招商加盟网站建设目的关键词搜索挖掘爱网站
【大数据处理与可视化】三 、Pandas库的运用
- 实验目的
- 实验内容
- 实验步骤
- 一、使用pandas库分别创建Series对象和DataFrame对象,并对创建的对象使用索引、排序等相关操作;练习DataFrame对象的统计计算和统计描述的功能。
- 1&2、创建一个DataFrame(df),用data做数据,labels做行索引,显示有关此df及其数据的基本信息的摘要
- 3、查看此df的前三行数据
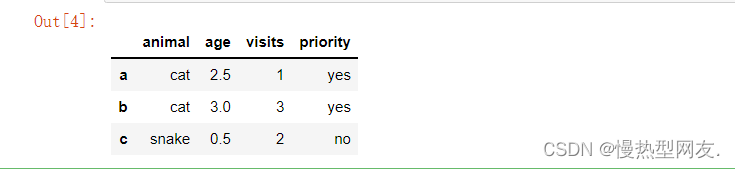
- 4、选择df中列标签为animal和age的数据
- 5、选择行为[‘d’, ‘e’, ‘i’],且列为['animal', 'age']中的数据
- 6、选择visuts大于3的行
- 7、选择age为缺失值的行
- 8、选择animal为cat,且age小于3的行
- 9、将f行的age改为1.5
- 10、计算visits列的数据总和
- 11、计算每种animal的平均age
- 12、追加一行(k),列的数据自定义(如可以等于a行的数据),然后再删除新追加的k行
- 13、计算每种animal的个数(cat有几个,dog几个...)
- 14、先根据age降序排列,再根据visits升序排列
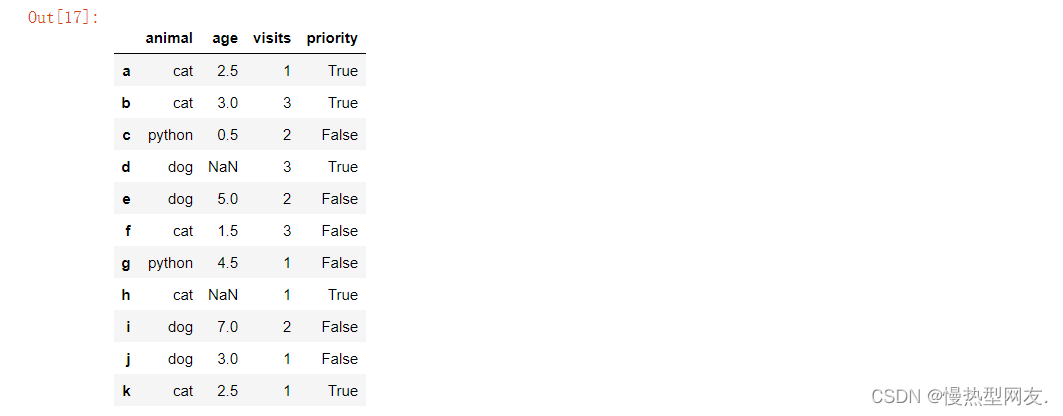
- 15、将priority列的yes和no用True和False替换
- 16、将animal列的snake用python替换
- 二、给定数据使用Pandas的基础知识对北京高考分数线统计分析,分析出:一本文理科与二本文理科最高的分数线是多少,最低的分数线是多少,相差多少分;求2006年-2008年近13年分数线平均分。
- 1、首先读取表格内容
- 2、通过sort_index()=方法让DataFrame对象按照从大到小的顺序排列
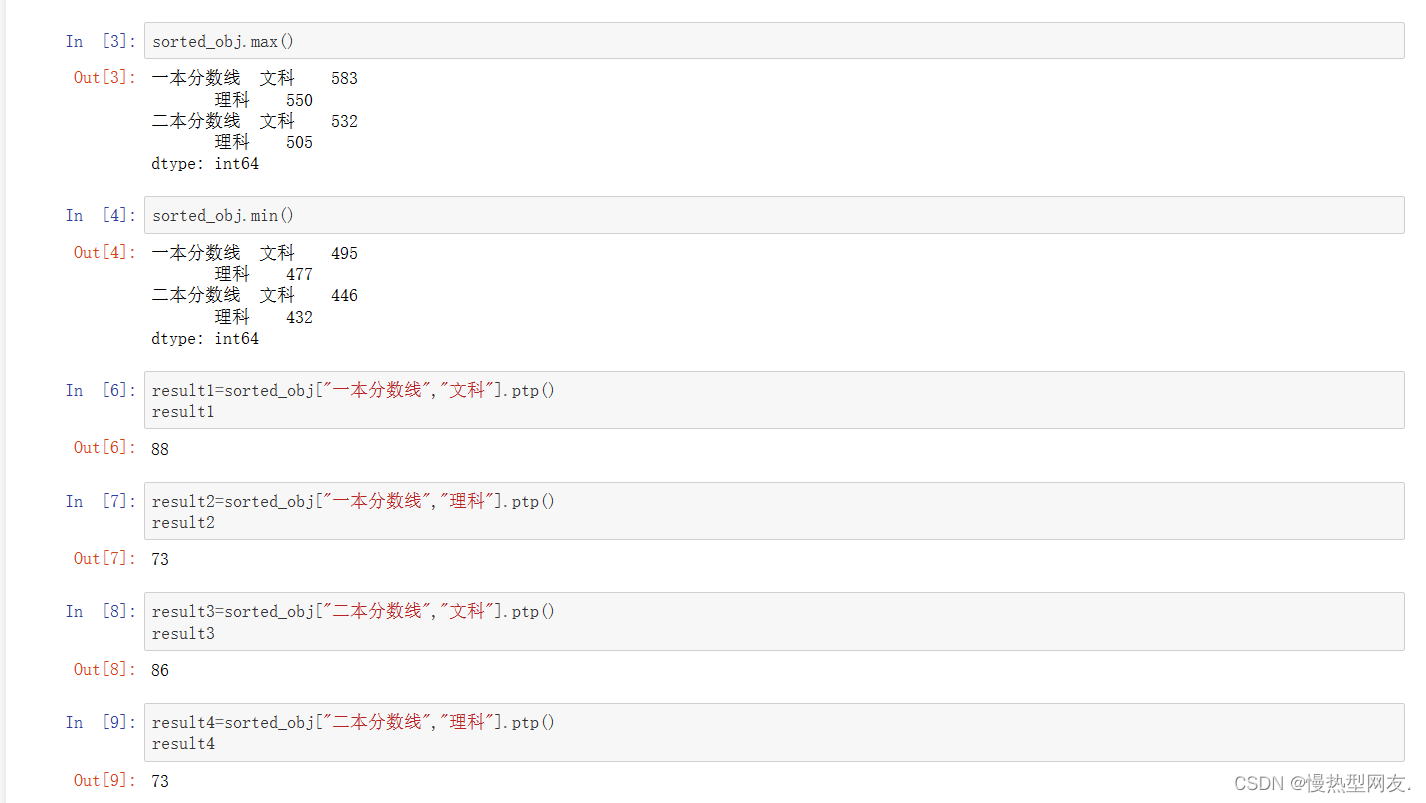
- 3、获取历年一本、二本文理科最高和最低的分数线及极差
- 4、比较2018年一本与二本文理科分数线的差值
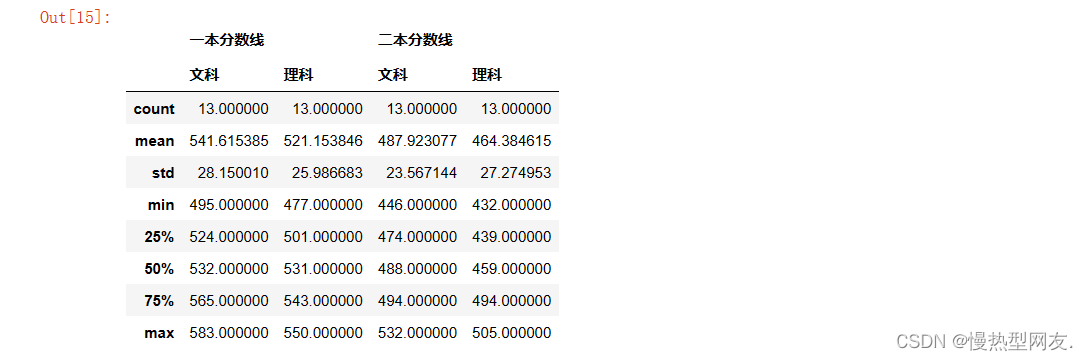
- 5、计算2006-2018年的平均分数线
- 实验小结
实验目的
- 能够熟练运用pandas库创建Series对象和DataFrame对象;
- 能够熟练运用Series对象和DataFrame对象的索引操作和排序操作;
- 能够熟练运用pandas库,进行统计计算和统计描述;
- 能够熟练运用pandas库进行读写数据操作
实验内容
一、使用pandas库分别创建Series对象和DataFrame对象,并对创建的对象使用索引、排序等相关操作;练习DataFrame对象的统计计算和统计描述的功能。
1、创建一个DataFrame(df),用data做数据,labels做行索引
2、显示有关此df及其数据的基本信息的摘
3、查看此df的前三行数据
4、选择df中列标签为animal和age的数据
5、选择行为[‘d’, ‘e’, ‘i’],且列为[‘animal’, ‘age’]中的数据
6、选择visuts大于3的行
7、选择age为缺失值的行
8、选择animal为cat,且age小于3的行
9、将f行的age改为1.5
10、计算visits列的数据总和
11、计算每种animal的平均age
12、追加一行(k),列的数据自定义(如可以等于a行的数据),然后再删除新追加的k行
13、计算每种animal的个数(cat有几个,dog几个…)
14、先根据age降序排列,再根据visits升序排列
15、将priority列的yes和no用True和False替换
16、将animal列的snake用python替换
二、给定数据使用Pandas的基础知识对北京高考分数线统计分析,分析出:一本文理科与二本文理科最高的分数线是多少,最低的分数线是多少,相差多少分;求2006年-2008年近13年分数线平均分。
实验步骤
一、使用pandas库分别创建Series对象和DataFrame对象,并对创建的对象使用索引、排序等相关操作;练习DataFrame对象的统计计算和统计描述的功能。
1&2、创建一个DataFrame(df),用data做数据,labels做行索引,显示有关此df及其数据的基本信息的摘要
代码:
import pandas as pd
import numpy as np
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
data = {'animal': pd.Series(['cat', 'cat', 'snake', 'dog', 'dog', 'cat', 'snake', 'cat', 'dog', 'dog'],index=labels),'age': pd.Series([2.5, 3, 0.5, np.nan, 5, 2, 4.5, np.nan, 7, 3],index=labels),'visits': pd.Series([1, 3, 2, 3, 2, 3, 1, 1, 2, 1],index=labels),'priority': pd.Series(['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no'],index=labels)}
df = pd.DataFrame(data)
df
截图:

3、查看此df的前三行数据
代码:df[0:3]
截图:
4、选择df中列标签为animal和age的数据
代码:df[['animal','age']]
截图:

5、选择行为[‘d’, ‘e’, ‘i’],且列为[‘animal’, ‘age’]中的数据
代码:df.loc[['d','e','i'],['animal','age']]
截图:

6、选择visuts大于3的行
代码:
visits_bool = df['visits']>3
df[visits_bool]
截图:

7、选择age为缺失值的行
代码:
age_bool = df['age'].isnull()
df[age_bool]
截图:

8、选择animal为cat,且age小于3的行
代码:df[(df['animal']=="cat")&(df["age"]<3)]
截图:

9、将f行的age改为1.5
代码:
df.loc[['f'],['age']] = 1.5
df
截图:

10、计算visits列的数据总和
代码:sum(df['visits'])
截图:

11、计算每种animal的平均age
代码:df.groupby('animal')['age'].mean()
截图:

12、追加一行(k),列的数据自定义(如可以等于a行的数据),然后再删除新追加的k行
代码:
df.loc['k']=df.loc['a'].values
df
df.drop('k')
截图:

13、计算每种animal的个数(cat有几个,dog几个…)
代码:df.groupby('animal').size()
截图:

14、先根据age降序排列,再根据visits升序排列
代码:df.sort_values(by=['age', 'visits'], ascending=[False, True])
截图:

15、将priority列的yes和no用True和False替换
代码:
df['priority'] = df['priority'].replace(to_replace=['yes', 'no'], value=[True, False])
df
截图:

16、将animal列的snake用python替换
代码:
df['animal'] = df['animal'].replace(to_replace='snake', value='python')
df
截图:
二、给定数据使用Pandas的基础知识对北京高考分数线统计分析,分析出:一本文理科与二本文理科最高的分数线是多少,最低的分数线是多少,相差多少分;求2006年-2008年近13年分数线平均分。
1、首先读取表格内容
代码:
import pandas as pd
df_obj=pd.read_excel('D:/scores.xlsx',header=[0,1])
df_obj
截图:

2、通过sort_index()=方法让DataFrame对象按照从大到小的顺序排列
代码:
sorted_obj=df_obj.sort_index(ascending=False)
sorted_obj
截图:

3、获取历年一本、二本文理科最高和最低的分数线及极差
代码:
sorted_obj.max()
sorted_obj.min()
result1=sorted_obj["一本分数线","文科"].ptp()
result1
result2=sorted_obj["一本分数线","理科"].ptp()
result2
result3=sorted_obj["二本分数线","文科"].ptp()
result3
result4=sorted_obj["二本分数线","理科"].ptp()
result4
截图:
4、比较2018年一本与二本文理科分数线的差值
代码:
ser_obj1=sorted_obj["一本分数线","文科"]
ser_obj1[2018] - ser_obj1[2017]ser_obj2=sorted_obj["一本分数线","理科"]
ser_obj2[2018] - ser_obj2[2017]ser_obj3=sorted_obj["二本分数线","文科"]
ser_obj3[2018] - ser_obj3[2017]ser_obj4=sorted_obj["二本分数线","理科"]
ser_obj4[2018] - ser_obj4[2017]
截图:

5、计算2006-2018年的平均分数线
代码:sorted_obj.describe()
截图:
实验小结
通过本次实验,我了解了科学计算库Pandas,包括Pandas常用的数据结构、索引的相关操作、算术运算、文件的读取操作等。在实验过程中遇到了很多硬件或者是软件上的问题,请教老师,询问同学,上网查资料,都是解决这些问题的途径。最终将遇到的问题一一解决最终完成实验。
注意事项:
1、有疑问前,知识学习前,先用搜索。
2、熟读写基础知识,学得会不如学得牢。
3、选择交流平台,如QQ群,网站论坛等。
4、尽我能力帮助他人,在帮助他人的同时你会深刻巩固知识。