门店管理系统推荐seo首页网站
一、PDF文件介绍
PDF是英文Portable Document Format缩写,就是可移植的意思,它是以PostScript语言图象模型为基础,无论在哪种打印机上都可保证精确的颜色和准确的打印效果,PostScript咱也不懂,估计和SVG的原理差不多吧。
二、PDF文件格式
PDF文件是二进制数据,可以用Sublime的HexViewer打开。
1、首部
指明文件PDF版本号,%PDF-1.4 其中最后一位 4就是文件格式的版本号。
2、文件体
PDF文件主要部分,由一系列obj对象组成,类似如下格式
3 0 obj <<........>>endobj# 3 对象编号 0 修改次数
3、交叉引用表
用于索引各个obj 对象在文档中的位置,以实现随机访问
xref.0 180000000000 65535 f0000010112 00000 n.....# 0000000000 第一对象起始地址,修改次数 65535#(最大修改次数,表示不可再改, f 表示free# 这里可以看成文件头)# 0000010112 第二对象超始地址,n表示对象正在使用
4、尾部
指明文件体根对象和交叉引用表地址
trailer.<</Info 17 0 R/ID [<df2c5533d0ab7c62ee7732a5e375592a><b07f35295e287c0a5febcad25060ccbf>]/Root 16 0 R/Size 18>>.startxref.83511.%%EOF.# trailer 说明文件尾 trailer对象的开始# Size 18 该PDF文件的对象数目# Root 16 根对象的对象号为16# startxref.83511 交叉引用表地f址
三、解析PDF文件
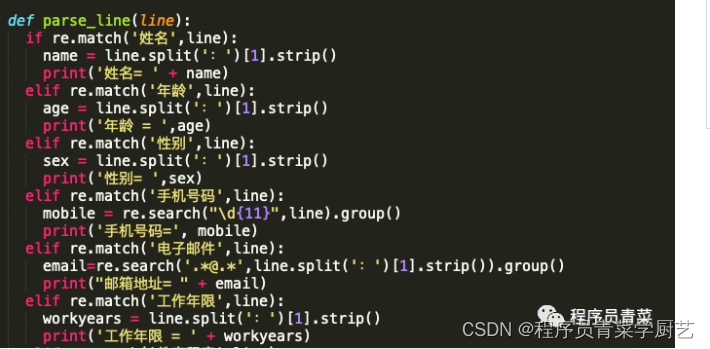
Java PdfBox、Python的Pdfminer都可以解析出PDF中的文本,但无论哪个工具都只能把PDF文本一行行打印出来,具体的字段解析还是要自己用正则去匹配。
下面介绍一下Python3的pdfminer3k
1、安装 pip install pdfminer3k
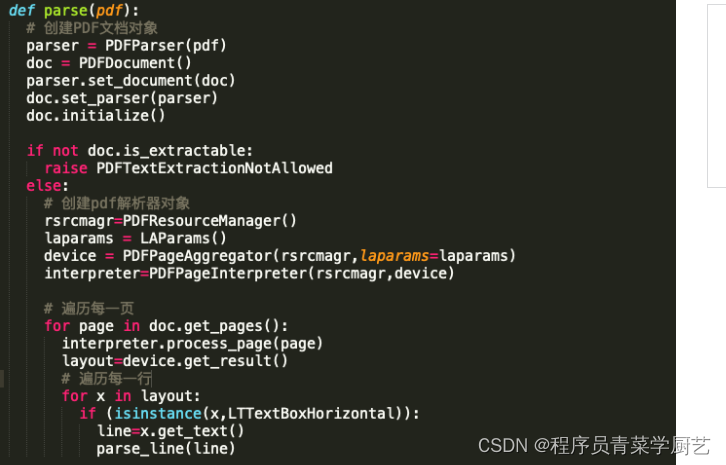
2、pdfminer3k几个主要类介绍
PDFParser:从PDF文件中提取数据PDFDocument:PDF文档对象PDFPageInterpreter:处理页面内容
下面是解析简历PDF数据,需要把关键信息提取出来,刚从网上找了些代码简单实现了一下,代码还没有做任何异常处理,先能跑通再说。
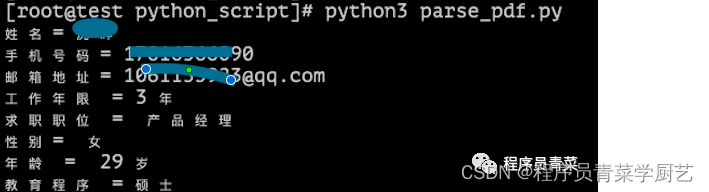
注:这代码对扫描版本的PDF是没有办法解析出来的。