toBean(transportInfoEntity, TransportInfoDTO.class);});if (ObjectUtil.isNotEmpty(transportInfoDTO)) {return transportInfoDTO;}throw new SLException(ExceptionEnum.NOT_FOUND);}新增操作的Service中将数据写入布隆过滤器中,也就是调用bloomService层的add方法
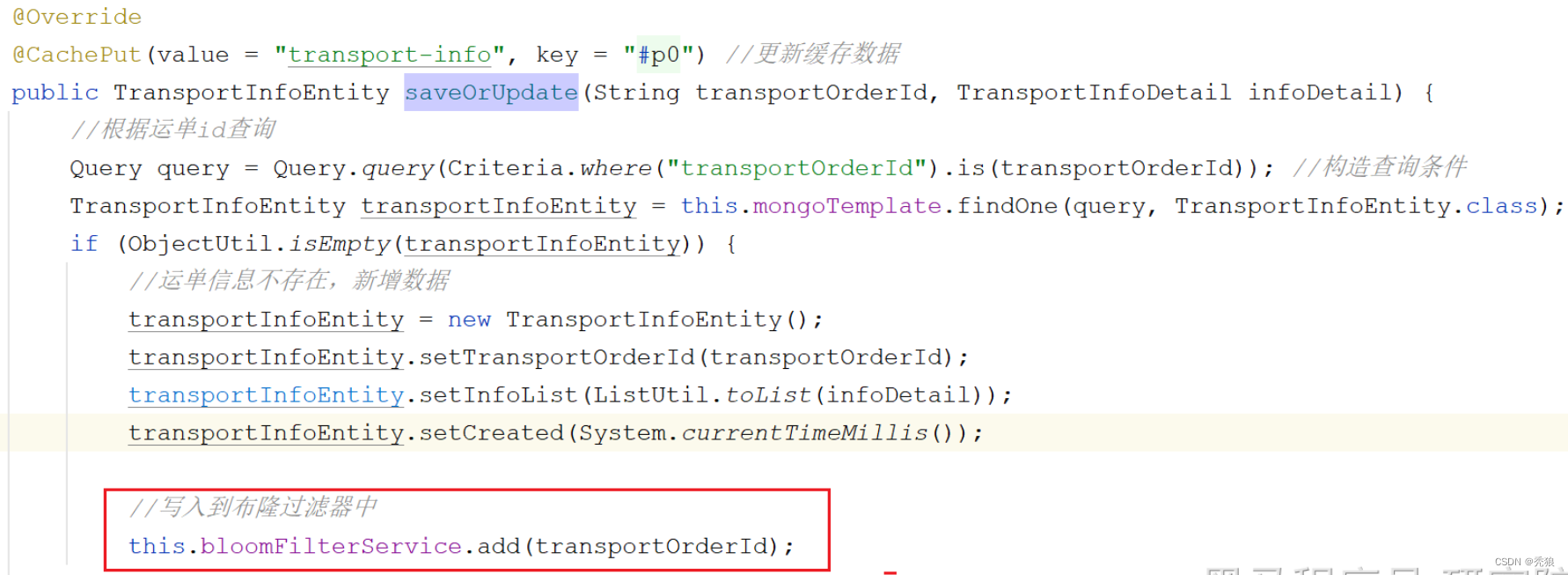
最终完成布隆过滤器的创建。