网站建设 图片上传网站项目开发流程
python操作文件
txt文件
- read() : 读取所有
- readline() : 读取一行
- readlines() : 读取所有,且以行为单位,放入list列表中
file = open(r"F:\abc.txt", "r", encoding="utf-8") # 以utf-8格式读取文件
# 读取所有
# print(file.read())# 读取一行
# print(file.readline())# 读取所有,且以行为单位,放入list列表中
lines = file.readlines()
for l in lines:print(l)
csv文件
CSV:逗号分隔值文件,其文件以纯文本形式存储表格数据,是自动化测试中常用的一种文件类型。
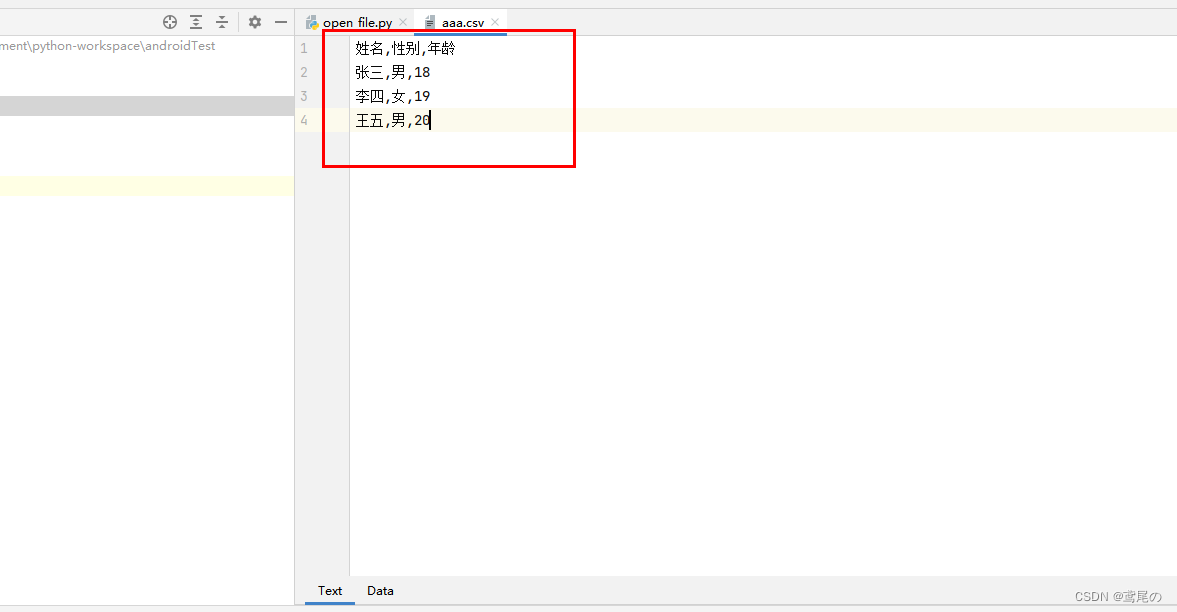
编写一个csv文件,内容如上,然后打开文件
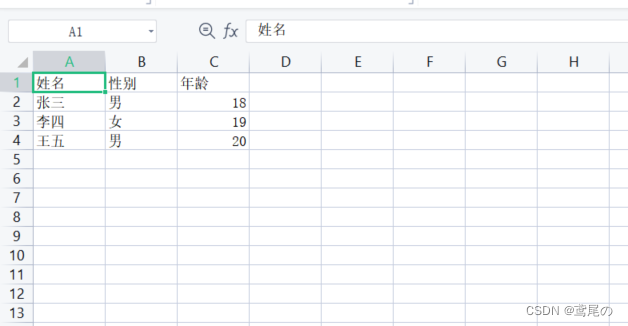
数据以表格的形式存储。
import csv
file = open("aaa.csv", "r", encoding="utf-8")
c = csv.reader(file)
for cs in c:print(cs)######################################################################################
['姓名', '性别', '年龄']
['张三', '男', '18']
['李四', '女', '19']
['王五', '男', '20']
Excel文件
excel是以二进制形式存储文件。
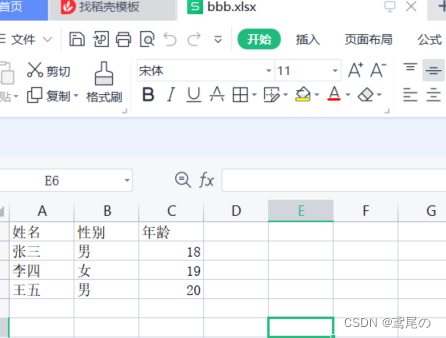
有一个excel文件,内容如上。
-
安装库,xlrd1.2.0版本支持 xlsx的文件
pip install xlrd==1.2.0 -
使用
import xlrdlsx = xlrd.open_workbook("bbb.xlsx") # 获取到第一个 sheet 页 sheet = lsx.sheet_by_index(0)# 获取行数 / 列数 print(sheet.nrows, sheet.ncols) # 拿取第一行 print(sheet.row_values(0))print("=========================================") # 拿取所有遍历 for i in range(sheet.nrows):print(sheet.row_values(i))
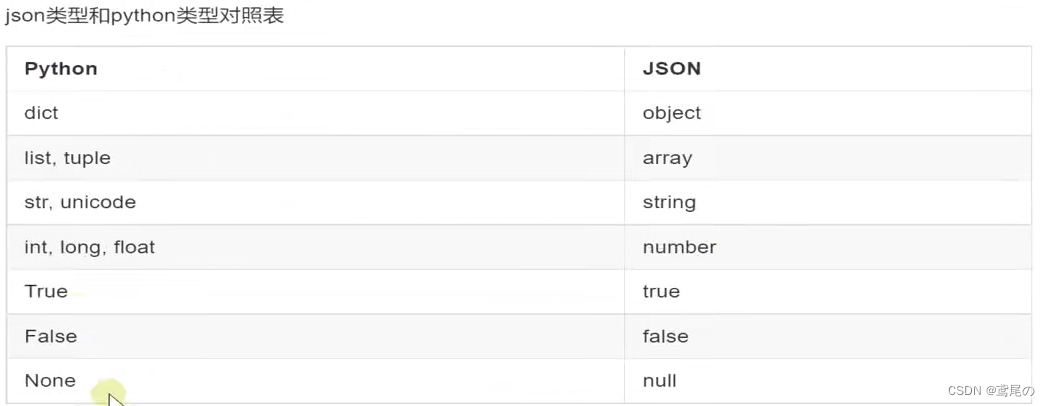
Json文件
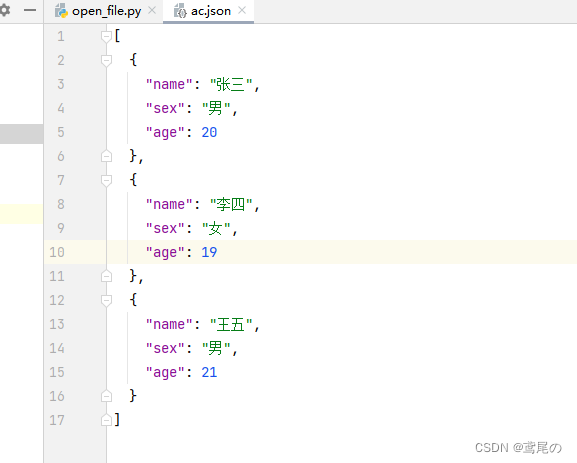
整理一个Json文件,然后代码读取这些数据
import jsonfile = open("ac.json", "r", encoding="utf-8")
# 注意:这里从文件中读取后,是字符串,不是json的对象
json_str = file.read()
json_obj = json.loads(json_str)
print(json_obj)print("+++++++++转换为json字符串++++++++")
# 转换为json字符串,不使用转码
js_str = json.dumps(json_obj, ensure_ascii=False)
print(js_str)[{'name': '张三', 'sex': '男', 'age': 20}, {'name': '李四', 'sex': '女', 'age': 19}, {'name': '王五', 'sex': '男', 'age': 21}]
+++++++++转换为json字符串++++++++
[{"name": "张三", "sex": "男", "age": 20}, {"name": "李四", "sex": "女", "age": 19}, {"name": "王五", "sex": "男", "age": 21}]
Xml文件
准备一个xml文件
<?xml version="1.0" encoding="utf-8" ?>
<bookstore><book category="COOKING"><title lang="en">Everyday Italian</title><author>Giada De Laurentiis</author><year>2005</year><price>30.00</price></book><book category="CHILDREN"><title lang="en">Harry Potter</title><author>J K. Rowling</author><year>2005</year><price>29.95</price></book>
</bookstore>
开始读取
# 导包
try:import xml.etree.cElementTree as ET
except:import xml.etree.ElementTree as ET# 解析 xml文件
tree = ET.parse("test.xml")
# 获取根节点
root = tree.getroot()print(root.tag) # 获取标签名
print(root.attrib) # 获取属性
print(root.text) # 获取标签文本for child in root:print(child.tag) # 获取标签名print(child.attrib) # 获取属性print(child.text) # 获取标签文本for children in child:print(children.tag) # 获取标签名print(children.attrib) # 获取属性print(children.text) # 获取标签文本
yaml文件
-
安装
pip install pyyaml -
使用
准备一个yml文件
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7gBVsePb-1678075419972)(imgs7/6.png)]](https://img-blog.csdnimg.cn/4741c7305485496aa68625ecb494c201.png)
转换为 python 对象
import yamlfile = open("test.yml", "r", encoding="utf-8") yaml_obj = yaml.load(file.read(), Loader=yaml.FullLoader) print(yaml_obj)################################################################ {'animal': 'pets', 'hash': {'name': 'steve', 'foo': 'bar'}, 'lists': ['Cat', 'Dog'], 'aris': [['Barry', 'Couch', 'Zara'], ['Anna', 'John']], 'dans': ['A', 'B', 'C']}