哪些网站可以做翻译兼职ip域名查询地址
前言
学完了 Hadoop、Spark,本想着先把 Kafka、Flume 这些工具先学完的,但想了想还是把核心的技术先学完最后再去把那些工具学学。
最近心有点累哈哈哈,偷偷立个 flag,反正也没人看,明年的今天来这里还愿哈,愿望这种事情我是从来是不会说出来的,毕竟言以泄败,事以密成嘛。
那我隐晦低表达一下,摘录自《解忧杂货店》的一条句子:
这是克朗对自己梦想的描述,其实他不是自不量力,而是假如放弃了这个梦想,他的生活就失去了光,他未来的几十年生活会枯燥无味,会活的没有一点激情。
就像一个曾经自己深爱过的姑娘一样,明明无法在一起,却还是始终记挂着,因为心里眼里只有她,所以别人在你眼中,都会黯然失色的,没有色彩的东西,又怎么能投入激情去爱呢?
我的愿望有两个,在上面中有所体现,但我希望结果不要是遗憾,第一个愿望明年这会大概知道结果了,第二个愿望应该会晚一点,也许在2025年的春天,也许会更早一点...
API 环境搭建
添加依赖
pom.xml
<properties><flink.version>1.13.0</flink.version><java.version>1.8</java.version><scala.binary.version>2.12</scala.binary.version><slf4j.version>1.7.30</slf4j.version>
</properties>
<dependencies>
<!-- 引入 Flink 相关依赖--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_${scala.binary.version}</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_${scala.binary.version}</artifactId><version>${flink.version}</version>
</dependency>
<!-- 引入日志管理相关依赖--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-to-slf4j</artifactId><version>2.14.0</version>
</dependency>
</dependencies>
log4j.properties
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
入门案例
0、数据准备
在 根目录下创建 words.txt
hello flink
hello java
hello spark
hello hadoop1、批处理
批处理所用到的算子API 都继承自 DataSet,而新版的 Flink 已经做到了流批一体,这里只做演示,以后这类 API 应该是要被弃用了。
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;public class BatchWordCount {public static void main(String[] args) throws Exception {// 1. 创建一个执行批式数据处理环境ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 2. 从文件中读取数据 String类型 批式数据处理环境得到的 DataSource 继承自 DataSetDataSource<String> lineDS = env.readTextFile("input/words.txt");// 3. 将每行数据转换成一个二元组类型// 输入类型: String 输出类型: Tuple2FlatMapOperator<String, Tuple2<String, Long>> wordAndOne =// String lines: 输入数据行 Collector<Tuple2<String,Long>> out: 输出类型lineDS.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}}).returns(Types.TUPLE(Types.STRING, Types.LONG)); //使用 Java 泛型的时候, 由于泛型擦除的存在, 需要显示信息返回返回值类型// 4. 根据 word 分组UnsortedGrouping<Tuple2<String, Long>> wordGroup = wordAndOne.groupBy(0); // 0 是索引位置// 5. 分组内进行聚合AggregateOperator<Tuple2<String, Long>> res = wordGroup.sum(1); // 1 也是索引位置// 6. 打印结果res.print();}
}
运行结果:
(hadoop,1)
(flink,1)
(hello,4)
(java,1)
(spark,1)Process finished with exit code 0因为现在已经是流批一体的框架了,所以提交 Flink 批处理任务需要用下面的语句:
$ bin/flink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar2、流处理
2.1、有界数据流处理
这里我们用离线数据(提前创建好的文件)用流处理API DataStream 的算子来做处理。
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class BoundedStreamWordCount {public static void main(String[] args) throws Exception {// 1. 创建一个流式的执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();// 2. 流式数据处理环境得到的 DataSource 继承自 DataStreamDataStreamSource<String> lineDS = env.readTextFile("input/words.txt");// 3. flatMap 打散数据 返回元组SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDS.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}}).returns(Types.TUPLE(Types.STRING, Types.LONG));// 4. 根据 word 分组KeyedStream<Tuple2<String, Long>, String> wordGroupByKey = wordAndOne.keyBy(t -> t.f0);// 5. 根据键对索引为 1 处的值进行合并SingleOutputStreamOperator<Tuple2<String, Long>> res = wordGroupByKey.sum(1);// 6. 输出结果res.print();// 7. 执行env.execute(); // 这里我们的数据是有界的,但是真正开发环境是无界的,这里需要用execute方法等待新数据的到来}
}
运行结果:
3> (java,1)
13> (flink,1)
1> (spark,1)
5> (hello,1)
5> (hello,2)
5> (hello,3)
5> (hello,4)
15> (hadoop,1)我们可以发现,输出的单词的顺序是乱序的,因为集群模式下数据流不是在本地执行的,而是在多个节点中执行,所以也就无法保证先输入的单词最先输出。
Idea下Flink API 会使用多线程来模拟集群下的多节点并行处理,而我们每行数据前面的 "编号>" 代表的就是线程的 id(对应 Flink 运行时占据的最小资源,也叫任务槽),默认使用当前电脑的所有 CPU 数。
我们还可以发现,hello是同一个节点上处理的,这是因为我们在做分组的时候,把分组后的数据分到了同一个节点(子任务)上。
2.2、无界数据流处理
这里我们使用 netcat 来模拟产生数据流
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;public class UnBoundedStreamWordCount {public static void main(String[] args) throws Exception {// 1. 创建一个流式的执行环境StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment();// 2. 流式数据处理环境得到的 DataSource 继承自 DataStreamParameterTool parameterTool = ParameterTool.fromArgs(args);String host = parameterTool.get("host");Integer port = parameterTool.getInt("port");DataStreamSource<String> lineDS = env.socketTextStream(host,port);// 3. flatMap 打散数据 返回元组SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOne = lineDS.flatMap((String line, Collector<Tuple2<String, Long>> out) -> {String[] words = line.split(" ");for (String word : words) {out.collect(Tuple2.of(word, 1L));}}).returns(Types.TUPLE(Types.STRING, Types.LONG));// 4. 根据 word 分组KeyedStream<Tuple2<String, Long>, String> wordGroupByKey = wordAndOne.keyBy(t -> t.f0);// 5. 根据键对索引为 1 处的值进行合并SingleOutputStreamOperator<Tuple2<String, Long>> res = wordGroupByKey.sum(1);// 6. 输出结果res.print();// 7. 执行env.execute(); // 这里我们的数据是有界的,但是真正开发环境是无界的,这里需要用execute方法等待新数据的到来}
}
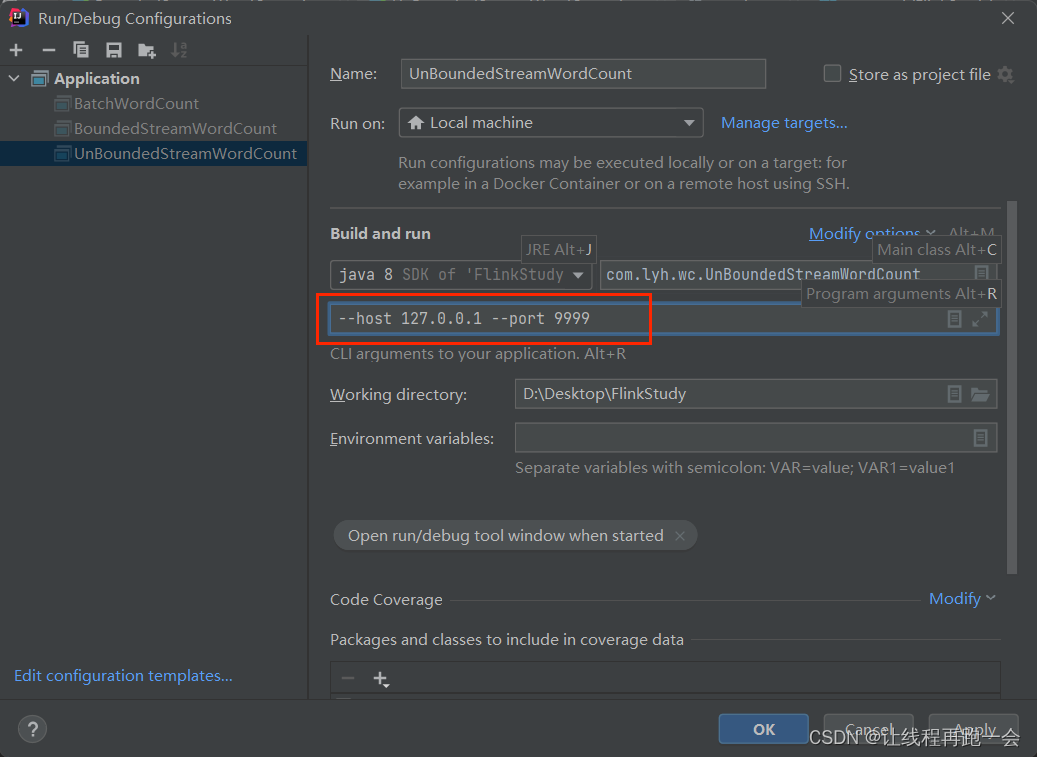
运行结果:
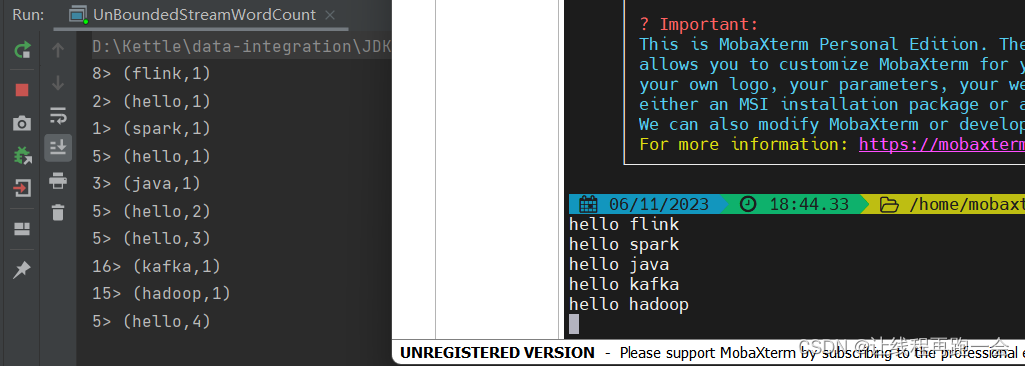
可以看到,处理是相当快的,毕竟数据量很小,但是会想到 SparkStreaming 的处理过程,我们之前用 SparkStreaming 的时候还需要设置 Reciver 的接收间隔,而我们的 Flink 则是真正的实时处理。
总结
Flink 的学习终于开始了,还是一样的要求,不照搬视频课件内容,每行代码要有自己的思考,每行博客也要是自己思考的总结。
还有,最近感觉愈发词穷,该多看书了,以后养成每次博客加一条书摘的习惯。