做网站用需要几个软件每日英语新闻
1.什么是HIVE
1.HIVE是什么?
Hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
大白话: HIVE就是一个类似于Navicat的可视化客户端,
2.HIVE本质
Hive是一个Hadoop客户端,用于将HQL(Hive SQL)转化成MapReduce程序。
(1)Hive中每张表的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce(也可配置为Spark或者Tez)
(3)执行程序运行在Yarn上
3.架构
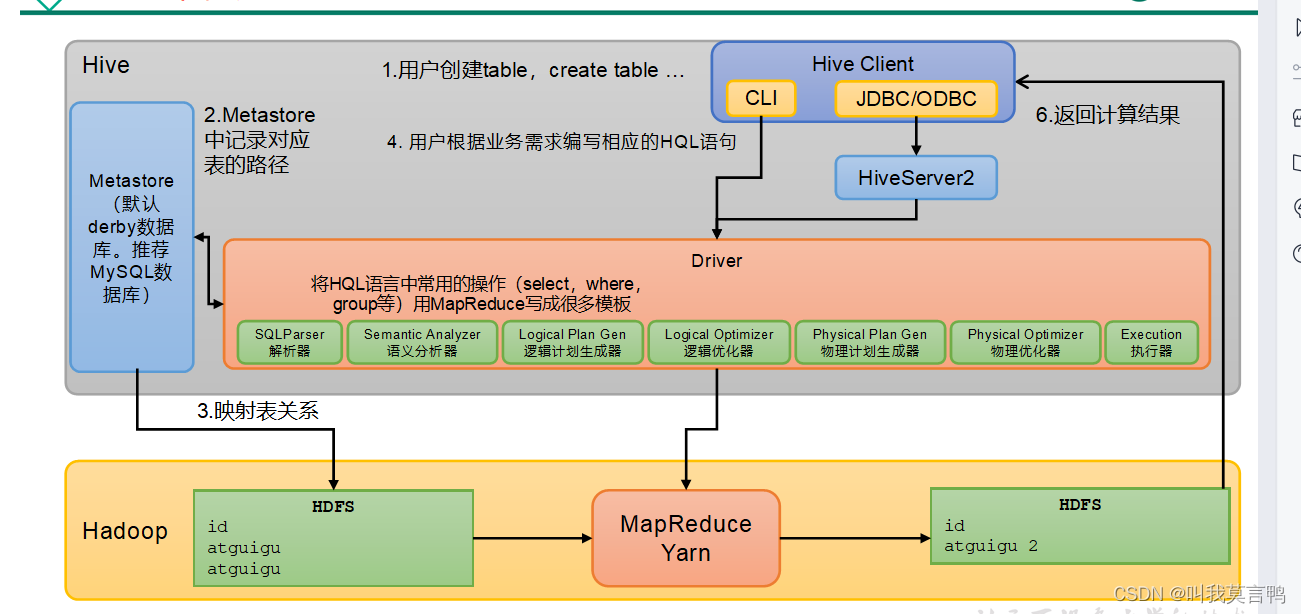
2.HIVE的配置
1.首先,如果我们只是想在LINUX本机上运行HIVE,是不需要配置任何配置文件的
2.当然,我们一般都需要修改一下使用的数据库 mysql安装就不多赘述了,这里说一下配置文件
2.1 Mysql配置到HIVE上
1.导入驱动包
lib文件夹就是专门存储包的目录
cp /opt/software/mysql-connector-java-5.1.37.jar $HIVE_HOME/lib
将MySQL的JDBC驱动拷贝到Hive的lib目录下。
2.修改配置文件
和连接池大差不差
URL DRIVER username password 工作目录
vim $HIVE_HOME/conf/hive-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><configuration><!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value></property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property><!-- Hive默认在HDFS的工作目录 --><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property>
</configuration>
3.初始化元数据库
bin/schematool -dbType mysql -initSchema -verbose
3.配置HiveServer2
1. 作用
Hive的hiveserver2服务的作用是提供jdbc/odbc接口,为用户提供远程访问Hive数据的功能,例如用户期望在个人电脑中访问远程服务中的Hive数据,就需要用到Hiveserver2。
其实就是用真正的可视化软件连接HIVE,就需要这样
比如DataGrip
2.配置
因为在生产环境下,我们需要开启用户模拟功能(哪个用户访问HIVE,就用哪个用户去访问HADOOP,就跟QQ登录一样)
hivesever2的模拟用户功能,依赖于Hadoop提供的proxy user(代理用户功能),只有Hadoop中的代理用户才能模拟其他用户的身份访问Hadoop集群。因此,需要将hiveserver2的启动用户设置为Hadoop的代理用户
也就是说,用户必须自己拥有访问HADOOP的权利,HIVE才能模拟他去访问,这样就必须修改HADOOP的配置文件core-site.xml
- 配置1
<!--配置所有节点的atguigu用户都可作为代理用户-->
<property><name>hadoop.proxyuser.atguigu.hosts</name><value>*</value>
</property><!--配置atguigu用户能够代理的用户组为任意组-->
<property><name>hadoop.proxyuser.atguigu.groups</name><value>*</value>
</property><!--配置atguigu用户能够代理的用户为任意用户-->
<property><name>hadoop.proxyuser.atguigu.users</name><value>*</value>
</property>
- 配置2 hive-site.xml
<!-- 指定hiveserver2连接的host -->
<property><name>hive.server2.thrift.bind.host</name><value>hadoop102</value>
</property><!-- 指定hiveserver2连接的端口号 -->
<property><name>hive.server2.thrift.port</name><value>10000</value>
</property>
3. 测试
bin/beeline -u jdbc:hive2://hadoop102:10000 -n atguigu
下面是执行后的消息,如果没出现这个,回头看日志,不要只看Server2的,
Connecting to jdbc:hive2://hadoop102:10000
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 3.1.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.3 by Apache Hive
0: jdbc:hive2://hadoop102:10000>
4.MetaStore服务
Hive的metastore服务的作用是为Hive CLI或者Hiveserver2提供元数据访问接口。
1. 2种模式
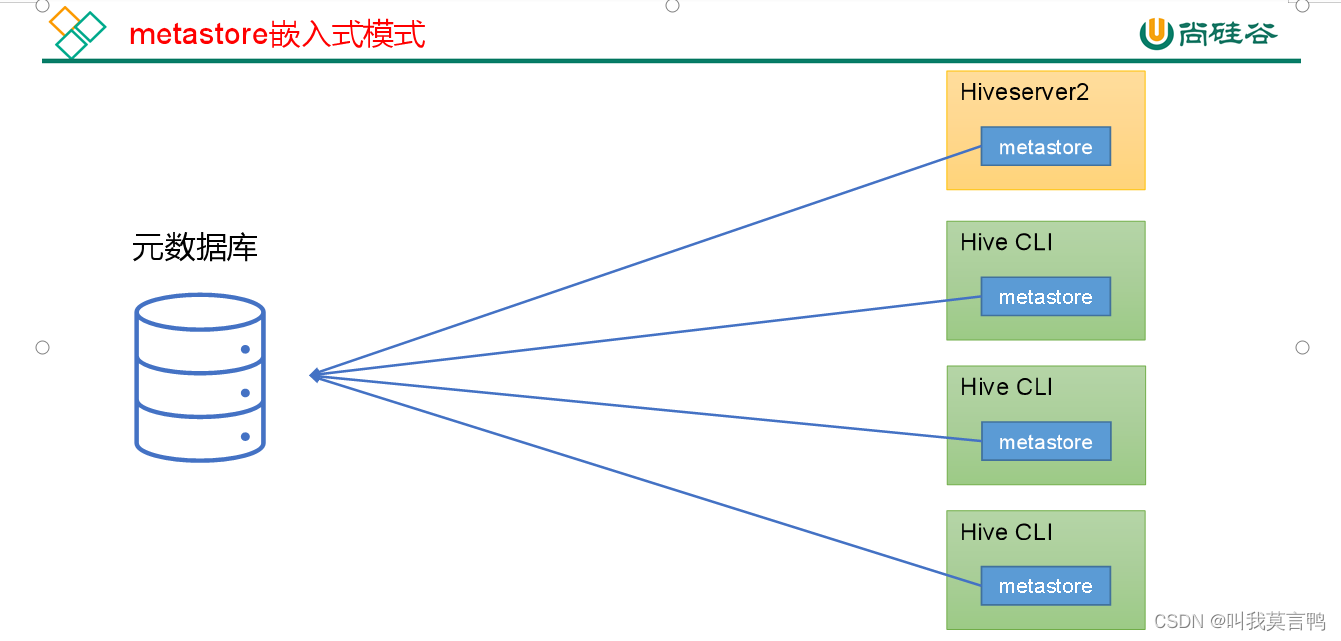
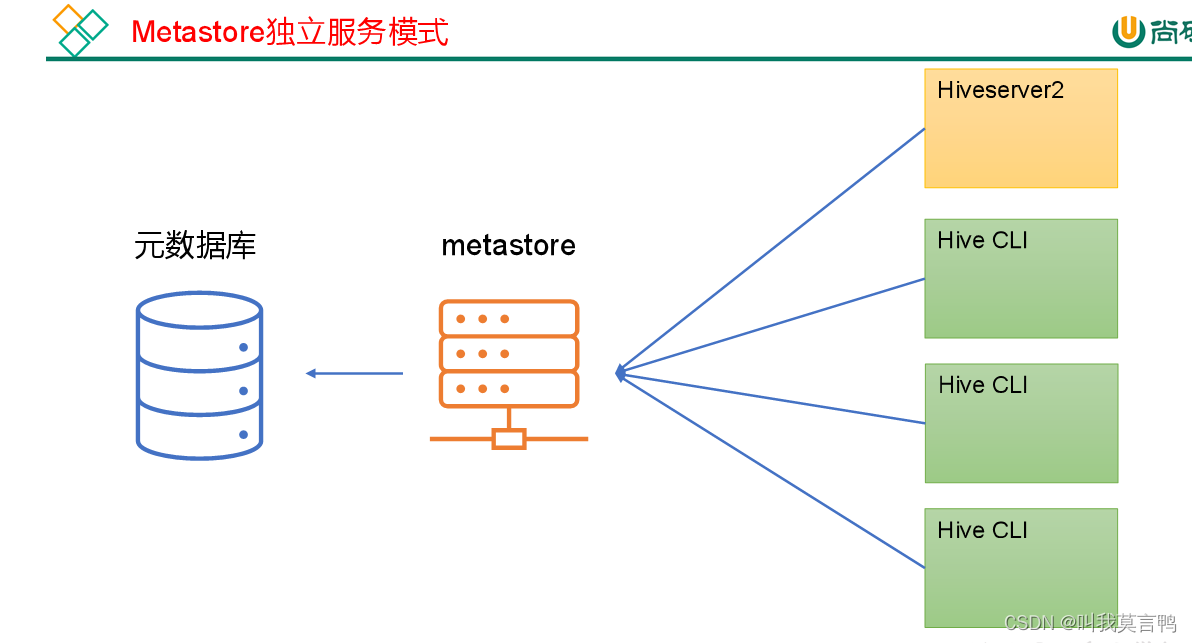
2. 两种模式的分析
- 嵌入式: 每个Hive CLI都直接连接元数据库
- 独立服务:都通过Metastore对源数据库信息访问
两者的区别
- 安全性 嵌入式都具有读写权限,过于危险,独立服务相对优秀
- IO压力 嵌入式元数据库一力承担IO压力,同时他要进行读写,所以对源数据库的要求过高,而独立服务将IO交给metastore来做,相对优秀
3.修改配置
嵌入式,只要保证HIVE能连接数据库即可
- hive.site
<!-- jdbc连接的URL --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value></property><!-- jdbc连接的Driver--><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.jdbc.Driver</value></property><!-- jdbc连接的username--><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><!-- jdbc连接的password --><property><name>javax.jdo.option.ConnectionPassword</name><value>123456</value></property>
- 独立服务模式单独添加(上面的还是要配的,必须连数据库)
注意:主机名需要改为metastore服务所在节点,端口号无需修改,metastore服务的默认端口就是9083。
<!-- 指定metastore服务的地址 -->
<property><name>hive.metastore.uris</name><value>thrift://hadoop102:9083</value>
</property>
4.测试
1.先启动metastore
在看数据库
hive --service metastore
3.配置相关
1.参数配置
默认配置文件:hive-default.xml
用户自定义配置文件:hive-site.xml
1.查看参数配置
hive>set;
2.设置参数
命令行添加-hiveconf param=value
或者使用set 参数名=参数
如果没有"=参数", 就是查看这个参数
只是本次Hive有效,不是永久修改


2.日志配置
1.HIVE默认日志存储
Hive的log默认存放在/tmp/atguigu/hive.log目录下(当前用户名下)
2.修改Hive的log存放日志到/opt/module/hive/logs
[atguigu@hadoop102 conf]$ pwd
/opt/module/hive/conf[atguigu@hadoop102 conf]$ mv hive-log4j2.properties.template hive-log4j2.properties
3.修改日志存放位置
[atguigu@hadoop102 conf]$ vim hive-log4j2.properties// 修改的配置
property.hive.log.dir=/opt/module/hive/log
3.修改JVM堆内存设置
HIVE默认申请256M,需要改大
修改$HIVE_HOME/conf下的hive-env.sh.template为hive-env.sh
[atguigu@hadoop102 conf]$ pwd
/opt/module/hive/conf[atguigu@hadoop102 conf]$ mv hive-env.sh.template hive-env.sh
将hive-env.sh其中的参数 export HADOOP_HEAPSIZE修改为2048,重启Hive
# The heap size of the jvm stared by hive shell script can be controlled via:
export HADOOP_HEAPSIZE=2048
4.关闭HADOOP虚拟内存检查
什么是虚拟内存??虚拟内存就是当内存不够使用时, 将一部分硬件的物理磁盘拿出来当做内存,就叫虚拟内存.其实没啥用,
这个需要设置YARN,因为yarn是负责内存调度的 yarn-site.xml
<property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value>
</property>