企业网站的建设规划新站整站优化
Flink之Partitioner(分区规则)
| 方法 | 注释 |
|---|---|
| global() | 全部发往1个task |
| broadcast() | 广播(前面的文章讲解过,这里不做阐述) |
| forward() | 上下游并行度一致时一对一发送,和同一个算子连中算子的OneToOne是一回事 |
| shuffle() | 随机分配(只是随机,同Spark的shuffle不同) |
| rebalance() | 轮询分配,默认机制就是rebalance() |
| recale() | 一般是下游task是上游task的并行度的倍数时,在生成job时,会将下游中的某几个subtask和上游的某个subtask绑成一组,然后在组内上游subtask以轮询的方式将数据发送给下游的subtask. |
| partitionCustom | 自定义分区器(这里不做演示,后续会单独写一个自定义分区器的内容) |
| keyBy() | 根据数据key的HashCode进行Hash分配 |
-
global
global在实际业务场景中使用的不是很多,一般都是需要全局数据汇总的时候才会用到.global就是将上游的数据全部发往下游的第一个subtask中,也就是说下游设置再多的并行度是没意义的,所以使用global的时候,下游的task的并行度都是1.
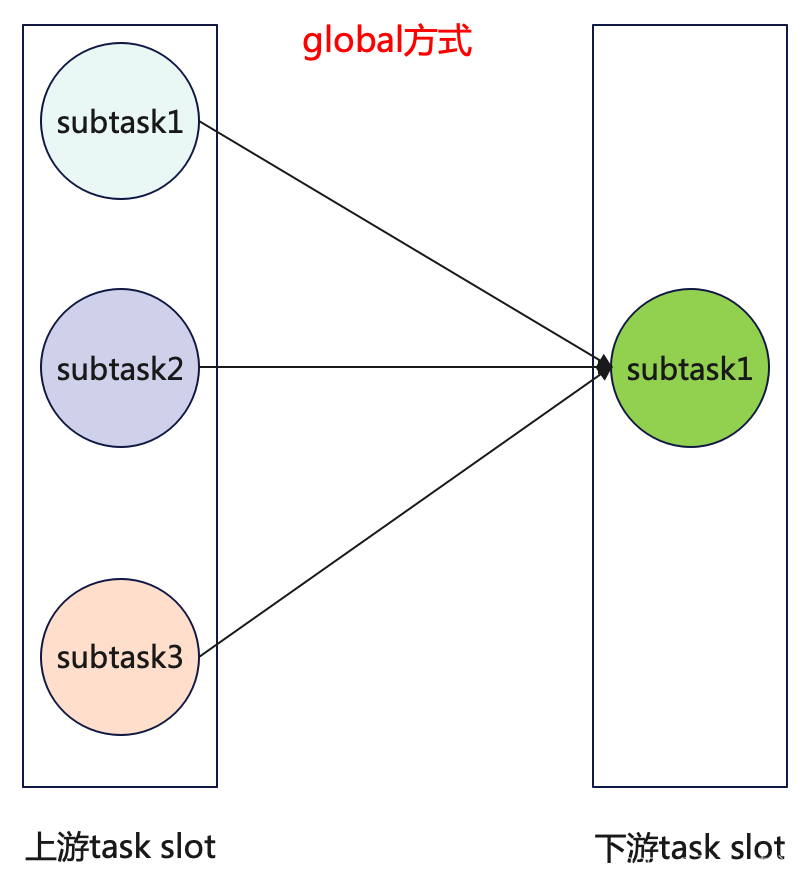
这里结合代码看一下:public class FlinkPartitioner {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();conf.setInteger("rest.port", 8081);// 开启本地WebUI,构建流环境StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);// 添加数据源,SocketDataStreamSource<String> sourceStream = env.socketTextStream("localhost", 9999);// 转大写,设置并行度为3,且设置数据分区方式为globalDataStream<String> upperCaseMapStream = sourceStream.map(s -> s.toUpperCase()).setParallelism(3).global();// 切分字符串,设置并行度为1SingleOutputStreamOperator<String> splitFlatMapStream = upperCaseMapStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] split = value.split(",");for (String s : split) {out.collect(s);}}}).setParallelism(1);//......env.execute("Flink Partitioner");} }WebUI界面查看代码中upperCaseMapStream和splitFlatMapStream之间数据的发送方式
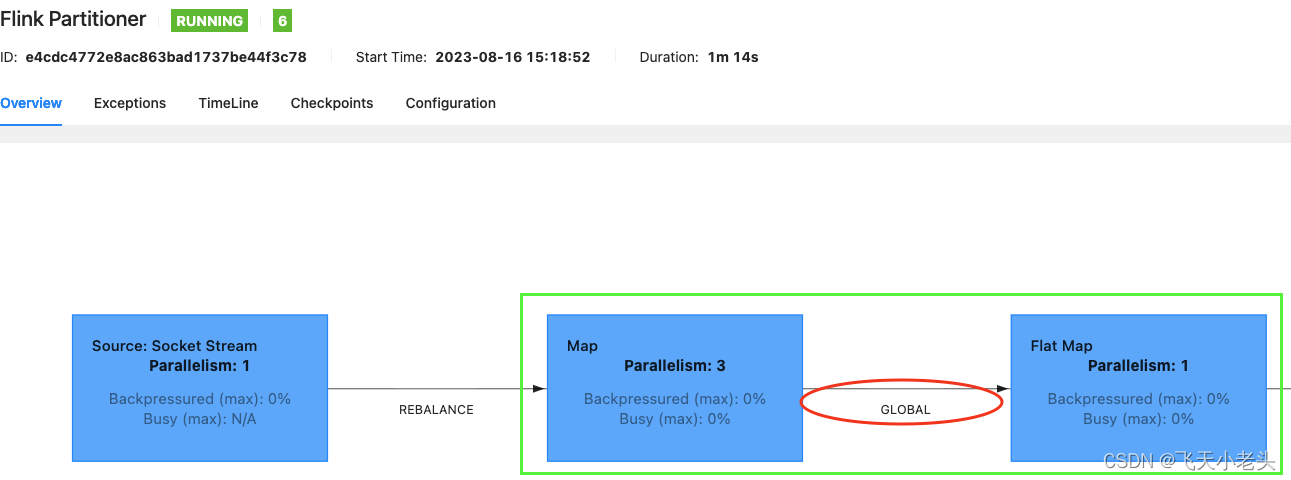
-
forward
forward其实就是一对一发送数据,和之前讲解Task的文章中提到的算子之间OneToOne的模式是一样的,就是可以将forward理解为同一个task chain[算子链]中算子之间的数据传输方式,但是使用forward的前提是上下游的算子并行度是一致的也就是上下游的subtask数量保持一致,图解如下:
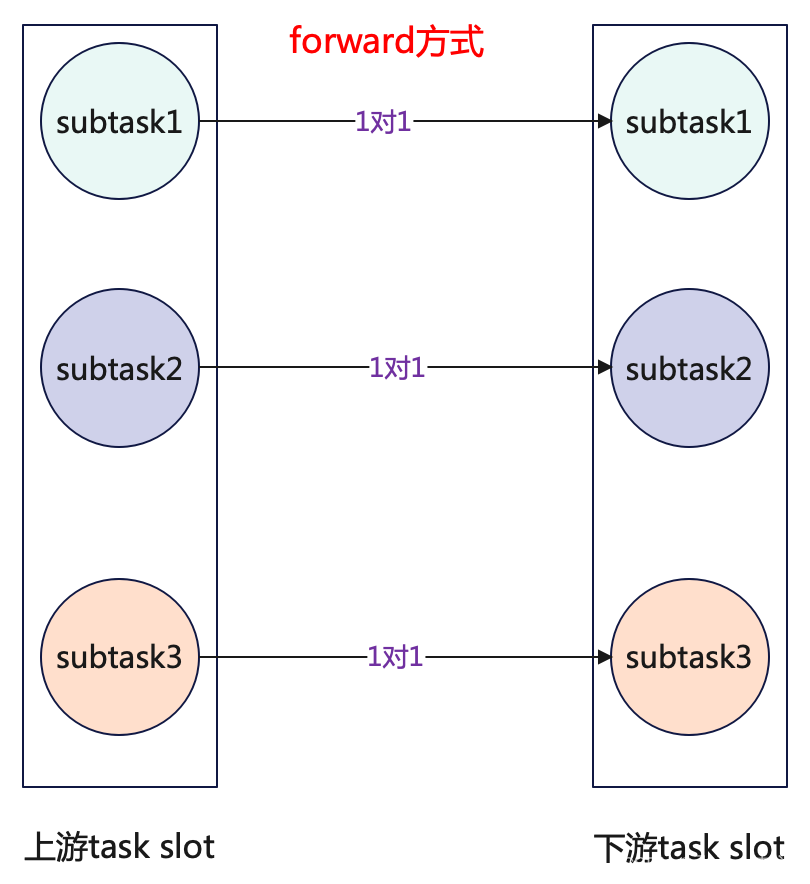
代码内容如下:
public class FlinkPartitioner {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();conf.setInteger("rest.port", 8081);// 开启本地WebUI,构建流环境StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);// 添加数据源,SocketDataStreamSource<String> sourceStream = env.socketTextStream("localhost", 9999);// 转大写,设置为forward分区方式DataStream<String> upperCaseMapStream = sourceStream.map(s -> s.toUpperCase()).setParallelism(3).forward();// 切分字符串SingleOutputStreamOperator<String> splitFlatMapStream = upperCaseMapStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] split = value.split(",");for (String s : split) {out.collect(s);}}}).setParallelism(3).startNewChain(); // 这里加上.startNewChain是为了在WebUI能看到效果,因为upperCaseMapStream和splitFlatMapStream的并行度是一致的,不加startNewChain默认的机制会将两者划分到同一个算子链中,就看不到实际的效果了.// ...env.execute("Flink Partitioner");} }WebUI界面查看upperCaseMapStream和splitFlatMapStream的数据发送方式,如下:
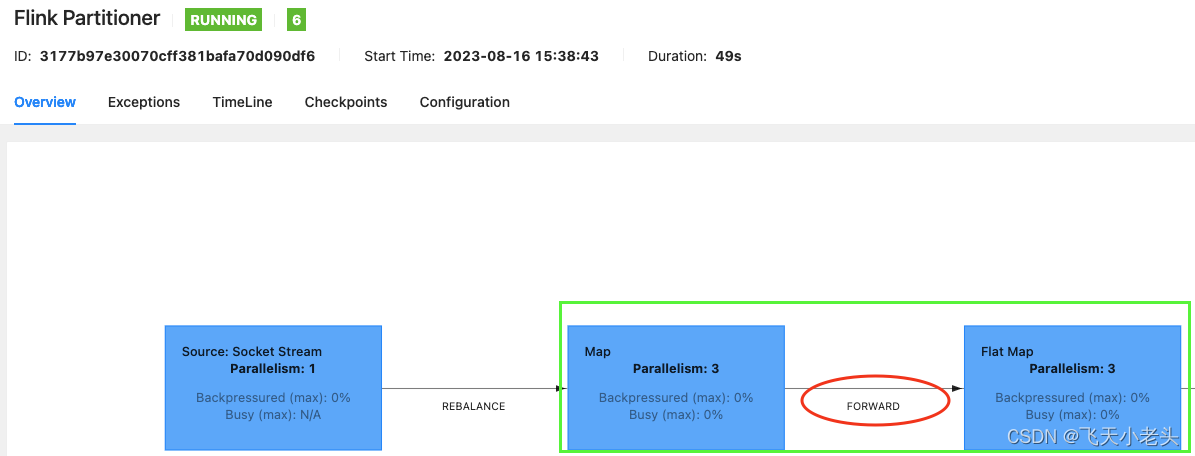
-
shuffle
通过前面
WebUI的图片我们可以看到,从Socket数据源将数据发送到第一个map的时候使用的是默认的rebalance方式,也就是轮询发送的方式,而这里说的shuffle虽然也是一对多的发送方式,但是发送数据时是随机的,举个例子,上游有3个subtask,下游有5个subtask,数据源有5条数据,上游中的某一个subtask向下游发送数据时,是随机发送的,下游的5个subtask并不是每个都一定能接受到数据,可能有的接收到1条,有的接收到2条,有的接收到3条数据,这就是shuffle发送数据的方式.如果说上两个
operator并行度一致,上游选择了shuffle发送数据的方式,那么两个operator会绑定成一个task chain么?不会,因为shuffle的数据发送方式就已经导致两个operator不是OneToOne的模式了.
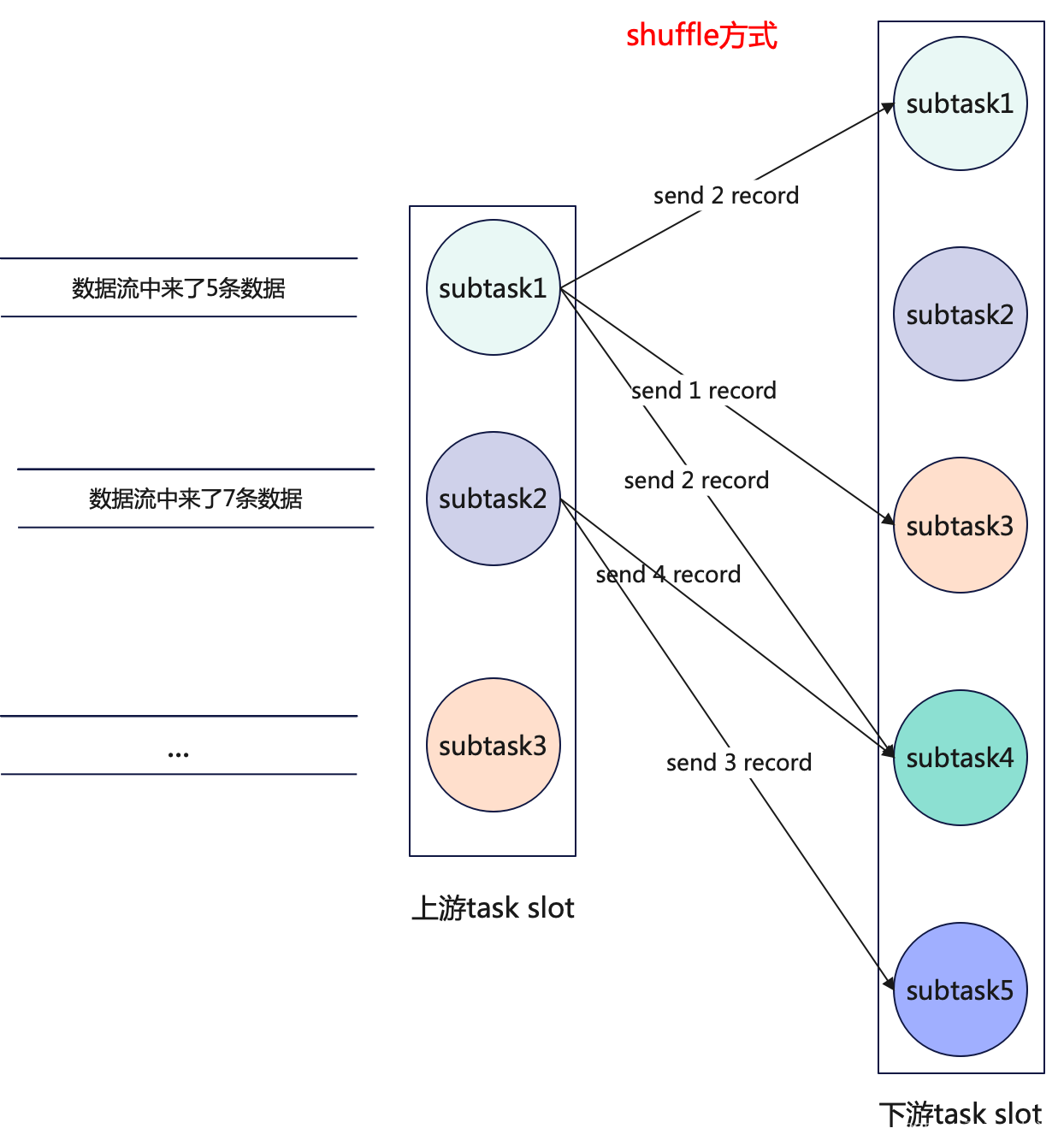
代码示例:public class FlinkPartitioner {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();conf.setInteger("rest.port", 8081);// 开启本地WebUI,构建流环境StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(conf);// 添加数据源,SocketDataStreamSource<String> sourceStream = env.socketTextStream("localhost", 9999);// 转大写,设置为shuffle分区方式DataStream<String> upperCaseMapStream = sourceStream.map(s -> s.toUpperCase()).setParallelism(3).shuffle();// 切分字符串SingleOutputStreamOperator<String> splitFlatMapStream = upperCaseMapStream.flatMap(new FlatMapFunction<String, String>() {@Overridepublic void flatMap(String value, Collector<String> out) throws Exception {String[] split = value.split(",");for (String s : split) {out.collect(s);}}}).setParallelism(7)// ...env.execute("Flink Partitioner");} }WebUI界面查看upperCaseMapStream和splitFlatMapStream的数据发送方式,如下:
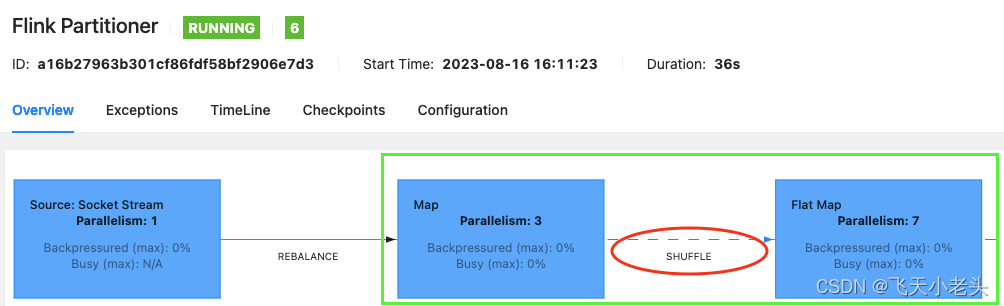
-
Rebalance
rebalance就是Flink默认的数据分发机制,直白的讲就是给每个小朋友一人一块糖果,直到发完为止,不偏不倚,这个不细说了,没什么可讲的.

-
recale
关于
recale前面说到了是组内的方式进行轮询分发数据,这里就以图解的方式进行讲解,便于理解.Flink任务启动时,如果发现上下游中使用了recale分发数据的方式就会将上下游的subtask进行分组绑定,如上游有2个subtask,下游有四个subtask,就会将上游的一个subtask和下游的两个subtask进行绑定,如下图:

当上下游对应的
subtask分组后,上下游组内的subtak就会以组内轮询的方式发送数据,如下图:
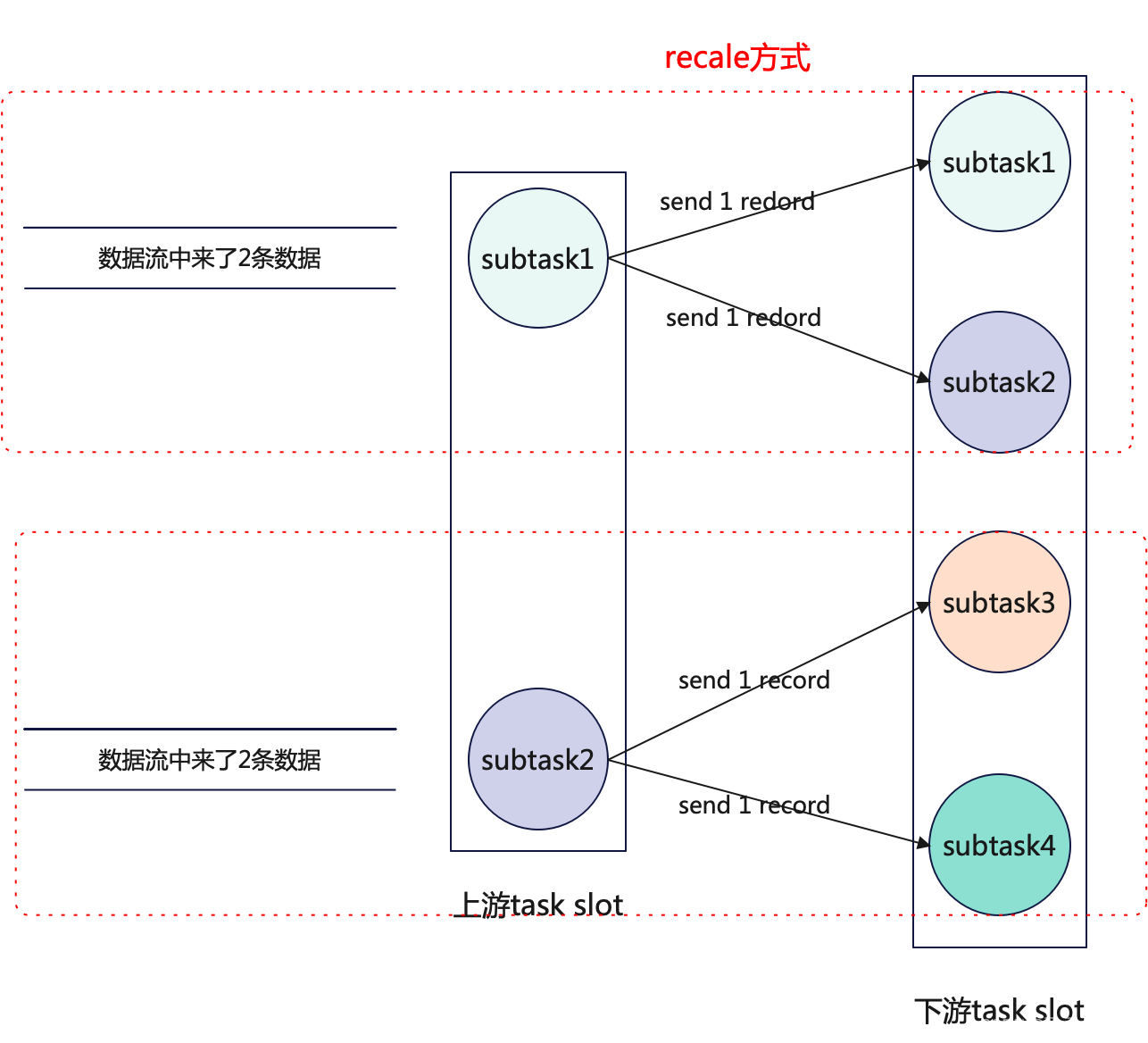
-
keyBy
keyBy使用的HASH分区方式,实际是hashCode()+murmurHash()的组合方式,这个在源码的KeyGroupRangeAssignment类中是可以看到的,简单来说根据key的hash值模除以下游的最大并行度(return MathUtils.murmurHash(keyHash) % maxParallelism;).关于
keyBy的使用应该都很熟悉了,这里直接给大家看演示结果吧,如下图:
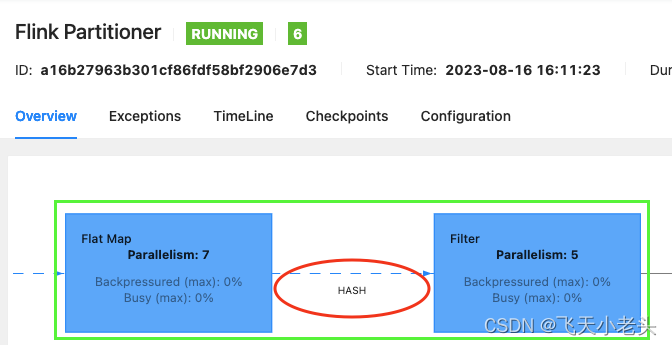
以上就是对Flink中分区规则的讲解.