医疗器械网上商城太原seo团队

进入正文前,感谢宝子们订阅专题、点赞、评论、收藏!关注IT贫道,获取高质量博客内容!
🏡个人主页:含各种IT体系技术,IT贫道_Apache Doris,Kerberos安全认证,大数据OLAP体系技术栈-CSDN博客
📌订阅:拥抱独家专题,你的订阅将点燃我的创作热情!
👍点赞:赞同优秀创作,你的点赞是对我创作最大的认可!
⭐️ 收藏:收藏原创博文,让我们一起打造IT界的荣耀与辉煌!
✏️评论:留下心声墨迹,你的评论将是我努力改进的方向!
目录
Log系列表引擎
1. TinyLog
2. StripeLog
3. Log
MySQL的数据表有InnoDB和MyISAM存储引擎,不同的存储引擎提供不同的存储机制、索引方式等功能,也可以称之为表类型。在ClickHouse中也有表引擎。
表引擎在ClickHouse中的作用十分关键,直接决定了数据如何存储和读取、是否支持并发读写、是否支持index索引、支持的query种类、是否支持主备复制等。
ClickHouse提供了大约28种表引擎,各有各的用途,比如有Log系列用来做小表数据分析,MergeTree系列用来做大数据量分析,而Integration系列则多用于外表数据集成。再考虑复制表Replicated系列,分布式表Distributed等,纷繁复杂。
ClickHouse表引擎一共分为四个系列,分别是Log系列、MergeTree系列、Integration系列、Special系列。其中包含了两种特殊的表引擎Replicated、Distributed,功能上与其他表引擎正交,根据场景组合使用。
Log系列表引擎
Log系列表引擎功能相对简单,主要用于快速写入小表(1百万行左右的表),然后全部读出的场景,即一次写入,多次查询。Log系列表引擎包含:TinyLog、StripeLog、Log三种引擎。
- 几种Log表引擎的共性是:
- 数据被顺序append写到本地磁盘上。
- 不支持delete、update修改数据。
- 不支持index(索引)。
- 不支持原子性写。如果某些操作(异常的服务器关闭)中断了写操作,则可能会获得带有损坏数据的表。
- insert会阻塞select操作。当向表中写入数据时,针对这张表的查询会被阻塞,直至写入动作结束。
- 它们彼此之间的区别是:
- TinyLog:不支持并发读取数据文件,查询性能较差;格式简单,适合用来暂存中间数据。
- StripLog:支持并发读取数据文件,查询性能比TinyLog好;将所有列存储在同一个大文件中,减少了文件个数。
- Log:支持并发读取数据文件,查询性能比TinyLog好;每个列会单独存储在一个独立文件中。
1. TinyLog
TinyLog是Log系列引擎中功能简单、性能较低的引擎。
它的存储结构由数据文件和元数据两部分组成。其中,数据文件是按列独立存储的,也就是说每一个列字段都对应一个文件。
由于TinyLog数据存储不分块,所以不支持并发数据读取,该引擎适合一次写入,多次读取的场景,对于处理小批量中间表的数据可以使用该引擎,这种引擎会有大量小文件,性能会低。
- 示例:
#在ch中创建库 newdb,并使用node1 :) create database newdb;node1 :) use newdb;#创建表t_tinylog 表,使用TinyLog引擎node1 :) create table t_tinylog(id UInt8,name String,age UInt8) engine=TinyLog;#向表中插入数据node1 :) insert into t_tinylog values (1,'张三',18),(2,'李四',19),(3,'王五',20);#查询表中的数据node1 :) select * from t_tinylog;SELECT *FROM t_tinylog┌─id─┬─name─┬─age─┐│ 1 │ 张三 │ 18 ││ 2 │ 李四 │ 19 │ │ 3 │ 王五 │ 20 │└────┴──────┴─────┘3 rows in set. Elapsed: 0.003 sec.#在表中删除一条数据,这里是不支持delete。node1 :) delete from t_tinylog where id = 1;//语句不适合CHnode1 :) alter table t_tinylog delete where id = 1;:Exception: Mutations are not supported by storage TinyLog.当在newdb库中创建表t_tinylog后,在ClickHouse保存数据的目录/var/lib/clickhouse/data/newdb/下会多一个t_tinylog目录,如图所示:

在向表t_tinylog中插入数据后,进入“t_tinylog”目录,查看目录下的文件,如下图所示:

我们可以发现,表t_tinylog中的每个列都单独对应一个*.bin文件,同时还有一个sizes.json文件存储元数据,记录了每个bin文件中数据大小。
2. StripeLog
相比TinyLog而言,StripeLog数据存储会划分块,每次插入对应一个数据块,拥有更高的查询性能(拥有.mrk标记文件,支持并行查询)。StripeLog 引擎将所有列存储在一个文件中,使用了更少的文件描述符。对每一次 Insert 请求,ClickHouse 将数据块追加在表文件的末尾,逐列写入。StripeLog 引擎不支持 ALTER UPDATE 和 ALTER DELETE 操作。
- 示例:
#在库 newdb中创建表 t_stripelog,使用StripeLog引擎node1 :) create table t_stripelog(id UInt8,name String,age UInt8) engine = StripeLog;#向表t_stripelog中插入数据,这里插入分多次插入,会将数据插入不同的数据块中node1 :) insert into t_stripelog values (1,'张三',18);node1 :) insert into t_stripelog values (2,'李四',19);#查询表 t_stripelog数据node1 :) select * from t_stripelog;SELECT *FROM t_stripelog┌─id─┬─name─┬─age─┐│ 1 │ 张三 │ 18 │└────┴──────┴─────┘┌─id─┬─name─┬─age─┐│ 2 │ 李四 │ 19 │└────┴──────┴─────┘2 rows in set. Elapsed: 0.003 sec.当在newdb库中创建表 t_stripelog后,在ClickHouse保存数据的目录/var/lib/clickhouse/data/newdb/下会多一个t_stripelog目录,如图所示:
![]()
在向表t_stripelog中插入数据后,进入“t_stripelog”目录,查看目录下的文件,如下图所示:

我们可以发现只有三个文件:
- data.bin:数据文件,所有列字段都写入data.bin文件中。
- index.mrk:数据标记文件,保存了数据在data.bin 文件中的位置信息,即每个插入数据列的offset信息,利用数据标记能够使用多个线程,并行度取data.bin压缩数据,提升查询性能。
- sizes.json:元数据文件,记录了data.bin和index.mrk大小信息。
3. Log
Log引擎表适用于临时数据,一次性写入、测试场景。Log引擎结合了TinyLog表引擎和StripeLog表引擎的长处,是Log系列引擎中性能最高的表引擎。
Log表引擎会将每一列都存在一个文件中,对于每一次的INSERT操作,会生成数据块,经测试,数据块个数与当前节点的core数一致。
- 示例:
#在newdb中创建表t_log 使用Log表引擎node1 :) create table t_log(id UInt8 ,name String ,age UInt8 ) engine = Log;#向表 t_log中插入数据,分多次插入,插入后数据存入数据块node1 :) insert into t_log values (1,'张三',18);node1 :) insert into t_log values (2,'李四',19);node1 :) insert into t_log values (3,'王五',20);node1 :) insert into t_log values (4,'马六',21);node1 :) insert into t_log values (5,'田七',22);#查询表t_log中的数据node1 :) select * from t_log;SELECT *FROM t_log┌─id─┬─name─┬─age─┐│ 1 │ 张三 │ 18 ││ 2 │ 李四 │ 19 │└────┴─────┴─────┘┌─id─┬─name─┬─age─┐│ 3 │ 王五 │ 20 ││ 4 │ 马六 │ 21 ││ 5 │ 田七 │ 22 │└────┴─────┴─────┘5 rows in set. Elapsed: 0.004 sec.当在newdb库中创建表 t_log后,在ClickHouse保存数据的目录/var/lib/clickhouse/data/newdb/下会多一个t_log目录,如图所示:
![]()
在向表t_log中插入数据后,进入“t_log”目录,查看目录下的文件,如下图所示:
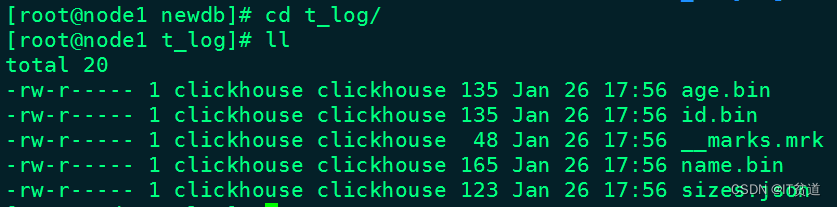
我们发现表t_log中的每个列都对应一个*.bin文件。其他两个文件的解释如下:
- __marks.mrk:数据标记,保存了每个列文件中的数据位置信息,利用数据标记能够使用多个线程,并行度取data.bin压缩数据,提升查询性能。
- sizes.json:记录了*.bin 和__mark.mrk大小的信息。
👨💻如需博文中的资料请私信博主。