急招程序员合肥360seo排名
从 RDD 转换得到 DataFrame
Saprk 提供了两种方法来实现从 RDD 转换得到 DataFrame:
- 利用反射机制推断 RDD 模式
- 使用编程方式定义 RDD 模式
下面使用到的数据 people.txt :
Tom, 21
Mike, 25
Andy, 181、利用反射机制推断 RDD 模式
在利用反射机制推断 RDD 模式的过程时,需要先定义一个 case 类,因为只有 case 类才能被 Spark 隐式地转换为DataFrame对象。
object Tese{// 反射机制推断必须使用 case 类,case class 必须放到main方法之外case class Person(name: String,age: Long) //定义一个case类def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[*]").appName("rdd to df 1").getOrCreate()import spark.implicits._ //这里的spark不是org.apache.spark这个包 而是我们创建的SparkSession对象 它支持把一个RDD隐式地转换为一个 DataFrame对象val rdd: RDD[Person] = spark.sparkContext.textFile("data/sql/people.txt").map(line => line.split(",")).map(t => Person(t(0), t(1).trim.toInt))// 将RDD对象转为DataFrame对象val df: DataFrame = rdd.toDF()df.createOrReplaceTempView("people")spark.sql("SELECT * FROM people WHERE age > 20").show()spark.stop()}
}注意事项1:
case 类必须放到伴生对象下,main方法之外,因为在隐式转换的时候它会自动通过 伴生对象名.case类名 来调用case类,如果放到main下面就找不到了。
注意事项2:
import spark.implicits._这里的spark不是org.apache.spark这个包 而是我们上面创建的SparkSession对象 它支持把一个RDD隐式地转换为一个 DataFrame对象
2、使用编程方式定义 RDD 模式
反射机制推断时需要定义 case class,但当无法定义 case 类时,就需要采用编程式来定义 RDD 模式了。这种方法看起来比较繁琐,但是很好用,不容易报错。
我们现在同样加载 people.txt 中的数据,生成 RDD 对象,再把RDD对象转为DataFrame对象,进行SparkSQL 查询。主要包括三个步骤:
- 制作表头 schema: StructType
- 制作表中记录 rowRDD: RDD[Row]
- 合并表头和记录 df:DataFramw
def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[*]").appName("rdd to df 2").getOrCreate()//1.制作表头-也就是定义表的模式val schema: StructType = StructType(Array(StructField("name", StringType, true),StructField("age", IntegerType, true)))//2.加载表中的记录-也就是读取文件生成RDDval rowRdd: RDD[Row] = spark.sparkContext.textFile("data/sql/people.txt").map(_.split(",")).map(attr => Row(attr(0), attr(1).trim.toInt))//3.把表头和记录拼接在一起val peopleDF: DataFrame = spark.createDataFrame(rowRdd, schema)peopleDF.createOrReplaceTempView("people")spark.sql("SELECT * FROM people WHERE age > 20").show()spark.stop()}运行结果:
+----+---+
|name|age|
+----+---+
| Tom| 21|
|Mike| 25|
+----+---+Spark SQL读取数据库
导入依赖
根据自己本地的MySQL版本导入对应的驱动。
注意:mysql8.0版本在JDBC中的url是:" com.mysql.cj.jdbc.Driver "
<dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>8.0.31</version></dependency>读取 MySQL 中的数据
def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[*]").appName("jdbc spark sql").getOrCreate()val mysql: DataFrame = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/spark").option("driver", "com.mysql.cj.jdbc.Driver").option("dbtable", "student").option("user", "root").option("password", "Yan1029.").load()mysql.show()spark.stop()}运行结果:
默认显示整张表
+---+----+---+---+
| id|name|age|sex|
+---+----+---+---+
| 1| Tom| 21| 男|
| 2|Andy| 20| 女|
+---+----+---+---+向 MySQL 写入数据
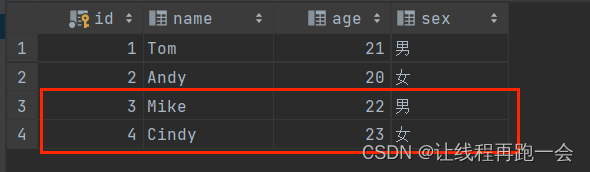
def main(args: Array[String]): Unit = {val spark = SparkSession.builder().master("local[*]").appName("jdbc spark sql").getOrCreate()//导入两条student信息val rdd: RDD[Array[String]] = spark.sparkContext.parallelize(Array("3 Mike 22 男", "4 Cindy 23 女")).map(_.split(" "))//设置模式信息-创建表头val schema: StructType = StructType(Array(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("age", IntegerType, true),StructField("sex", StringType, true)))//创建Row对象 每个 Row对象都是表中的一行-创建记录val rowRDD = rdd.map(stu => Row(stu(0).toInt, stu(1), stu(2).toInt, stu(3)))//创建DataFrame对象 拼接表头和记录val df = spark.createDataFrame(rowRDD, schema)//创建一个 prop 变量 用来保存 JDBC 连接参数val prop = new Properties()prop.put("user","root")prop.put("password","Yan1029.")prop.put("driver","com.mysql.cj.jdbc.Driver")//写入数据 采用 append 模式追加df.write.mode("append").jdbc("jdbc:mysql://localhost:3306/spark","spark.student",prop)spark.stop()}运行结果:
总结
今天上午就学到这里,本想着今天专门看看StructType、StructField和Row这三个类的,没想到就在这节课。这一篇主要学了RDD对象向DataFrame对象的转换以及Spark SQL如何读取数据库、写入数据库。
下午学完这一章最后的DataSet。