教育响应式网站建设如何推广一款app
早在之前使用yolov3和yolov4这类项目的时候可视化分析大都是自己去做的,到了yolov5的时候,变成了一个工具包了,作者全部集成进去了,这里我们以一个具体的结果为例,如下:
整个训练过程产生的指标等数据都会自动存储在results.csv文件中,样例如下:
epoch, train/box_loss, train/obj_loss, train/cls_loss, metrics/precision, metrics/recall, metrics/mAP_0.5,metrics/mAP_0.5:0.95, val/box_loss, val/obj_loss, val/cls_loss, x/lr0, x/lr1, x/lr20, 0.10686, 0.037486, 0.043172, 3.5503e-05, 0.081818, 6.7977e-05, 6.7977e-06, 0.10325, 0.028426, 0.048823, 0.0032639, 0.0032639, 0.0706251, 0.095976, 0.036554, 0.033969, 1.5779e-05, 0.036364, 9.9894e-06, 9.9894e-07, 0.10191, 0.025884, 0.048571, 0.0065755, 0.0065755, 0.0406032, 0.092345, 0.035059, 0.026585, 0.69881, 0.11456, 0.075731, 0.018321, 0.088135, 0.022605, 0.02569, 0.009865, 0.009865, 0.0105593, 0.083534, 0.031197, 0.020803, 0.82368, 0.064706, 0.028317, 0.0062686, 0.084487, 0.026695, 0.017308, 0.009901, 0.009901, 0.0099014, 0.075767, 0.029818, 0.016323, 0.86978, 0.061765, 0.033261, 0.0053925, 0.10178, 0.029376, 0.070501, 0.009901, 0.009901, 0.0099015, 0.067523, 0.027457, 0.012056, 0.47496, 0.34274, 0.28957, 0.11535, 0.061691, 0.020951, 0.011154, 0.009868, 0.009868, 0.0098686, 0.061948, 0.026722, 0.010247, 0.52522, 0.54733, 0.41804, 0.16074, 0.053302, 0.017201, 0.0059595, 0.009835, 0.009835, 0.0098357, 0.05911, 0.02557, 0.0088241, 0.48578, 0.43543, 0.29211, 0.078039, 0.061702, 0.018276, 0.0072567, 0.009802, 0.009802, 0.0098028, 0.055845, 0.025299, 0.0083748, 0.66558, 0.53072, 0.49424, 0.18659, 0.051491, 0.01447, 0.0057275, 0.009769, 0.009769, 0.0097699, 0.052453, 0.024121, 0.0068002, 0.53734, 0.28439, 0.33729, 0.13902, 0.058835, 0.015342, 0.0057659, 0.009736, 0.009736, 0.00973610, 0.050568, 0.022984, 0.0062438, 0.68729, 0.56757, 0.55128, 0.23321, 0.046871, 0.013466, 0.0050426, 0.009703, 0.009703, 0.00970311, 0.049129, 0.023172, 0.0063243, 0.72319, 0.57423, 0.67815, 0.34033, 0.04388, 0.012949, 0.0046631, 0.00967, 0.00967, 0.00967作者也直接对其进行了可视化,如下:

官方源码如下:
def plot_results(file='path/to/results.csv', dir=''):# Plot training results.csv. Usage: from utils.plots import *; plot_results('path/to/results.csv')save_dir = Path(file).parent if file else Path(dir)fig, ax = plt.subplots(2, 5, figsize=(12, 6), tight_layout=True)ax = ax.ravel()files = list(save_dir.glob('results*.csv'))assert len(files), f'No results.csv files found in {save_dir.resolve()}, nothing to plot.'for f in files:try:data = pd.read_csv(f)s = [x.strip() for x in data.columns]x = data.values[:, 0]for i, j in enumerate([1, 2, 3, 4, 5, 8, 9, 10, 6, 7]):y = data.values[:, j].astype('float')# y[y == 0] = np.nan # don't show zero valuesax[i].plot(x, y, marker='.', label=f.stem, linewidth=2, markersize=8)ax[i].set_title(s[j], fontsize=12)# if j in [8, 9, 10]: # share train and val loss y axes# ax[i].get_shared_y_axes().join(ax[i], ax[i - 5])except Exception as e:LOGGER.info(f'Warning: Plotting error for {f}: {e}')ax[1].legend()fig.savefig(save_dir / 'results.png', dpi=200)plt.close()这样其实已经很完善了,但是如果自己有一些个性化的需求的时候还是得自己去进行解析可视化的。
比如,做论文的时候大都是会改进还有多种模型对比分析,这时候就可能会想要对不同的模型的统一指标进行对比可视化。
我这里只是简单以实例进行分析,首先读取数据:
df1=pd.read_csv(originalModel)
df2=pd.read_csv(selfModel)
print(df1.head(5))
print("="*100)
print(df2.head(5))结果如下:
epoch ... x/lr2
0 0 ... 0.070316
1 1 ... 0.040250
2 2 ... 0.010118
3 3 ... 0.009703
4 4 ... 0.009703[5 rows x 14 columns]
====================================================================================================epoch ... x/lr2
0 0 ... 0.070625
1 1 ... 0.040603
2 2 ... 0.010559
3 3 ... 0.009901
4 4 ... 0.009901[5 rows x 14 columns]接下来提取自己想要进行可视化的指标数据,比如这里我是对训练的box_loss进行解析,如下:
train_box_loss1=[one_list[1] for one_list in data_list1]
train_box_loss2=[one_list[1] for one_list in data_list2]其他的指标的操作原理也是一样的,这里就不再赘述了。
如果想要累加loss也是可以的,如下:
train_loss_1=[train_box_loss1[i]+train_obj_loss1[i]+train_cls_loss1[i] for i in range(epochs)]
train_loss_2=[train_box_loss2[i]+train_obj_loss2[i]+train_cls_loss2[i] for i in range(epochs)]验证集的操作也是一样的。
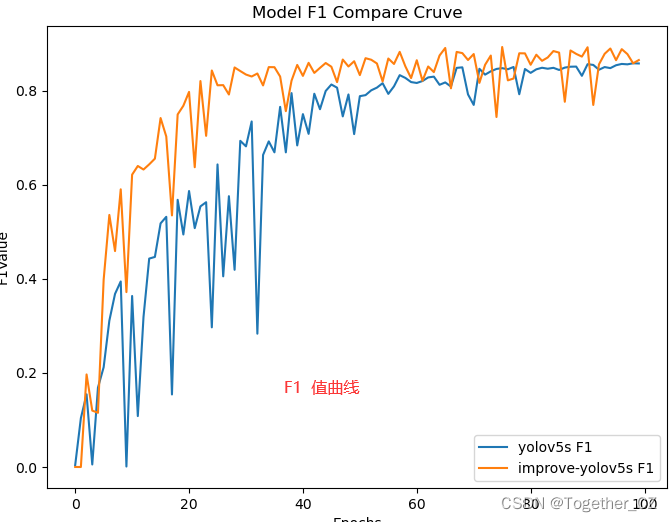
最后我们可以看下成品的效果:
【Loss曲线】

【精确率曲线】

【召回率曲线】

【F1值曲线】