公司做网站需要注意什么事情搜索引擎推广的三种方式
原论文地址:原论文地址
DoubleAttention网络结构的优点在于,它能够有效地捕获图像中不同位置和不同特征的重要性,从而提高了图像识别和分割的性能。
论文相关内容介绍:
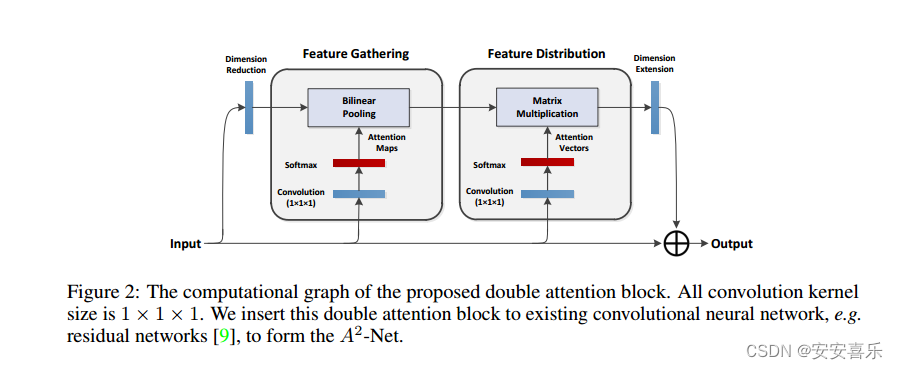
论文摘要:学习捕捉远程关系是图像/视频识别的基础。现有的CNN模型通常依赖于增加深度来建模这种关系,这是非常低效的。在这项工作中,我们提出了“双注意块”,这是一种新的组件,它从输入图像/视频的整个时空空间中聚集和传播信息全局特征,使后续卷积层能够有效地从整个空间中访问特征。该组件采用双注意机制,分两步进行设计,第一步通过二阶注意池将整个空间的特征聚集成一个紧凑的集合,第二步通过另一个注意自适应地选择特征并将其分配到每个位置。所提出的双注意块易于采用,并且可以方便地插入现有的深度神经网络中。我们对图像和视频识别任务进行了广泛的消融研究和实验,以评估其性能。在图像识别任务上,配备我们的双注意力块的ResNet-50在ImageNet-1k数据集上的性能优于更大的ResNet-152架构,参数数量减少了40%以上,FLOPs也减少了。在动作识别任务上,我们提出的模型在Kinetics和UCF-101数据集上取得了最先进的结果,效率显著高于最近的工作。


A2-Net与SENet有点类似,但是不同点在于它的第一个注意力操作隐式地计算池化特征的二阶统计,并能捕获SENet中使用的全局平均池化无法捕获的复杂外观和运动相关性;
2.yolov8加入DoubleAttention的步骤:
2.1 在/ultralytics/nn/modules/block.py添加代码到末尾
class DoubleAttention(nn.Module):def __init__(self, in_channels,c_m=128,c_n=128,reconstruct = True):super().__init__()self.in_channels=in_channelsself.reconstruct = reconstructself.c_m=c_mself.c_n=c_nself.convA=nn.Conv2d(in_channels,c_m,1)self.convB=nn.Conv2d(in_channels,c_n,1)self.convV=nn.Conv2d(in_channels,c_n,1)if self.reconstruct:self.conv_reconstruct = nn.Conv2d(c_m, in_channels, kernel_size = 1)self.init_weights()def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):b, c, h,w=x.shapeassert c==self.in_channelsA=self.convA(x) #b,c_m,h,wB=self.convB(x) #b,c_n,h,wV=self.convV(x) #b,c_n,h,wtmpA=A.view(b,self.c_m,-1)attention_maps=F.softmax(B.view(b,self.c_n,-1))attention_vectors=F.softmax(V.view(b,self.c_n,-1))# step 1: feature gatingglobal_descriptors=torch.bmm(tmpA,attention_maps.permute(0,2,1)) #b.c_m,c_n# step 2: feature distributiontmpZ = global_descriptors.matmul(attention_vectors) #b,c_m,h*wtmpZ=tmpZ.view(b,self.c_m,h,w) #b,c_m,h,wif self.reconstruct:tmpZ=self.conv_reconstruct(tmpZ)return tmpZ2.2 在/ultralytics/nn/modules/block.py的头部all里面将”DoubleAttention"加入到末尾
__all__ = ("DFL","HGBlock","HGStem","SPP","SPPF","C1","C2","C3","C2f","C2fAttn","ImagePoolingAttn","ContrastiveHead","BNContrastiveHead","C3x","C3TR","C3Ghost","GhostBottleneck","Bottleneck","BottleneckCSP","Proto","RepC3","ResNetLayer","RepNCSPELAN4","ADown","SPPELAN","CBFuse","CBLinear","Silence","DoubleAttention",)
2.3在/ultralytics/nn/modules/__init__.py的头部
from .block import (
里面将”CoTAttention"加入到末尾
from .block import (C1,C2,C3,C3TR,DFL,SPP,SPPF,Bottleneck,BottleneckCSP,C2f,C2fAttn,ImagePoolingAttn,C3Ghost,C3x,GhostBottleneck,HGBlock,HGStem,Proto,RepC3,ResNetLayer,ContrastiveHead,BNContrastiveHead,RepNCSPELAN4,ADown,SPPELAN,CBFuse,CBLinear,Silence,DoubleAttention,
)2.4 在/ultralytics/nn/tasks.py
from ultralytics.nn.modules import (C1, C2, C3, C3TR, SPP, SPPF,
Bottleneck, BottleneckCSP, C2f, C3Ghost, C3x, Classify,Concat, Conv,ConvTranspose, Detect, DWConv, DWConvTranspose2d, Ensemble,
Focus,GhostBottleneck, GhostConv, Segment, DoubleAttention)def parse_model(d, ch, verbose=True): 加入以下代码:
elif m is DoubleAttention:c1, c2 = ch[f], args[0]if c2 != nc:c2 = make_divisible(min(c2, max_channels) * width, 8)args = [c1, *args[1:]]
2.5 yolov8_DoubleAttention.yaml
# Ultralytics YOLO 🚀, GPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 4 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'# [depth, width, max_channels]n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPss: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPsm: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPsl: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPsx: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs# YOLOv8.0n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 3, C2f, [128, True]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 6, C2f, [256, True]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 6, C2f, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 3, C2f, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9# YOLOv8.0n head
head:- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 3, C2f, [512]] # 12- [-1, 1, nn.Upsample, [None, 2, 'nearest']]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 3, C2f, [256]] # 15 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 12], 1, Concat, [1]] # cat head P4- [-1, 3, C2f, [512]] # 18 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 9], 1, Concat, [1]] # cat head P5- [-1, 3, C2f, [1024]] # 21 (P5/32-large)- [-1, 1, DoubleAttention, [1024]] - [[15, 18, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)