网店网站技术方案百度推广登录官网入口
Shuffle : 集群范围内跨节点、跨进程的数据分发
- 分布式数据集在集群内的分发,会引入大量的磁盘 I/O 与网络I/O
- 在 DAG 的计算中,Shuffle 环节的执行性能是最差的 , 会消耗所有类型的硬件资源 (CPU、内存、磁盘、网络)
Spark 2.0 后,将 Shuffle 操作统一交由 Sort shuffle Manager 来管理
- DAGScheduler 以 Shuffle 为边界,把计算图 DAG 切割为多个执行阶段 Stages
Spark/公司人物对比 :
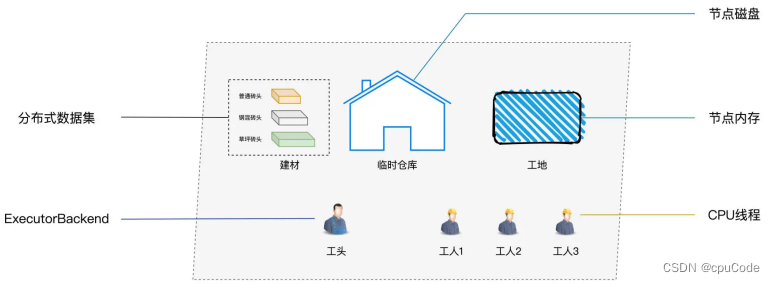
Shuffle类比 :
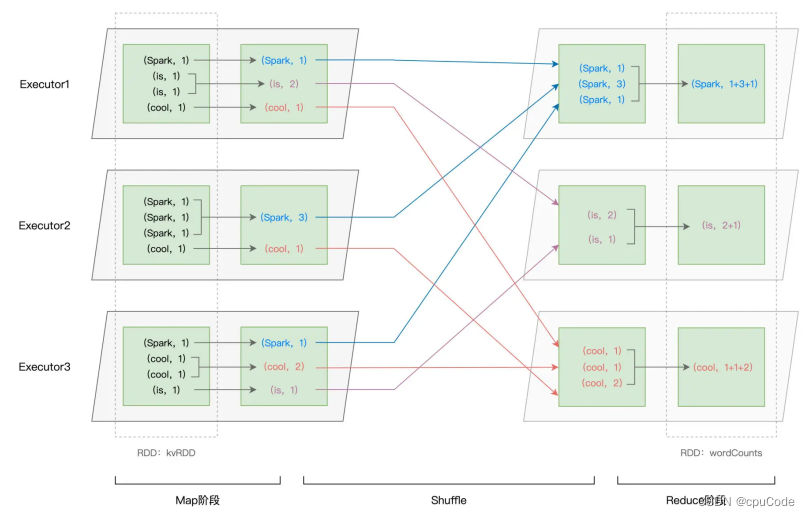
Shuffle 工作原理
reduceByKey 会引入 Shuffle
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
reduceByKey计算过程 :
- 以 Shuffle 为边界,reduceByKey 的计算被切割为两个执行阶段
- Map 阶段 : Shuffle 之前的 Stage : 每个 Executors 先在数据分区做初步聚合 (Map 端聚合、局部聚合)
- Shuffle : 不同的单词被分发到不同节点的 Executors 中
- Reduce 阶段 : Shuffle 之后的 Stage : Executors 以单词为 Key 做第二次聚合 (全局聚合),从而完成统计计数的任务
Shuffle 是跨节点、跨进程的数据分发
- Shuffle 是 Map 阶段与 Reduce 阶段之间的数据交换
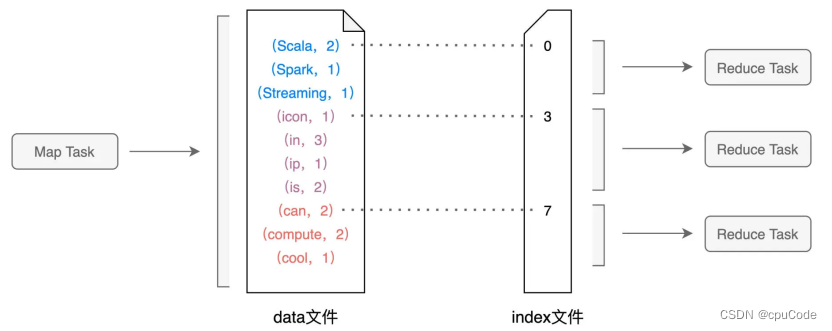
Shuffle 中间文件
Shuffle 中间文件有两类实体文件 :
-
data 文件 : 记录(Key,Value)键值对的
-
index 文件 : 记录键值对所属 Reduce Task 的
-
Map 阶段生产 Shuffle 中间文件
-
Reduce 阶段消费 Shuffle 中间文件
-
二者以中间文件为媒介,完成数据交换
Shuffle 中间文件 :
- DAGScheduler 会为每个 Stage 创建任务集合 TaskSet( n 个 Task)
- 每个 Map Task 都会生成 data 文件与 index 文件的 Shuffle 中间文件
- 即 : Map 阶段有多少Task,就会生成多少份 Shuffle 中间文件
Shuffle 的数据交换规则 (分区规则) :
- 定义了 Reduce 阶段怎么划分数据分区
- 设 Reduce 阶段有 N 个 Task (对应 N 个数据分区),在 Map 阶段的数据应该分发到哪个 Reduce Task,由下公式来决定
P = Hash(Record Key) % N
Shuffle Write
生成中间文件时,Spark 会用类似于 Map 内存数据结构 (PartitionedPairBuffer, PartitionedAppendOnlyMap),来计算、缓存并排序数据分区中的数据记录
- Map 结构的 Key 是(Reduce Task Partition ID, Record Key)
- Value 是原数据记录中的数据值
Shuffle Write:
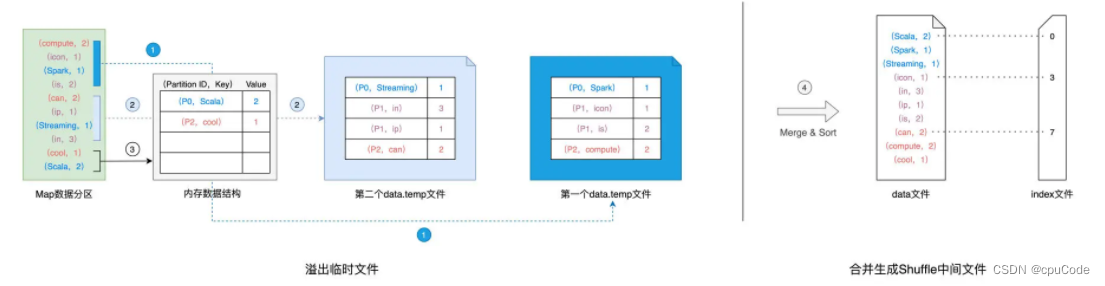
- 对数据分区中的数据 , 逐条计算的目标分区 ID,然后把 Key 和数据插到 Map 中
- 当 Map 装满后,再根据 Key 对 Map 中的数据做快排,并把数据溢出到磁盘中的临时文件
- 直到数据全部溢出完毕,用归并排序对这些数据做合并,分别生成 data 文件、 index 文件
PartitionedPairBuffer
groupByKey 采用 PartitionedAppendOnlyMap 来填充数据记录, 该数据结构是数组形式的缓存结构
PartitionedPairBuffer:

PartitionedAppendOnlyMap
reduceByKey 采用 PartitionedAppendOnlyMap 来填充数据记录。该数据结构是一种 Map,而 Map 的 Value 值是可累加、可更新的。
依靠高效的内存数据结构、更少的磁盘文件、更小的文件尺寸,能提高Shuffle 效率
PartitionedAppendOnlyMap 大小 = 4 :


Shuffle Read
Reduce 阶段的任务数量(并行度)决定了每个中间文件中目标分区数
- 即:Reduce 的并行度是 3,Map Task 的中间文件会包含 3 个目标分区的数据,index 文件记录了目标分区数据的起始索引
Shuffle Read: Reduce 从 Map 拉取数据的过程:
- Reduce Task 通过网络从不同 Map Task 的中间文件并拉取属于自己的数据
- 不同的 Reduce Task 根据 index 中起始索引来确定哪些数据属于自己的
- Reduce Task 将拉取到的数据块填充到读缓冲区
- 按照任务的计算逻辑不停地消费、 处理缓冲区中的数据记录

reduceByKey 采用一种叫做 PartitionedAppendOnlyMap 的数据结构来填充数据记录。这个数据结构是一种 Map,而 Map 的 Value 值是可累加、可更新的。因此,PartitionedAppendOnlyMap 非常适合聚合类的计算场景,如计数、求和、均值计算、极值计算等