福州网站建设制作首选荧光信息广东最新疫情
目录
- 1、数据挖掘概述
- 2、数据挖掘常用库
- 3、模型介绍
- 3.1 分类
- 3.2 聚类
- 3.3 回归
- 3.4 关联
- 3.5 模型集成
- 4、模型评估
- ROC 曲线
- 5、模型应用
1、数据挖掘概述
数据挖掘:寻找数据中隐含的知识并用于产生商业价值
数据挖掘产生原因:海量数据、维度众多、问题复杂
数据挖掘作用:
- 分类问题(该新闻是属于体育新闻还是娱乐新闻还是其他类型)
- 聚类问题(地上掉落的一堆树叶,哪些属于同一棵树)
- 回归问题(已知前几年的房价数据,预测明年的房价)
- 关联问题(推荐算法)
数据挖掘流程:
- 业务理解:和业务方充分沟通,明确需求
- 数据理解
- 数据准备
数据清洗:
.缺失值处理(删除、填充、不做处理)
.异常值处理:数据本身错误(记录时错误)、数据本身是正常的但不符号业务实际(某账号游戏充值10万)要对正常异常值保留甚至特别留意
.数据偏差:处理数据严重不对等不均衡情况
.特征选择:
构建训练集和测试集方法(留出法、交叉严重法、自助法)
- 构建模型
- 评估模型
- 模型部署
2、数据挖掘常用库
数学模块math
日期时间模块datetime
随机模块random
文件模块操作file
正则匹配模块re
系统接口模块sys
import math
dir(math) #查看math中所有方法名称
help(math) #match的描述,以及方法的介绍
3、模型介绍
3.1 分类
分类是有监督的学习过程。 处处理分类问题首先要有一批已经有标签结果的数据,经过分类算法的学习,
就可以预测新的未知数据的分类。
分类模型: KNN 算法、决策树算法、随机森林、SVM 等
3.2 聚类
聚类是无监督的,聚类就是把一个数据集划分成多个组的过程,使得组内的数据尽量高度集中,而和其他组的数据之间尽量远离。这种方法是针对已有的数据进行划分,不涉及未知的数据。
3.3 回归
回归:与分类问题十分相似,都是根据已知的数据去学习,然后为新的数据进行预测。但是不同的是,分类方法输出的是离散的标签,回归方法输出的结果是连续值
3.4 关联
关联问题对应的方法就是关联分析。这是一种无监督学习,关联分析是要在已有的数据中寻找出数据的相关关系。比如在我们津津乐道的啤酒与尿布
3.5 模型集成
模型集成也可以叫作集成学习,其思路就是去合并多个模型来提升整体的效果
训练多个并列的模型,或者串行地训练多个模型
模型集成的 3 种方式:
- Bagging(装袋法):多次随机抽样构建训练集,每构建一次,就训练一个模型,最后对多个模型的结果附加一层决策,使用平均结果作为最终结果。随机森林算法就运用了该方法
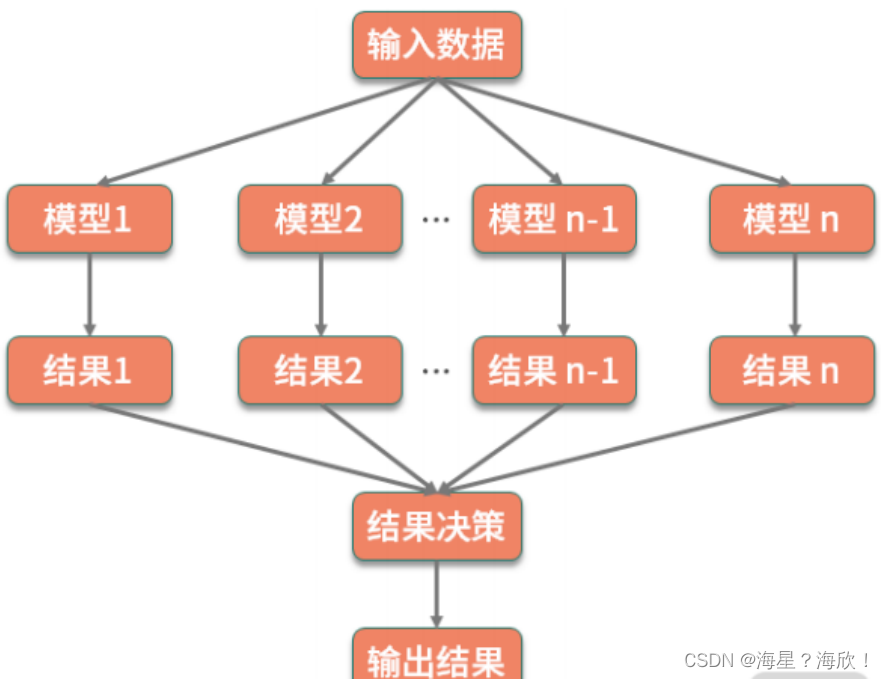
- Boosting(增强法):是串行的训练,即每次把上一次训练的结果也作为一个特征,不断地强化学习的效果。
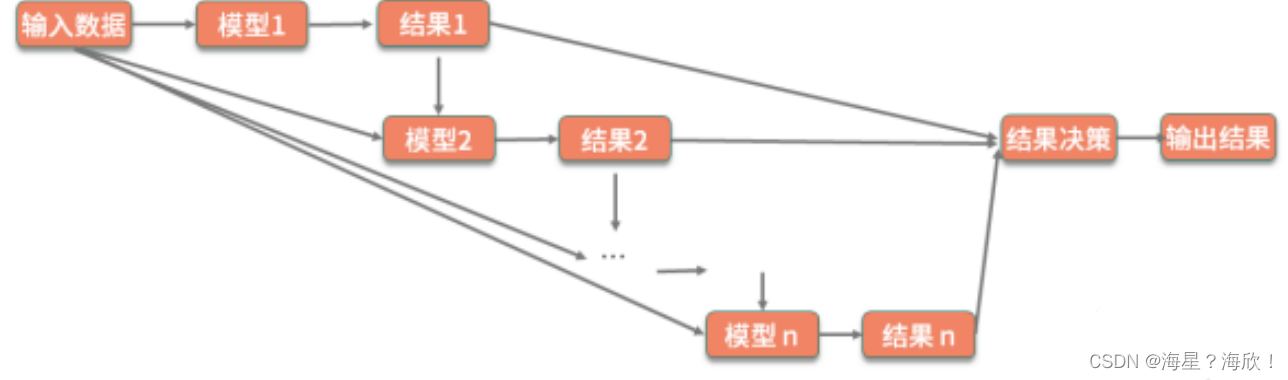
- Stacking(堆叠法):是对前面两种方法进行了扩展,训练的多个模型既可
以进行横向扩展,也可以进行串行增强,最终再使用分类或者回归的方法把前面模型的结果进行整合。
其中的每一个模型可以使用不同的算法,对于结构也没有特定的规则,真正是 “黑猫白猫,抓住老鼠就是好猫”。所以,在使用堆叠法时,就需要你在具体业务场景中不断地去进行尝试和优化,以达到最佳效果。
4、模型评估
模型评估就是对你的模型进行多种维度的评估,来确认你的模型是否可以应用。
准确率指标:
- TP(true positive)原本为真,且被预测为真
- TN(true negative)原本为真,但预测为假
- FP(false positive)原本为假,但被预测为真
- FN(false negative)原本为假,且预测为假
计算数值:
- 准确率:预测正确的比例 (TP+FN)/(TP+TN+FP+FN)
在所有样本中,预测正确的概率 - 精确率:在所有真的样本中被预测为真的比例 TP/(TP+FP)你认为的正样本中,有多少是真的正确的概率
- 召回率:按预测结果分,在所有预测为真的样本中实际也是真的比例 TP/(TP+FN)正样本中有多少是被找了出来
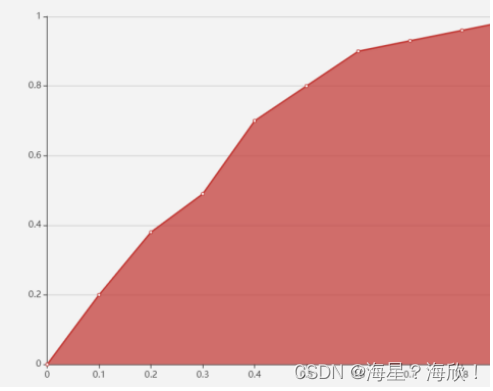
ROC 曲线
两个值:真正例率和假正例率
真正例率:TP/(TP+FN)
假正例率:FP/(FP+TN)
使用这两个值在坐标系上画出一系列的点,纵坐标是真正例率,横坐标是假正例率,把这些点连起来形成的曲线就是 ROC 曲线
ROC 曲线下方的面积是 AUC 值(Area Under Curve,曲线下面积),ROC 曲线和 AUC 值可以反映一个模型的稳定性,当 ROC 曲线接近对角线时,说明模型输出很不稳定,模型就越不准确
一些其他指标:泛化能力(过拟合与欠拟合)、可解释性、鲁棒性、模型速度
这些模型评估,大多适用于分类模型,因为分类模型是一种监督模型,对于无监督模型,本身没有非常明确的结果标准,所以也很难找到一个衡量指标
5、模型应用
模型产出结果,都需要应用到业务当中去
服务架构部署一些概念:
Flask Web 框架:在日常的任务中可以使用 Flask 作为构建我们的 Web 服务框架,它是用 Python 来实现的。
Gunicorn HTTP 服务:可以理解成 HTTP 服务器,需要注意的是 Gunicorn 只能运行在 Linux 服务器上面。
Nginx 负载均衡:Nginx 是一个功能很强大的 Web 服务项目,它可以用作负载均衡器,很多大公司都在使用。负载均衡用于通过集群中的多个服务器或实例将工作负载进行分布,目的是避免任何单一资源发生过载,进而将响应时间最小化、程序吞吐量最大化。在上图中,负载均衡器是面向客户端的实体,会把来自客户端的所有请求分配到集群中的多台服务器上。
客户端:业务的具体场景,可能是手机 App,也可能是其他服务器应用,客户端会向托管用于模型预测的架构服务器发送请求。比如今日头条 App 页面下拉,将会调用推荐算法模型进行推荐内容的计算。