德州市建设街小学网站首页全球搜索引擎市场份额

文章目录
- 一、背景
- 二、方法
- 2.1 学习 视觉-语义 空间
- 2.2 学习开放词汇目标检测
- 三、效果
论文:Open-Vocabulary Object Detection Using Captions
代码:https://github.com/alirezazareian/ovr-cnn
出处:CVPR2021 Oral
一、背景
目标检测数据标注很耗费人力,现有的开集大型数据,如 Open Images 和 MSCOCO 数据集大约包含 600 个数据类别
如果想要识别现实世界中的任何物体,则需要更多的人工数据标注
但人类学习显示视觉世界中的物体很大程度上是基于语言的监督信号,也可以使用几个简单的例子来泛化到其他目标上,而不需要所有的目标实例。
所以在本文中,作者模仿人类的能力,设计了一个双阶段开集目标检测 Open-Vocabulary object Detection(OVD)
- 首次提出了使用 image-caption pairs 来获得无限的词汇,类似于人类从自然语言中学习一样,然后使用部分标注实例来学习目标检测
- 这样就能够仅仅使用有限类别的标注样本就可以了,其他的就从 caption 中来学习
- 这些样本对儿获得起来更加方便,而且网络上就有很多现成的
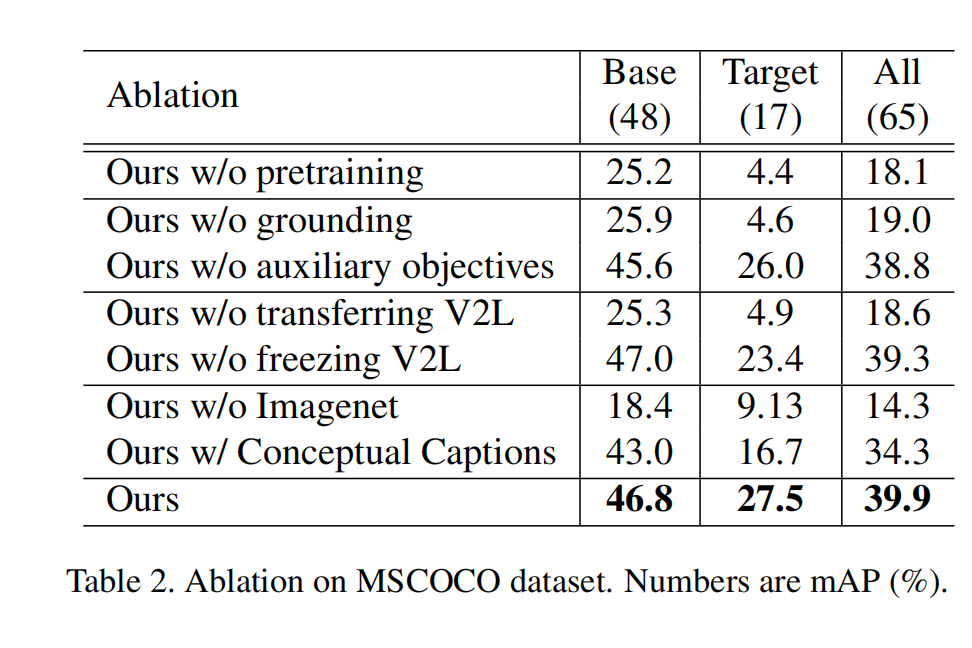
图 2 展示了几种非常相近的任务的差别:
- Open-vocabulary:通过语言词汇来将目标类和基础类进行关联
- Zero-Shot:主要目标是实现从见过的类上扩展到没见过的类上
- Weaky Supervised:

二、方法
大体框架结构如图 1 所示:
- 要训练能检测任何目标( target vocabulary: V T V_T VT)的模型需要下面的几种信息
- 大量的 image-caption 数据集(包含大量的多样的单词): V C V_C VC
- 较少数据量的检测数据集(有基础类别框标注信息): V B V_B VB
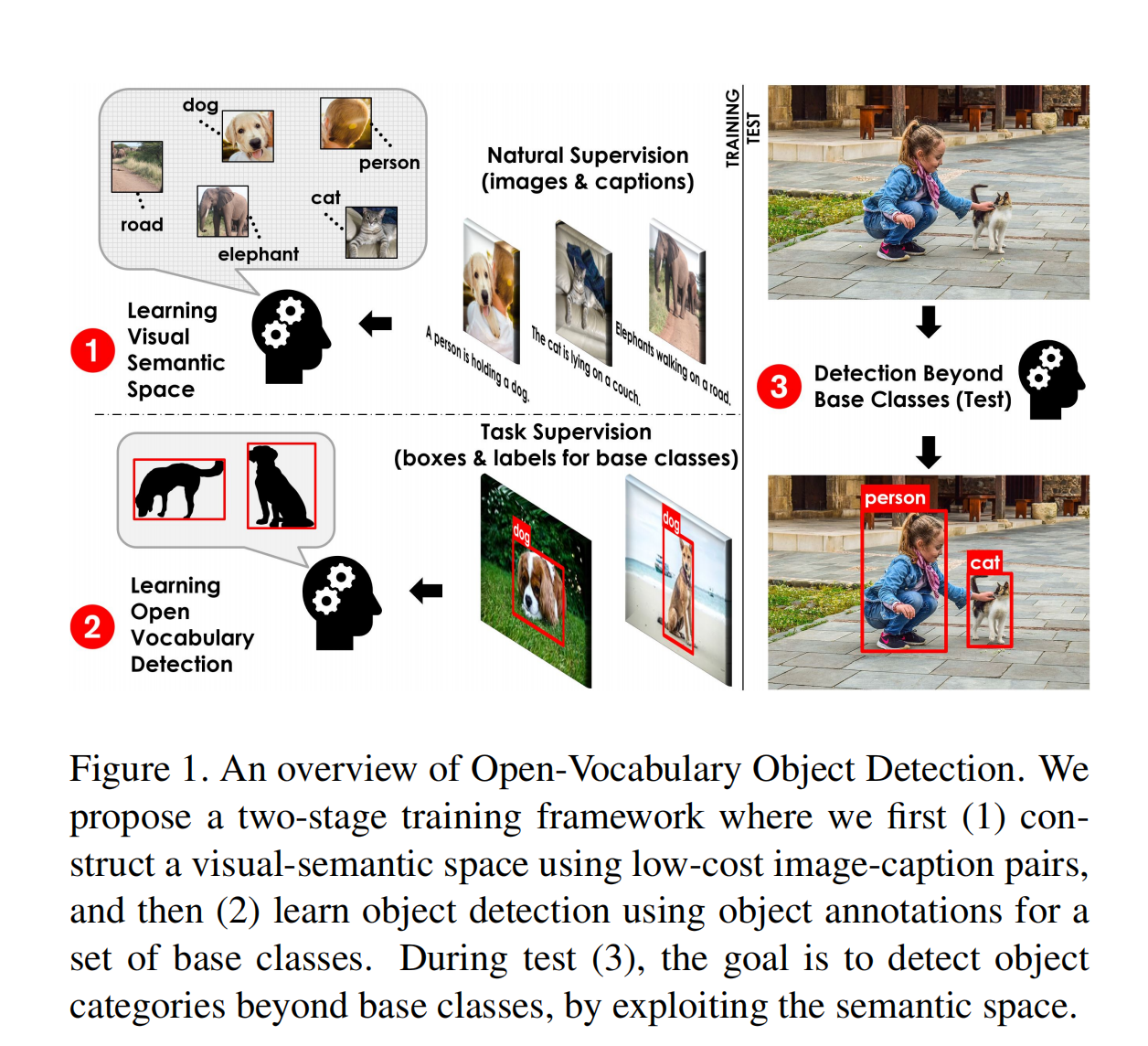
图 3 展示了详细的结构:
-
本文方法基于 Faster R-CNN,在基础类别上进行训练,在目标类别上进行测试
-
预训练:为了避免在基础类别上过拟合,作者在大量词汇量 V C V_C VC 下进行了预训练(上半部分),让模型能够学习到更全面的语义信息,而不是只有基础类别的语义信息。即在 image-caption pairs 上通过 grounding、masked language modeling (MLM) 、 image-text matching 来训练 ResNet 和 V2L layer,V2L layer 是 vision2language 模块,负责将视觉特征变换到文本空间,好让两个不同模态的特征能在同一空间来衡量相似性。
-
训练:预训练后使用得到的 ResNet 和 V2L layer 来初始化 Faster R-CNN ,以此来实现开放词汇目标检测,ResNet 50 用于 backbone,V2L layer 是会用于对每个 proposal 特征进行变换的,变换之后会与类别标签的文本特征计算相似度来进行分类的,训练的时候会固定 V2L layer 的,使其学习到的广泛的信息能够泛化到新类
-
整个模型框架和 Faster RCNN 一样,只是将最后的 cls head 替换成了 V2L,也就是换成了一个将 visual feature 投影到 text embedding space 的投影矩阵
2.1 学习 视觉-语义 空间
本文提出了一个 Vision to Language(V2L)映射层,和 CNN 一起在预训练中进行学习,使用 grounding 任务和和一些辅助自监督任务来训练 CNN 和 V2L layer。
-
输入:image-caption pairs
-
特征提取:image 输入 visual backbone(ResNet50),caption 输入 language backbone(BERT),分别提取对应的特征
-
特征融合:将两种特征输入多模态特征融合器中,来抽取多模态的 embedding
-
目标:让每个 caption 的 word embedding 和其对应的图像区域更加接近,且作者设定了一个 global grounding score 来度量其关系,成对儿的 image-caption 得分要最大,不成对儿的 image-caption 得分要小

-
负样本对儿:作者使用同一个 batch 中的其他图像作为每个 caption 的negative examples,也使用同一 batch 中的其他 caption 作为每个 image 的 negative examples
-
grounding objective functions 如下:
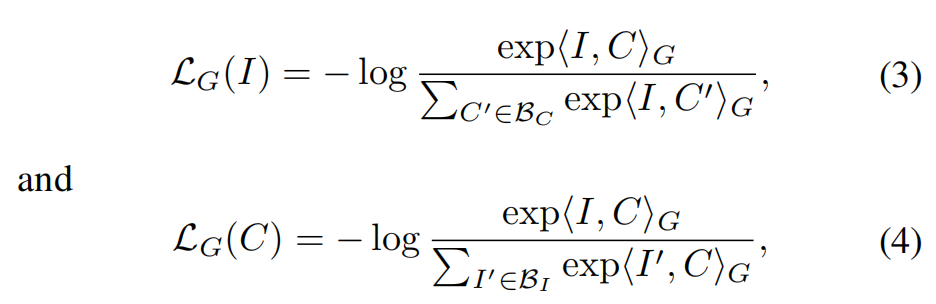
-
最终的 loss:
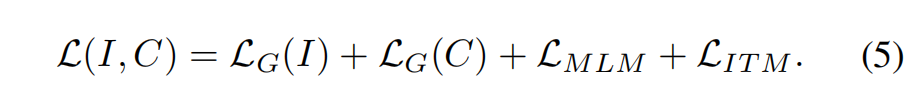
2.2 学习开放词汇目标检测
在完成 ResNet 和 V2L 的预训练后,作者要把其学习到的东西迁移到 object detection 上,方式就是用训练后的特征来初始化 Faster R-CNN
- 首先,使用经过预训练的 ResNet50 的 stem 和前 3 个 block 来抽取图像特征
- 然后,使用 region proposal network 来预测目标可能出现的位置和 objectness score,并且使用 NMS 和 RoI pooling 来得到每个目标框
- 之后,给每个 proposal 使用 ResNet50 的第 4 个 block (和一个 pooling)来提取每个 proposal 的最终特征
- 最终,对比每个 proposal 被编码到 word space 中的特征和基础类别 k 的得分
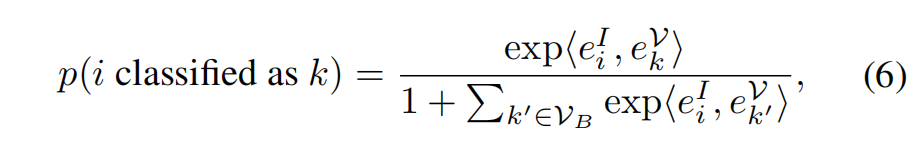
三、效果