什么网站可以兼职做设计成都seo整站
SrpingBoot 集成 Solr 实现全文检索
一、核心路线
- 使用 Docker 镜像部署 Solr 8.11.3 版本服务
- 使用 ik 分词器用于处理中文分词
- 使用 spring-boot-starter-data-solr 实现增删改查
- 配置用户名密码认证
- 使用 poi 和 pdfbox 组件进行文本内容读取
- 文章最上方有源码和 ik 分词器资源
二、Solr Docker 镜像制作
由于 Solr 官方镜像无法通过环境变量直接配置用户名密码认证,所以选用第三方的 bitnami/solr 镜像作为基础,将 ik 分词器插件封装后得到新的镜像。
-
拉取
bitnami/solr镜像docker pull bitnami/solr:8.11.3 -
下载 ik 分词器 jar 包
ik-analyzer-8.5.0.jar -
编写 Dockerfile 文件
FROM bitnami/solr:8.11.3COPY ./ik-analyzer-8.5.0.jar /opt/bitnami/solr/server/solr-webapp/webapp/WEB-INF/lib/CMD ["/opt/bitnami/scripts/solr/run.sh"] -
构建镜像
docker build -t bitnami/solr:8.11.3-ik .
三、部署 Solr 服务
方式一:普通 docker 命令行部署
-
创建数据目录,例如
/home/solr-data -
启动容器
docker run -d -p 8983:8983 --name solr \-v /home/solr-data:/bitnami \-e SOLR_ENABLE_AUTHENTICATION=yes \-e SOLR_CORES=my_core \-e SOLR_ADMIN_USERNAME=admin \-e SOLR_ADMIN_PASSWORD=SolrPass \bitnami/solr:8.11.3-ik
方式二:Rancher 云平台部署
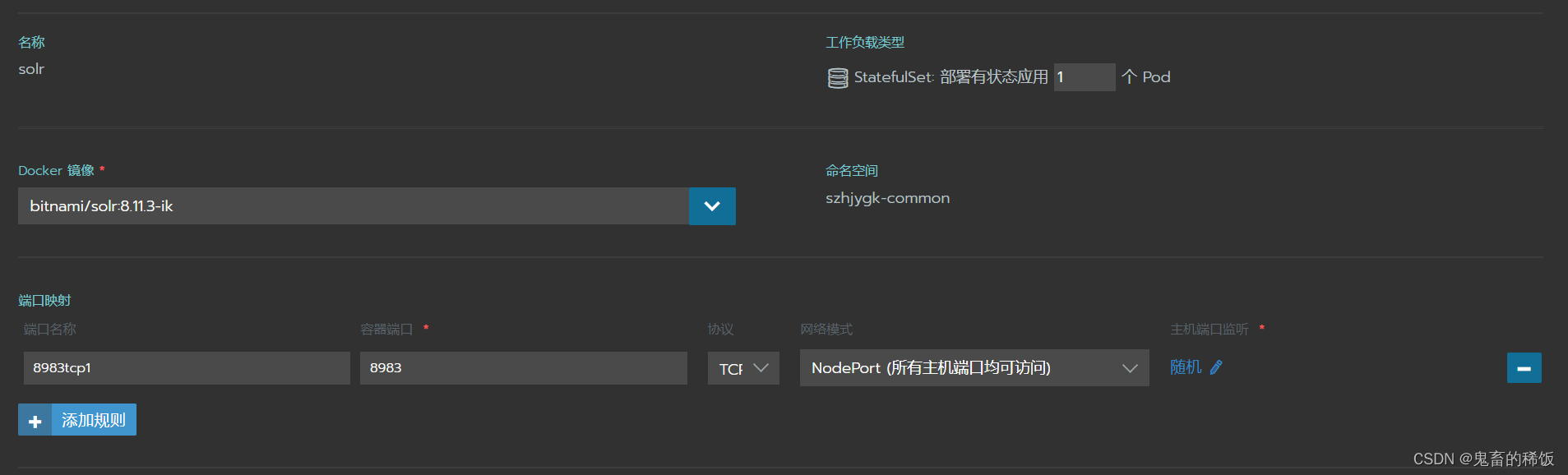



由于 solr 镜像默认使用 solr 用户启动容器,挂载的 pvc 没有写入权限,需要按照以下步骤进行:
-
以 UID=0 即 root 用户进行启动,并且入口 Entrypoint 使用 /bin/bash 覆盖默认启动命令,然后进入容器命令行
-
修改数据目录属主
chown -R solr:solr /bitnami/ -
去掉入口(Entrypoint)命令,用户 UID 设置为 1000 即 solr,重启工作负载即可
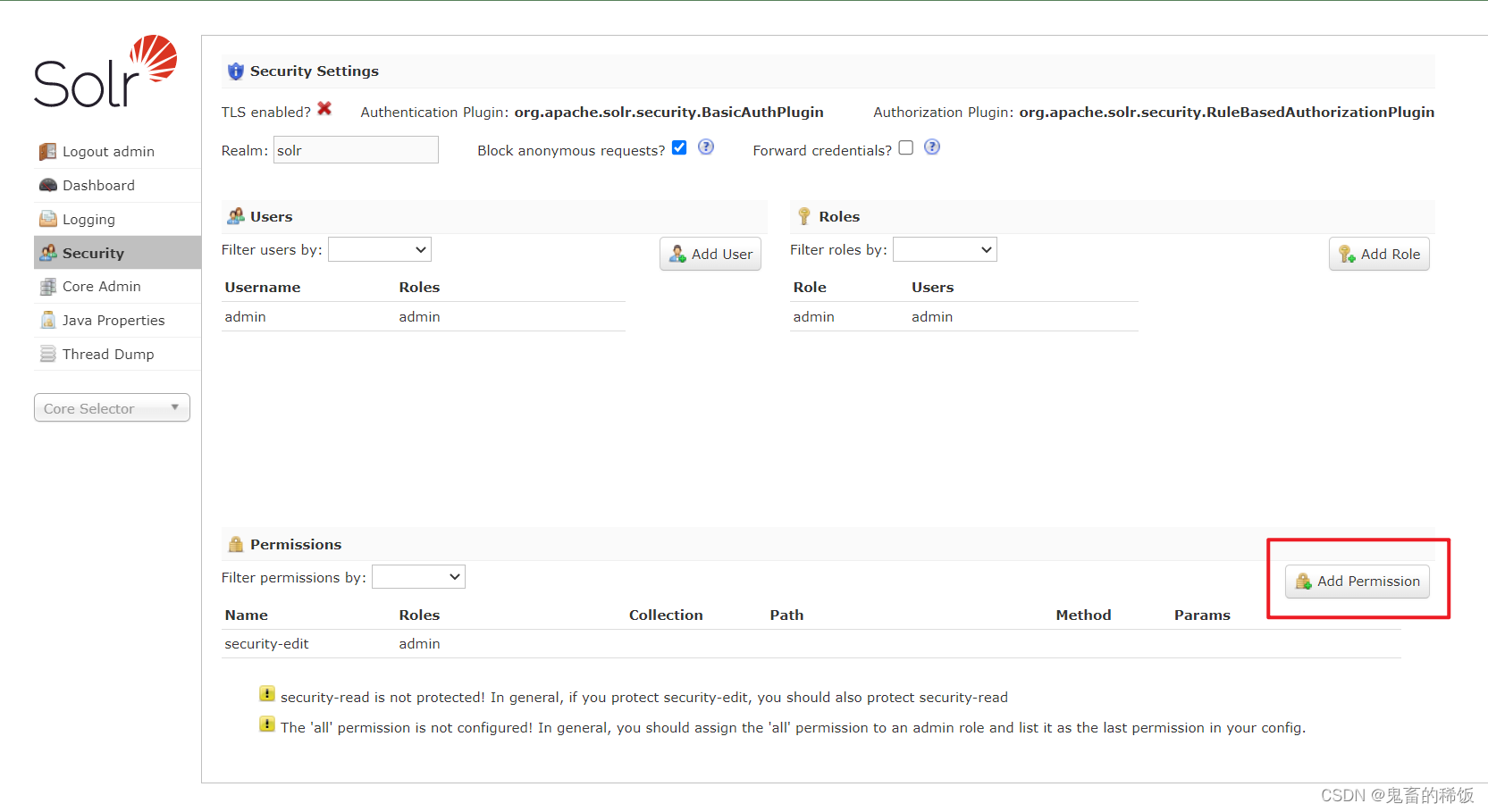
四、配置 Solr 用户权限
-
访问
http://localhost:8983即可打开 solr 控制台,输入账号密码admin/SolrPass登录认证 -
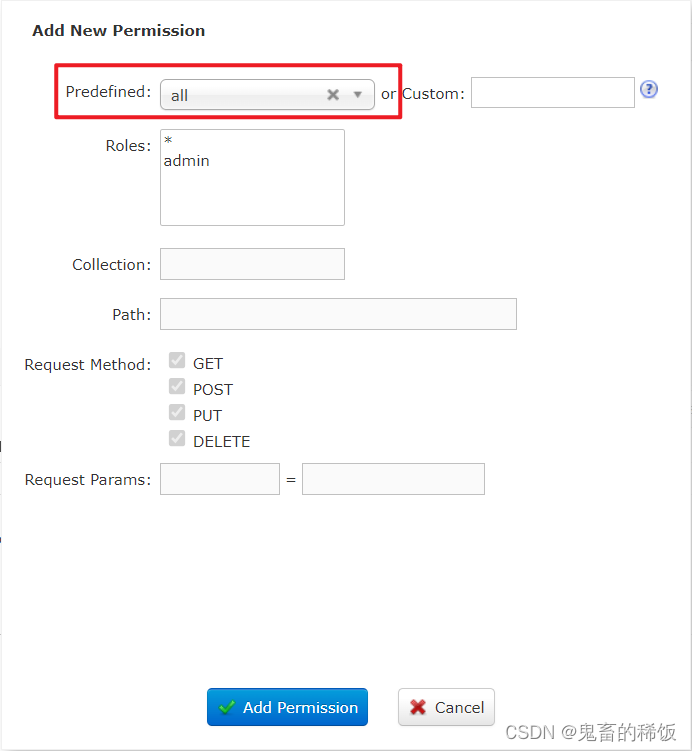
为了演示方便,直接给 admin 用户赋予全部权限
五、配置 my_core 的 ik 分词
编辑 /bitnami/solr/server/solr/my_core/conf/managed-schema 配置文件,追加以下配置内容:
<!--ik 分词插件配置--><fieldType name="text_ik" class="solr.TextField"><analyzer type="index"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="false"/><filter class="solr.LowerCaseFilterFactory"/></analyzer><analyzer type="query"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="true"/><filter class="solr.LowerCaseFilterFactory"/></analyzer></fieldType>
配置完成后重启 solr 容器。
六、创建 SpringBoot 工程
pom.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.3.4.RELEASE</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.example</groupId><artifactId>solr-example</artifactId><version>1.0-SNAPSHOT</version><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!--Solr--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-solr</artifactId></dependency><!--Solr 认证--><dependency><groupId>commons-codec</groupId><artifactId>commons-codec</artifactId></dependency><!--读取 docx 文档内容--><dependency><groupId>org.apache.poi</groupId><artifactId>poi</artifactId><version>5.2.2</version></dependency><dependency><groupId>org.apache.poi</groupId><artifactId>poi-ooxml</artifactId><version>5.2.2</version></dependency><!--读取 doc 文档内容--><dependency><groupId>org.apache.poi</groupId><artifactId>poi-scratchpad</artifactId><version>5.2.2</version></dependency><!--读取 PDF 文档内容--><dependency><groupId>org.apache.pdfbox</groupId><artifactId>pdfbox</artifactId><version>2.0.26</version></dependency><!--Hutool 工具类--><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.8.2</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency></dependencies><build><finalName>${project.artifactId}</finalName><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><version>2.3.3.RELEASE</version><executions><execution><phase>package</phase><goals><goal>repackage</goal><!--可以把依赖的包都打包到生成的Jar包中--></goals></execution></executions></plugin></plugins></build></project>配置文件
server:port: 18888
spring:servlet:# 文件上传配置multipart:enabled: truemax-file-size: 100MBmax-request-size: 100MBdata:solr:host: http://localhost:8983/solr # solr 服务地址username: admin # solr 用户名password: SolrPass # solr 密码
工程启动类
package com.example.solr;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.data.solr.repository.config.EnableSolrRepositories;@EnableSolrRepositories // 启用 solr repository
@SpringBootApplication
public class SolrExampleApplication {public static void main(String[] args) {SpringApplication.run(SolrExampleApplication.class, args);}
}SolrConfig 配置类
该类用于配置 Solr 认证
import org.apache.http.HttpHost;
import org.apache.http.HttpRequest;
import org.apache.http.HttpRequestInterceptor;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.AuthState;
import org.apache.http.auth.Credentials;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.client.protocol.HttpClientContext;
import org.apache.http.impl.auth.BasicScheme;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.http.protocol.HttpContext;
import org.apache.http.protocol.HttpCoreContext;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.net.URI;@Configuration
public class SolrConfig {@Value("${spring.data.solr.username}")private String username;@Value("${spring.data.solr.password}")private String password;@Value("${spring.data.solr.host}")private String uri;/**** 配置 solr 账号密码*/@Beanpublic HttpSolrClient solrClient() {CredentialsProvider provider = new BasicCredentialsProvider();final URI uri = URI.create(this.uri);provider.setCredentials(new AuthScope(uri.getHost(), uri.getPort()),new UsernamePasswordCredentials(this.username, this.password));HttpClientBuilder builder = HttpClientBuilder.create();// 指定拦截器,用于设置认证信息builder.addInterceptorFirst(new SolrAuthInterceptor());builder.setDefaultCredentialsProvider(provider);CloseableHttpClient httpClient = builder.build();return new HttpSolrClient.Builder(this.uri).withHttpClient(httpClient).build();}public static class SolrAuthInterceptor implements HttpRequestInterceptor {@Overridepublic void process(final HttpRequest request, final HttpContext context) {AuthState authState = (AuthState) context.getAttribute(HttpClientContext.TARGET_AUTH_STATE);if (authState.getAuthScheme() == null) {CredentialsProvider provider =(CredentialsProvider) context.getAttribute(HttpClientContext.CREDS_PROVIDER);HttpHost httpHost = (HttpHost) context.getAttribute(HttpCoreContext.HTTP_TARGET_HOST);AuthScope scope = new AuthScope(httpHost.getHostName(), httpHost.getPort());Credentials credentials = provider.getCredentials(scope);authState.update(new BasicScheme(), credentials);}}}
}MyDocument 实体类
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.apache.solr.client.solrj.beans.Field;
import org.springframework.data.annotation.Id;
import org.springframework.data.solr.core.mapping.Indexed;
import org.springframework.data.solr.core.mapping.SolrDocument;import java.io.Serializable;@Data
@NoArgsConstructor
@AllArgsConstructor
@SolrDocument(collection = "my_core") // 此处配置 core 信息
public class MyDocument implements Serializable {@Id@Fieldprivate String id;// 使用 string 类型即不进行分词@Indexed(name = "type", type = "string")private String type;// 使用 text_ik 类型即使用 ik 分词器进行分词索引和查询@Indexed(name = "title", type = "text_ik")private String title;// 使用 text_ik 类型即使用 ik 分词器进行分词索引和查询@Indexed(name = "content", type = "text_ik")private String content;
}
MyDocumentRepository 类
该类用于和 solr 服务进行通信,实现增删改查操作。
import com.example.solr.entity.MyDocument;
import org.springframework.data.domain.Pageable;
import org.springframework.data.solr.core.query.result.HighlightPage;
import org.springframework.data.solr.repository.Highlight;
import org.springframework.data.solr.repository.Query;
import org.springframework.data.solr.repository.SolrCrudRepository;import java.util.List;public interface MyDocumentRepository extends SolrCrudRepository<MyDocument, String> {/*** 按类型进行查询** @param type 类型* @return 查询结果*/@Query("type:?0")List<MyDocument> findAllByType(String type);/*** 按照标题或内容进行模糊查询,并且对关键词进行高亮标记* snipplets = 3 用于指定查询出符合条件的结果数,不指定则只能查出一条** @param title 标题关键词* @param content 内容关键词* @param pageable 分页对象* @return 带有高亮标记的查询结果*/@Highlight(snipplets = 3, fields = {"title", "content"}, prefix = "<span style='color:red'>", postfix = "</span>")HighlightPage<MyDocument> findAllByTitleOrContent(String title, String content, Pageable pageable);
}
MyDocumentService 类
import com.example.solr.entity.MyDocument;
import org.springframework.data.domain.Pageable;import java.util.List;
import java.util.Map;public interface MyDocumentService {MyDocument save(MyDocument document);void saveAll(List<MyDocument> documentList);void delete(String id);MyDocument findById(String id);List<MyDocument> findAllByType(String type);List<Map<String, Object>> findAllByTitleOrContent(String searchItem, Pageable pageable);
}
对应的实现类
import com.example.solr.entity.MyDocument;
import com.example.solr.repository.MyDocumentRepository;
import com.example.solr.service.MyDocumentService;
import org.springframework.data.domain.Pageable;
import org.springframework.data.solr.core.query.result.HighlightEntry;
import org.springframework.data.solr.core.query.result.HighlightPage;
import org.springframework.stereotype.Service;import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;@Service
public class MyDocumentServiceImpl implements MyDocumentService {@Resourceprivate MyDocumentRepository repository;@Overridepublic MyDocument save(MyDocument document) {return repository.save(document);}@Overridepublic void saveAll(List<MyDocument> documentList) {repository.saveAll(documentList);}@Overridepublic void delete(String id) {repository.delete(findById(id));}@Overridepublic MyDocument findById(String id) {return repository.findById(id).orElse(null);}@Overridepublic List<MyDocument> findAllByType(String type) {return repository.findAllByType(type);}@Overridepublic List<Map<String, Object>> findAllByTitleOrContent(String searchItem, Pageable pageable) {// 查询分页结果HighlightPage<MyDocument> page = repository.findAllByTitleOrContent(searchItem, searchItem, pageable);List<Map<String, Object>> result = new ArrayList<>();// 处理查询结果高亮片段for (HighlightEntry<MyDocument> highlight : page.getHighlighted()) {// 每个 map 对应一个文档Map<String, Object> map = new HashMap<>();MyDocument doc = highlight.getEntity();map.put("id", doc.getId());map.put("type", doc.getType());map.put("title", doc.getTitle());for (HighlightEntry.Highlight hl : highlight.getHighlights()) {map.put(hl.getField().getName(), hl.getSnipplets());}result.add(map);}return result;}
}
FileUtil 文件内容处理类
import cn.hutool.core.util.StrUtil;
import lombok.extern.slf4j.Slf4j;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
import org.apache.poi.hwpf.HWPFDocument;
import org.apache.poi.hwpf.extractor.WordExtractor;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.apache.poi.xwpf.usermodel.XWPFRun;
import org.springframework.web.multipart.MultipartFile;import java.io.IOException;
import java.io.InputStream;@Slf4j
public class FileUtil {/*** 读取文档内容* 目前仅支持 txt, doc, docx, pdf 格式** @param file 文件对象* @return 文档内容*/public static String readFileContent(MultipartFile file) {String filename = file.getOriginalFilename();assert filename != null;String fileType = filename.substring(filename.lastIndexOf(".") + 1).toUpperCase();switch (fileType) {case "TXT":return readTxtContent(file);case "DOC":case "DOCX":return readWordContent(file);case "PDF":return readPDFContent(file);default:return "";}}/*** 读取 txt 文档内容*/private static String readTxtContent(MultipartFile file) {try {return StrUtil.utf8Str(file.getBytes());} catch (IOException e) {e.printStackTrace();log.error("读取 txt 文件内容时发生 IO 异常");return "";}}/*** 读取 doc 和 docx 文档内容*/private static String readWordContent(MultipartFile file) {String filename = file.getOriginalFilename();assert filename != null;String fileType = filename.substring(filename.lastIndexOf(".") + 1);return "doc".equals(fileType) ? readDocContent(file) : readDocxContent(file);}/*** 读取 .doc 格式的 word 文档** @param file 文件对象* @return 文本内容*/private static String readDocContent(MultipartFile file) {StringBuilder content = new StringBuilder();try (InputStream inputStream = file.getInputStream();HWPFDocument document = new HWPFDocument(inputStream)) {WordExtractor extractor = new WordExtractor(document);String[] paragraphs = extractor.getParagraphText();for (String paragraph : paragraphs) {content.append(paragraph);}} catch (IOException e) {e.printStackTrace();log.error("读取文件内容时发生 IO 异常");}return content.toString();}/*** 读取 .docx 格式的 word 文档** @param file 文件对象* @return 文本内容*/private static String readDocxContent(MultipartFile file) {StringBuilder content = new StringBuilder();try (InputStream inputStream = file.getInputStream();XWPFDocument document = new XWPFDocument(inputStream)) {for (XWPFParagraph paragraph : document.getParagraphs()) {for (XWPFRun run : paragraph.getRuns()) {String runText = run.getText(0);if (runText != null) {content.append(runText);}}}} catch (IOException e) {e.printStackTrace();log.error("读取文件内容时发生 IO 异常");}return content.toString();}/*** 读取 pdf 文档内容*/private static String readPDFContent(MultipartFile file) {StringBuilder content = new StringBuilder();try (InputStream inputStream = file.getInputStream();PDDocument document = PDDocument.load(inputStream)) {// 检查是否是由文档转换出的 pdf 文件if (!document.isEncrypted() && document.getNumberOfPages() > 0) {PDFTextStripper textStripper = new PDFTextStripper();content.append(textStripper.getText(document));} else {log.warn("PDF 已加密或不是由文档转换的 PDF 格式,无法读取内容!");}} catch (IOException e) {e.printStackTrace();log.error("读取文件内容时发生 IO 异常");}return content.toString();}
}MyDocumentController 控制器类
package com.example.solr.controller;import com.example.solr.entity.MyDocument;
import com.example.solr.service.MyDocumentService;
import com.example.solr.util.FileUtil;
import org.springframework.data.domain.PageRequest;
import org.springframework.web.bind.annotation.*;
import org.springframework.web.multipart.MultipartFile;import javax.annotation.Resource;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.UUID;@RestController
@RequestMapping("/solr")
public class MyDocumentController {@Resourceprivate MyDocumentService documentService;/*** 上传文档文件,读取文档内容并写入 solr** @param file 上传的文档文件,仅支持读取以下格式的文件内容 txt, doc, docx, pdf(由文档转换生成的)* @param type 文件分类* @return 处理结果*/@PostMapping("/upload")public Map<String, Object> upload(@RequestPart("multipartFile") MultipartFile file, @RequestParam String type) {MyDocument doc = new MyDocument();doc.setId(UUID.randomUUID().toString());doc.setType(type);doc.setTitle(file.getOriginalFilename());doc.setContent(FileUtil.readFileContent(file));documentService.save(doc);Map<String, Object> result = new HashMap<>();result.put("result", true);result.put("data", doc);return result;}/*** 直接向 solr 添加内容** @param type 类型* @param title 标题* @param content 内容* @return 处理结果*/@PostMapping("/save")public Map<String, Object> save(@RequestParam String type, @RequestParam String title, @RequestParam String content) {MyDocument doc = new MyDocument();doc.setId(UUID.randomUUID().toString());doc.setType(type);doc.setTitle(title);doc.setContent(content);documentService.save(doc);Map<String, Object> result = new HashMap<>();result.put("result", true);result.put("data", doc);return result;}/*** 删除 solr 内容** @param id 主键* @return 处理结果*/@DeleteMapping("/delete")public Map<String, Object> delete(@RequestParam String id) {documentService.delete(id);Map<String, Object> result = new HashMap<>();result.put("result", true);result.put("data", null);return result;}/*** 根据标题或内容模糊搜索,并且高亮关键词** @param searchItem 搜索关键词* @param page 页码* @param size 每页数量* @return 查询结果*/@GetMapping("/searchTitleOrContent")public Map<String, Object> searchTitleOrContent(@RequestParam String searchItem, @RequestParam Integer page,@RequestParam Integer size) {List<Map<String, Object>> data = documentService.findAllByTitleOrContent(searchItem, PageRequest.of(page, size));Map<String, Object> result = new HashMap<>();result.put("result", true);result.put("data", data);return result;}/*** 根据类型搜索** @param type 类型* @return 查询结果*/@GetMapping("/searchType")public Map<String, Object> searchType(@RequestParam String type) {List<MyDocument> data = documentService.findAllByType(type);Map<String, Object> result = new HashMap<>();result.put("result", true);result.put("data", data);return result;}
}七、验证
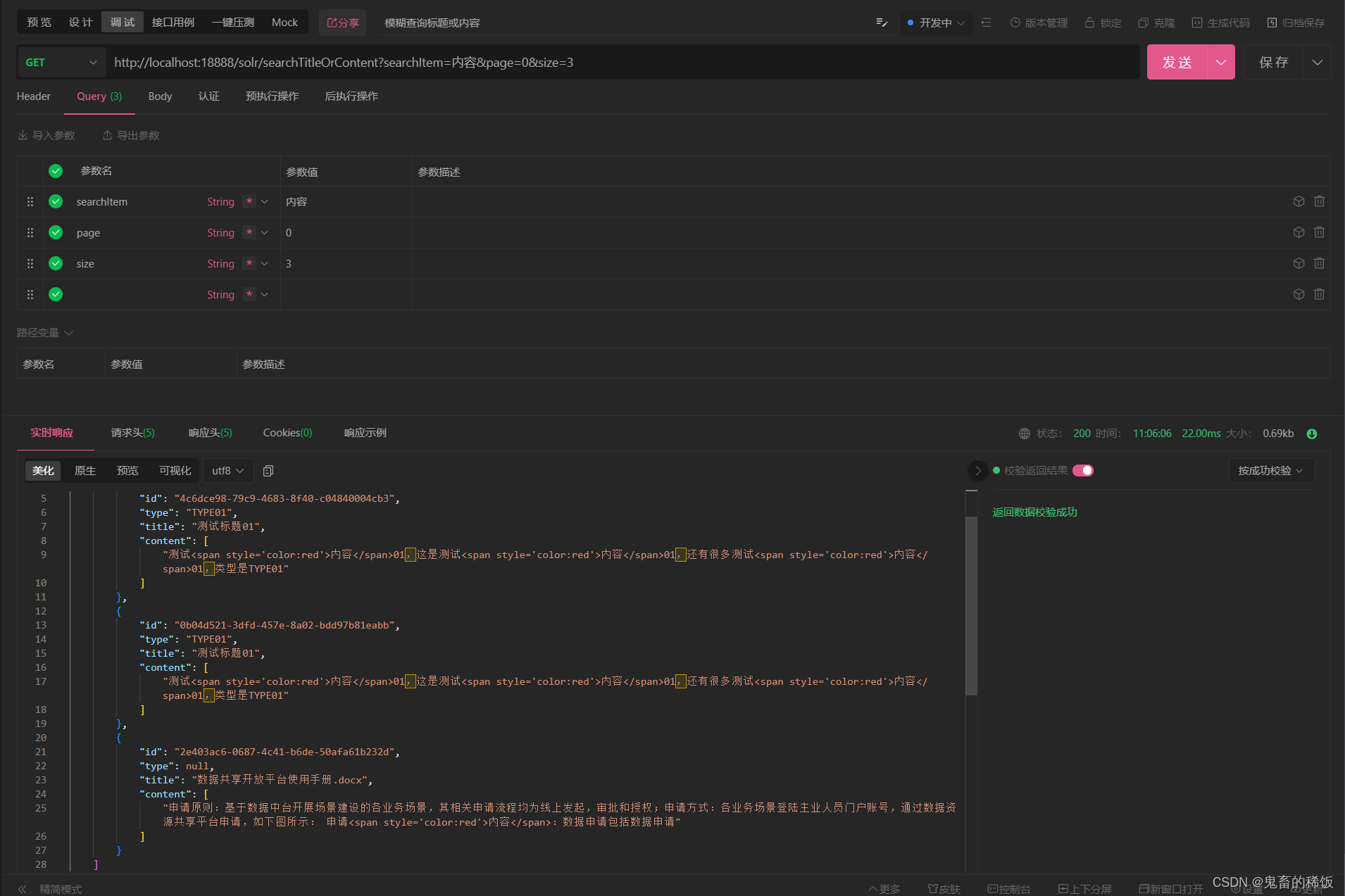
启动服务,使用 postman 等工具进行接口请求。
1. 直接写入 solr 内容

2. 上传 word 文档读取内容写入 solr

3. 根据类型精确查询

4. 根据标题或内容模糊查询