开发个app需要多少钱?吉林seo关键词

目录
认识模型
参考方案(按模块拆解)
认识模型
模型控制1名英雄进行镜像1 v 1对战
Actor集群资源为64核CPU
问题特点:单一公平对抗场景(同英雄镜像对赛),单位时间样本产能低,累计训练资源相对充裕。
中级赛道难点:
-
训练下RL收敛性保证:在小资源长时间训练的情况下,如何解决样本多样性问题,使训练效果媲美高并发、中等时间训练的效果。
-
面向赛题英雄定制优化:环境和Baseline均未面向赛题英雄做任何优化。参赛队伍可以研究英雄设计和机制玩法特点,完善特征、规则、动作空间、奖励等相关设计,提升环境状态表征能力,整合已知先验和,降低策略学习难度并提升单英雄能力上限。
-
单一公平对抗场景下,需要关注并完善更多细节,得到更完备的策略。
此外,参赛队伍可以:
-
消灭各种bug(如不符合预期的移动/走位
-
实现支持在线调整或调度的多风格、多样化策略。面向对手行为进行进一步优化,包括建模和预测对手的行为,以便先发制人或极限闪避化解危机。
-
细化局内不同阶段的奖励方案(如动态权重),课程学习不同阶段的奖励权重(如过程导向或结果导向)
参考方案(按模块拆解)

(CNN+MLP)-LSTM的Encoder-Decoder结构 Multi--Head Value,通过分组改进Value估计效果,降低方差 使用全局Perfect Information铺助Value估计

定制特征:
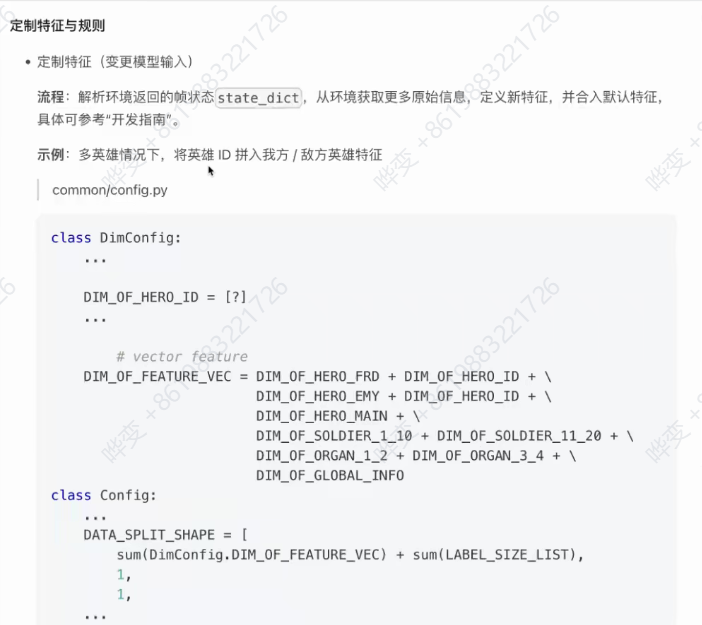
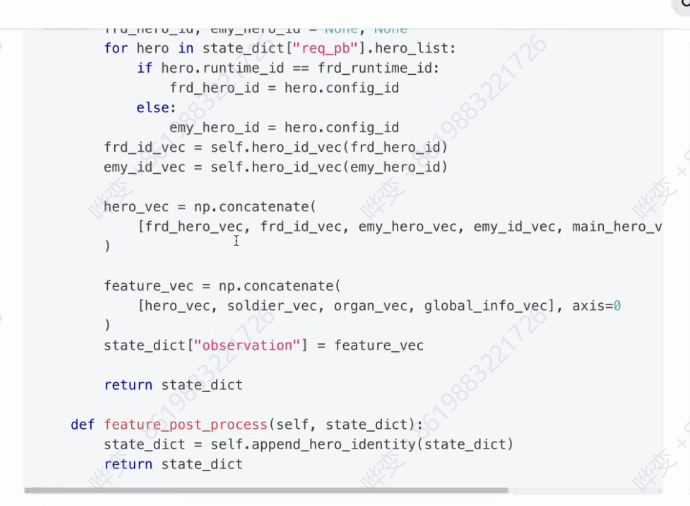
后置规则(处理模型输出)
具体操作参见"开发指南“
通过开发后置规则,可以支持实现模型输出->动作的二次映射。特定实现下,从RL
Agent视角看,等价于环境的变化。
奖励机制
具体操作参见"开发指南“、“环境介绍“,并建议参考往届各晋级队伍相关设计
可能的优化方向包括:
-
调整奖励子项权重
-
静态权重
-
局内动态权重(e.g.奖励局内衰减)
-
-
新增奖励项目
对手模型
具体操作参见"开发指南“,并建议参考往届各晋级队伍相关设计
对应位置:actor/actor..py
可能的优化方向包括:
-
新旧模型比例
-
对手模型池/League
-
自定义评估对局
学习策略
课程学习:将复杂、综合的学习目标分解为多阶段、更小规模的学习任务。
通过预训练模型+多阶段训练的方式,分步实现总体学习目标。心
例子:通过局间奖励衰减,实现稠密奖励到稀疏奖励的过渡
训练前期,偏重具体行为相关的稠密奖励,引导智能体学会基本操作
训练中期,增强与对局结果强相关的稠密奖励,引导智能体在单局中建立优势
训练后期,调高稀疏奖励权重,引导智能体直接关注最终胜负
知识蒸馏:强化学习+监督学习联合优化方案
例子:多英雄能力提升问题的内部解法之一
单英雄Teacher训练:强化学习,单英雄镜像自对战
蒸馏(单英雄Teacher->多英雄Student):在Actor样本中存入Teacher Logits
Learner增加一项监督学习的蒸馏
多英雄Student训练:强化学习,多英雄混合对战
注:可参考原理。受限于资源规模,在比赛中实际复现该做法的投入产出比可能并不突出。
系统优化角度
Learner效率
-
有效吞吐量
-
计算效率 比赛场景下,考虑到单位时间内Actor样本吞吐量远低于Learner,一般不需要进一步提升样本吞吐量
Graph中尽可能拼Batch计算,提高计算密度,对应底层计算从GEMV(访存密集型)->GEMM(计算密集型)
采用在GCU上性能更好的算子实现(可结合隧原-开发指南及实际Profiling情况)
-
样本池 当前框架版本的MemPool实现并非最优,可能存在一定程度的样本浪费现象 通过改进MemPool数据结构相关实现,改变随机读写方式,可以减少样本被覆盖的情况
-
-
样本效率与收敛速度
强化学习算法优化:其他条件不变,强化学习算法越高效,收敛至同等能力所需时间越短
-
Dual-Clip PPO / Value Clip 对policy loss进行双重clip,避免advantage取值outlier对收敛稳定性的影响。 类似地,可以对value loss进行clip,避免单步更新幅度过大对value network收敛的影响。
-
Value Normalization
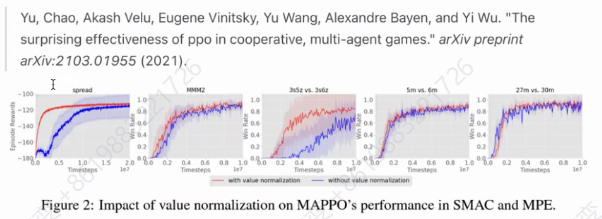
对于策略梯度方法,伴随着RL过程,value network学习目标的变化可能比较剧烈,影响了value估计的学习效果,进而影响了整体收敛效果与稳定性。实验表明,通过引入Vlue归一化,类PPO算法的样本效率可能获得改善。
-
PPG算法

-
SAC算法
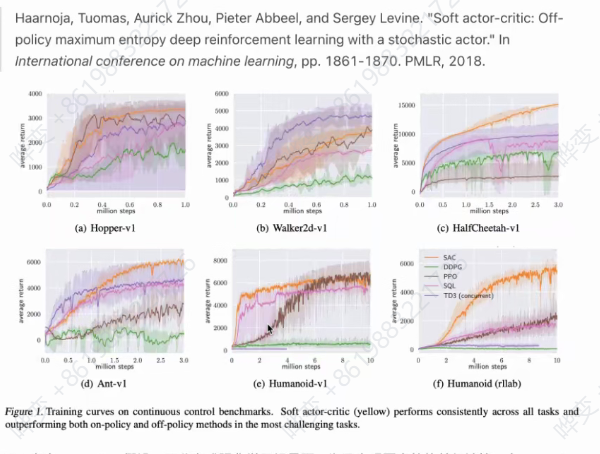
PPO存在on-policy假设,而分布式强化学习场景下,为了实现更高效的并行计算,在on-policy程度上存在妥协。SAC是一种off-policy的随机策略RL算法,在样本利用方式上和DDPG类似,区别在于其生成stochastic policy,在部分benchmark中表现出优于DDPG的样本效率。
考虑到更换PPO算法涉及较大的开发和调试工作量,推荐大部分队伍优先考虑在PPO算法基础上的优化,学有余力的队伍可以直接尝试更换算法。
-

Actor效率
吞吐量优化
-
CPU推理优化:Actor进程运行在CPU多机环境,可以面向CPU平台优化模型计算性能
-
PyTorch JIT优化
-
集成第三方推理框架(例如:onnx-runtime)
-
改善样本分布
-
可尝试通过intrinsic reward等方式,减少产生无效/同质化样本,提高样本多样性
-
可尝试引导生成符合特定条件的样本,比如使样本分布向特定对手模型倾斜
ABSTool工具使用
