开的免费网站能赚钱吗如何建立网站平台的步骤
一、概述
Scrapy是一个用于爬取网站数据的Python框架,可以用来抓取web站点并从页面中提取结构化的数据。
基本组件:
-
引擎(Engine):负责控制整个爬虫的流程,包括调度请求、处理请求和响应等。
-
调度器(Scheduler):负责接收引擎发送的请求,并将其按照一定的策略进行调度,生成待下载的请求。
-
下载器(Downloader):负责下载请求对应的网页,可以使用多种下载器,例如基于Twisted的异步下载器和基于requests的同步下载器。
-
中间件(Middleware):负责对请求和响应进行预处理和后处理,可以用于添加请求头、处理cookies等操作。
-
爬虫(Spider):负责定义如何解析网页和提取数据的规则,包括起始URL、请求构造、响应解析和数据提取等。
-
项目管道(Item Pipeline):负责处理爬虫从网页中提取的数据,并进行后续的处理,例如数据清洗、数据存储等。
数据处理流程:
-
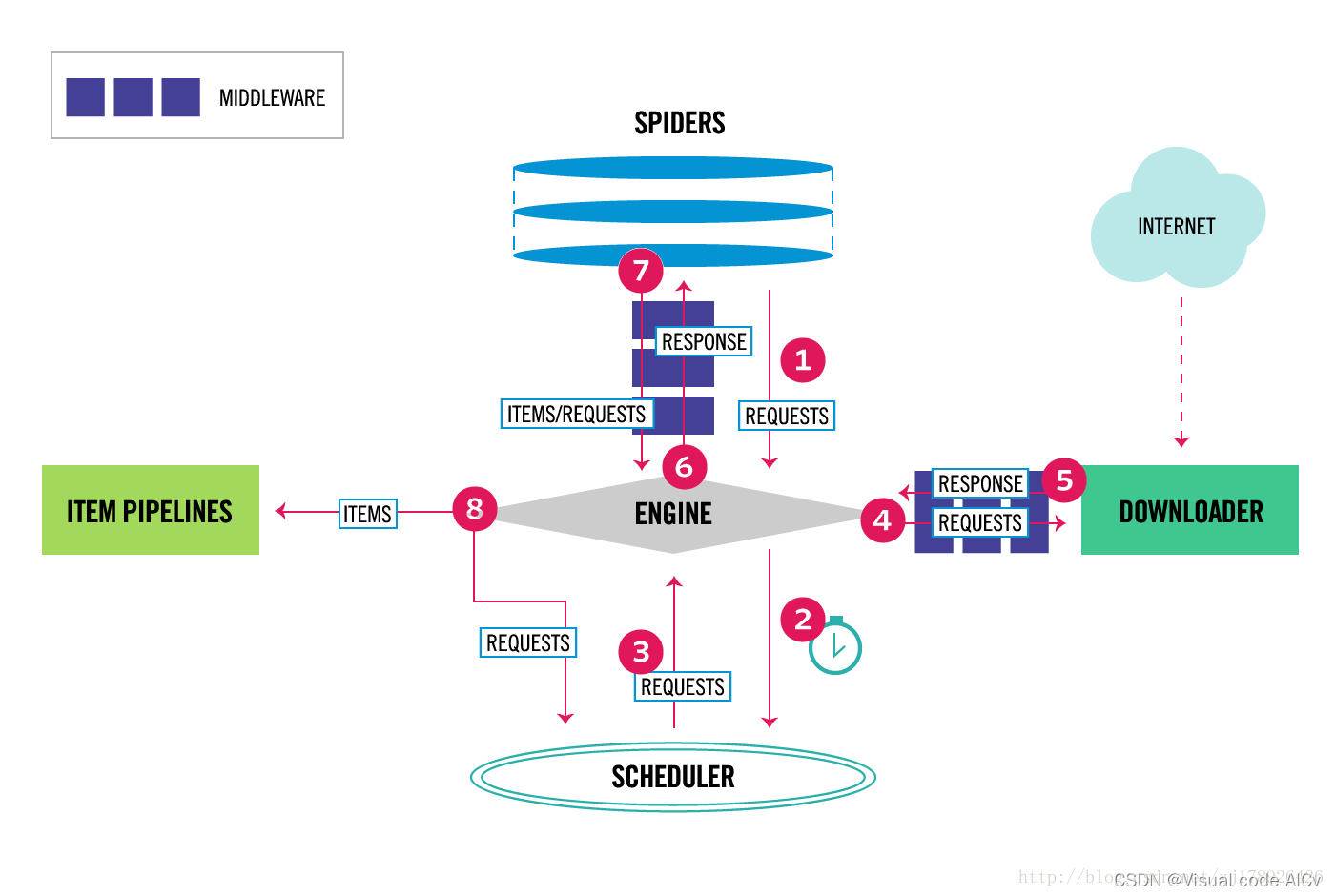
引擎从爬虫中获取起始URL,并生成对应的请求。
-
引擎将请求发送到调度器,调度器将获取到的URL存储在队列中,按照一定的策略进行调度,并生成待下载的请求。
-
引擎从调度器中获取接下来需要爬取的页面。
-
引擎将待下载的请求通过下载中间件发送到下载器。
-
下载器下载网页,并将响应返回给引擎。
-
引擎将响应通过爬虫中间件发送给爬虫,爬虫根据定义的规则对响应进行解析,并提取出需要的数据。
-
爬虫将提取的数据发送给项目管道,项目管道对数据进行处理,并进行后续的存储或其他操作。
-
引擎根据配置的规则继续生成新的请求,并重复上述步骤,直到没有新的请求或达到指定的停止条件。
下面是Scrapy框架的运行流程
二、基本使用方法
2.1 创建&管理Scrapy项目
2.1.1 Scrapy命令行
Scrapy自带一套命令行工具用于管理和运行Scrapy项目。
-
创建一个新的Scrapy项目:
scrapy startproject <project_name> -
在项目中创建一个新的Spider:
scrapy genspider <spider_name> <website_url> -
运行Spider并将结果保存为JSON或其他格式:
scrapy crawl <spider> -o <output_file>.json -
列出可用的Spider:
scrapy list -
检查Spider是否正确工作:
scrapy check <spider_name> -
运行Scrapy Shell来交互式地测试和调试Spider:
scrapy shell <website_url> -
查看Scrapy信息:
scrapy version
2.1.2 Pycharm
创建Scrapy项目:
1. 在Pycharm中创建一个“纯python”项目
注:demo1是项目名
2.在pycharm内使用命令行工具创建Scrapy项目
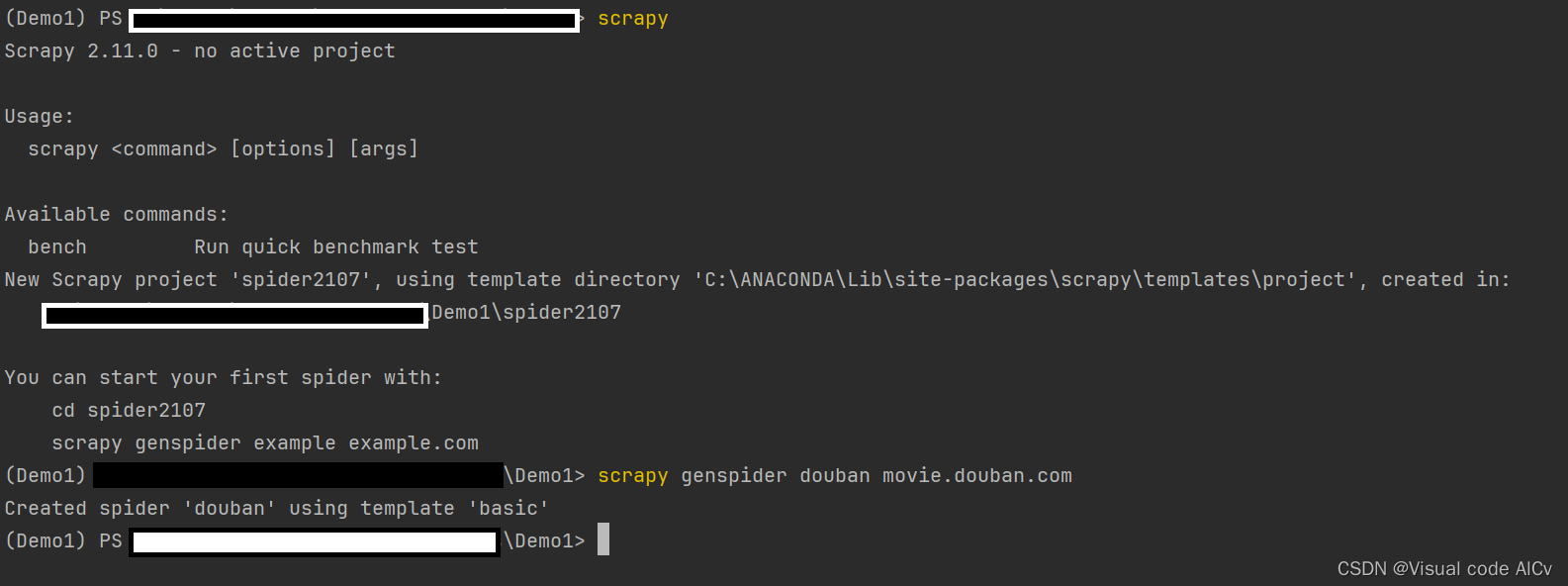
创建spider程序的命令行
scrapy genspider douban movie.douban.com
# douban为爬虫名称
# movie.douban.com为爬虫的作用域创建的目录
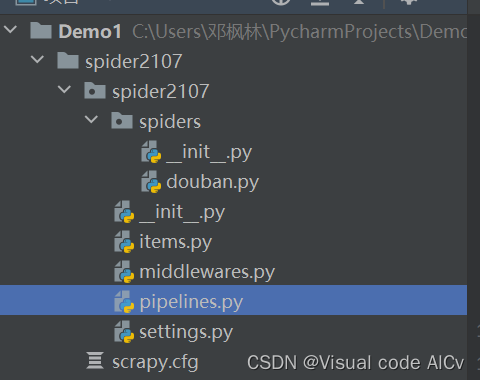
这些文件分别是:
- scrapy.cfg: 项目的配置文件。
- spider2107/: 项目的Python模块,将会从这里引用代码。
- spider2107/items.py: 项目的目标文件。
- spider2107/pipelines.py: 项目的管道文件。
- spider2107/settings.py: 项目的设置文件。
- spider2107/spiders: 存储爬虫代码目录。
新建虚拟环境:
文件 ——>设置项目设置 ——>新项目的设置
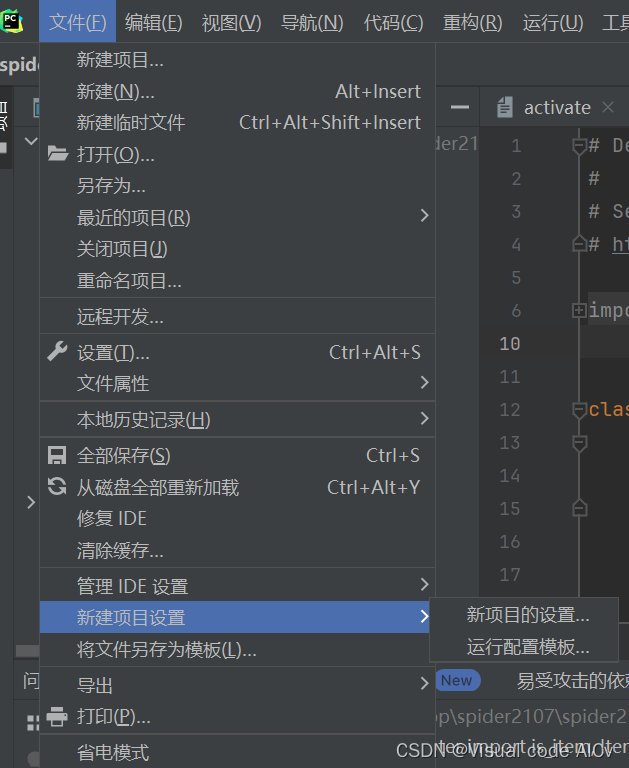
选择python解释器 ——>添加解释器 ——>Virtualenv环境 ——>在项目文件夹下添加envs (虚拟环境)——>确定
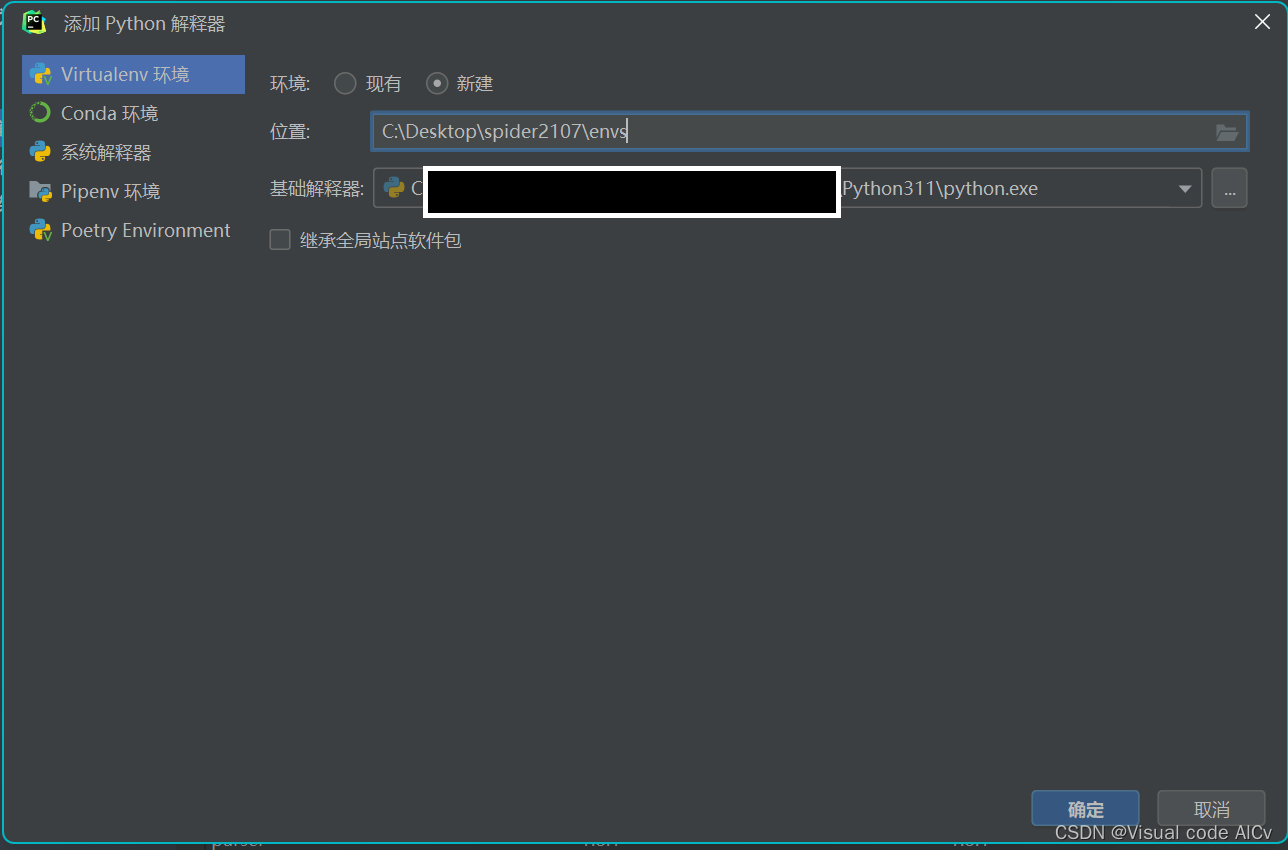
激活虚拟环境(Virtualenv环境)
env\Script\activate注:如果显示无法加载模块,可以先等一段时间,当pycharm新建索引到env文件夹时在运行这段命令
在pycharm中打开终端
使用pip下载scrapy
pip install scrapy创建spider程序
scrapy genspider <spidername><domain>写好程序后会scrapy会出现一个crawl的执行选项可用于执行spider
scrapy crawl <spidername>