青州做网站电话佛山seo优化
爬取百度图片并显示
- 引言
- 一、图片显示
- 二、代码详解
- 2.1 得到网页内容
- 2.2 提取图片url
- 2.3 图片显示
- 三、完整代码
引言
爬虫(Spider),又称网络爬虫(Web Crawler),是一种自动化程序,可以自动地浏览互联网上的网站,并从中抓取数据。它主要通过 HTTP / HTTPS 协议访问网页,并将访问到的网页内容进行解析和分析,从而提取有用的数据,例如新闻、评论、图片、视频等。爬虫在搜索引擎、大数据采集、信息监测和分析等领域都有广泛的应用。
Pyhon有很多库可以实现爬虫功能,如Python中的requests库是一个第三方HTTP客户端库,它提供了一种更简单、更人性化的方式来发送HTTP/1.1请求。它允许我们发送HTTP/1.1请求以及各种HTTP方法,如GET、POST、PUT、DELETE、PATCH等。使用requests库,我们可以轻松地向外部API发送HTTP请求,并获取请求的响应。requests库提供了很多高级功能,比如会话管理、SSL证书验证、HTTP代理支持、文件上传等等。
一、图片显示
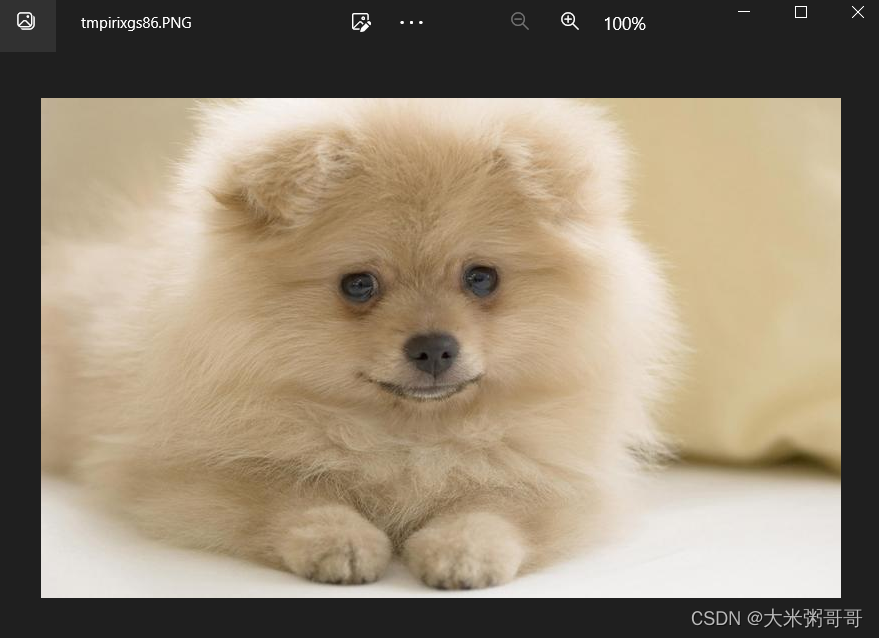
本文旨在介绍使用Python中的requests库爬取百度图片并显示的操作方法。该操作较为简单,适合初学者入门。
使用pip可以很容易地安装requests库:pip install requests
二、代码详解
需要导入的库:
import requests
from PIL import Image
from io import BytesIO
requests库用于获取网络数据,PIL库用于处理图像数据,BytesIO用于将二进制数据转换为图像数据。
2.1 得到网页内容
主要步骤:
- 设定好
headers,防止网页拒绝被访问
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}
- 在url中设定好
queryWord和word,即百度图片查询的关键词,本文以tupian为例 (亦可设置为汉子)
url = ('https://image.baidu.com/search/acjson?''tn=resultjson_com&logid=9047316633247341826&ipn=rj&ct=201326592&is=&fp=result&''queryWord=tupian&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&''word=tupian&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&force=&''pn=30&rn=30&gsm=1e&1616935040863=')
- 使用
requests或其它库获取网页内容即可,这里使用requests库发送GET请求并传递请求头和参数,获取响应的网页数据。
import requests
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
2.2 提取图片url
根据网页图片链接格式,提取图片的链接,网页内容中的图片链接以"thumbURL"开始:
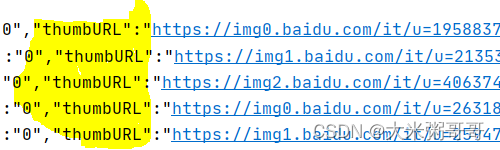
使用正则表达式提取可参考正则表达式(详解)
import re
imgs =[]
reg = re.compile('"thumbURL":"(.+?\.jpg)"')
imgs.extend(reg.findall(response))
print(imgs)
2.3 图片显示
获取图片链接里的内容,并显示
获取到的img是二进制字符,先试用BytesIO读取后显示
img = requests.get(url=imgs[0], headers=headers).content
from PIL import Image
from io import BytesIO
bytes_stream = BytesIO(img)
img = Image.open(bytes_stream)
img.show()
至此,成功地使用requests库爬取了百度图片,并将其显示出来。需要注意的是,此处仅为简单的入门示例,对于复杂的网站爬取和数据解析,需要使用更为专业的工具和技术。
三、完整代码
# 1.得到网页内容
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}
url = ('https://image.baidu.com/search/acjson?''tn=resultjson_com&logid=9047316633247341826&ipn=rj&ct=201326592&is=&fp=result&''queryWord=tupian&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&''word=tupian&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&force=&''pn=30&rn=30&gsm=1e&1616935040863=')
import requests
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
response = response.text
#print(response)# 2.提取图片url
import re
imgs =[]
reg = re.compile('"thumbURL":"(.+?\.jpg)"')
imgs.extend(reg.findall(response))
print(imgs)# 3.显示图片
img = requests.get(url=imgs[0], headers=headers).content
from PIL import Image
from io import BytesIO
bytes_stream = BytesIO(img)
img = Image.open(bytes_stream)
img.show()