用区块链来做网站怎么在百度上投放广告
1. 高级映射
例如有两张表, 分别为班级表和学生表
自然, 一个班级对应多个学生
像这种数据 , 应该如果如何映射到Java的实体类上呢? 这就是高级映射解决的问题
以班级和学生为例子 , 因为一个班级对应多个学生 , 因此学生表中必定有一个班级编号字段cid
但我们在学生的实体类中不需要加入这个字段, 而是通过另一个方法实现一对多映射/多对一映射
1.1 高级映射的分类
-
关联映射(Association Mapping)
关联映射用于处理对象之间的一对一关系。例如,一个订单对象可能包含一个关联的客户对象。通过使用 MyBatis 的关联映射,你可以在查询订单的同时,自动填充每个订单所关联的客户信息。 -
集合映射(Collection Mapping)
集合映射用于处理一对多关系。例如,一个客户可能有多个订单。在 MyBatis 中,你可以定义映射规则来自动将客户的所有订单作为一个集合属性加载到客户对象中。
1.2 前置知识
如何区分主表和副表?
原则: 谁在前谁就是主表
例如
多对一: 多(学生)在前, 多(学生)就是主表
一对多: 一(班级)在前, 一(班级)就是主表
1.2 多对一关系的实现
首先 既然是多(学生)对一(班级)关系 , 此时学生是主表(主对象),
那么学生实体类中应当加入班级对象的声明
private Clazz clazz;
1.2.1 多对一映射的第一种方式 一条SQL语句 , 级联属性映射
仅在studentMapper接口中声明一个方法
<!--id为"studentResultMap"的resultMap的数据 , 按照以下规则映射到实体上 -->
<resultMap id="studentResultMap" type="student"/><!--主键映射 -->
<id property="sid" column="sid"/>
<result property="sname" column="sname"/><!--嵌套的班级对象映射 -->
<result property="clazz.cid" column="cid"/>
<result property="clazz.cname" column="cname"/>
</resultMap><!--id为"selectById"的查询语句, 查询结果放到id为"studentResultMap"的resultMap中 -->
<select id="selectById" resultMap="studentResultMap">selects.sid,s.sname,c.cid,c.cnamefrom <!--多表连接, 主表在前 -->t_student s left join t_clazz c on s.cid= c.cidwheres.sid={sid}
</select>
测试
sout(student.getSid());
sout(student.getClazz().getCid());
sout(student);
1.2.2 多对一映射的第二种方式 , 一条SQL语句 , 采用association标签
在StudentMapper中定义一个新接口方法
Student selectByIdAssociation(Integer id);
<!--id为"studentResultMapAssociation"的resultMap的数据 , 按照以下规则映射到实体上 -->
<resultMap id="studentResultMapAssociation" type="student"/><!--主键映射 -->
<id property="sid" column="sid"/>
<result property="sname" column="sname"/><!--班级属性映射采用Association标签. 一个Student对象关联一个Clazz对象
property指定映射的具体对象 -->
<association property="clazz" javaType="com.sunsplanter.pojo.Clazz"><id property="cid" column="cid"/><result property="cname" column="cname"/>
</association></resultMap><!--id为"selectByIdAssociation"的查询语句, 查询结果放到id为"studentResultMapAssociation"的resultMap中 -->
<select id="selectByIdAssociation" resultMap="studentResultMapAssociation">selects.sid,s.sname,c.cid,c.cnamefrom <!--多表连接, 主表在前 -->t_student s left join t_clazz c on s.cid= c.cidwheres.sid={sid}
</select>
1.2.3 多对一映射的第三种方式 两条SQL语句 ,分步查询
常用 优点是可复用, 且支持懒加载
基本思路是: 既然是多对一, 那么先查询多(学生)的信息, 从中拿到cid , 然后再用cid另外查询一次班级表
两条SQL语句自然要有两个接口方法 ,分别位于StudentMapper和ClazzMapper中
public interface StudentMapper{//分布查询的第一步, 先根据学生的sid查出学生信息 Student selectByIdStep1(Integer sid);}public interface ClazzMapper{//分布查询的第一步, 先根据学生的sid查出学生信息 Clazz selectByIdStep2(Integer cid);}
两个mapperxml文件分别为
<!--id为"studentResultMapAssociation"的resultMap的数据 , 按照以下规则映射到实体上 -->
<resultMap id="studentResultMapByStep" type="com.sunsplanter.pojo.Student"/>
<!--主键映射-->
<id property="sid" column="sid"/>
<result property="sname" column="sname"/><!--班级属性映射采用Association标签. 一个Student对象关联一个Clazz对象
property指定映射的具体对象 -->
<association property="clazz" ><id property="cid" column="cid"/><!--指定第二步SQL语句的ID --><!--将cid字段作为查询传入第二步SQL语句--><select="com.sunsplanter.mapper.ClazzMapper.selectByIdStep2"><column="cid">
</association>
</resultMap><select id="selectByIdStep1" resultMap="studentResultMapByStep">selectsid, sname cid from t_studen where sid = #{sid}
</select>
<!--由于查询的结果与实体属性完全一致, 不需要再写resultMap标签进行结果映射--><select id="selectByIdStep2" resultType="com.sunsplanter.pojo.Clazz">selectcid,cname from t_clazz where cid = #{cid}
</select>
测试结果: 可以发现确实是先查了学生的信息得到cid, 再以cid去查班级信息 ,最终拼接起来输出的

1.2.4 多对一的懒加载
表连接里有一个概念叫笛卡尔积.
越多的表越多的匹配次数.
通过在association标签中增加fetchType="lazy"属性来开启懒加载
或在mybati config文件中的全局的setting标签中开启
<settings>
<setting name="lazyLoadingEnabled" value="true/">
</settings>
实际开发中往往是这样:
先在全局开启懒加载 , 对于特定需要全部加载的语句
通过在association标签中增加fetchType="eager"属性来关闭懒加载
1.2.5 测试
在上例中 , 假如我们没有开启懒加载
此时我们只需要完整的学生信息.
sout(Student);
仍会执行两条语句, 查询两张表, 即使根本没用到第二张表
开启懒加载后 , 便只会执行第一条selectByIdStep1的SQL语句
1.3 一对多关系的实现
需求: 根据班级ID查询指定班级下的所有学生信息
一(班级)对多(学生) , 因此班级是主表
一对多的实现 ,通常是在一(班级)的一方声明一个List集合属性
在班级类中增加
private List<Student> stus;
1.3.1 一对多映射的第一种实现 collection
与多对一并无本质区别, 核心是resultMap标签中的association标签换为collection标签
<!--id为"clazzResultMap"的resultMap的数据 , 按照以下规则映射到实体上 -->
<resultMap id="clazzResultMap" type="com.sunsplanter.pojo.clazz"/>
<!--主键映射-->
<id property="cid" column="cid"/>
<result property="cname" column="cname"/><!-- property属性指定Clazz实体类中定义的List的名称 , ofType指定Clazz实体类中定义的List中的存储对象-->
<collection property="stus" ofType="com.sunspalnter.pojo.Student" ><id property="sid" column="sid"/><result property="sname" column="sname"/>
</collection>
</resultMap>
测试结果, 可以看到班级表(主表)左外连接学生表

1.3.2 一对多映射的第一种实现 分步查询
<!--id为"clazzResultMapStep"的resultMap的数据 , 按照以下规则映射到实体上 -->
<resultMap id="clazzResultMapStep" type="com.sunsplanter.pojo.clazz"/>
<!--主键映射-->
<id property="cid" column="cid"/>
<result property="cname" column="cname"/><!-- property属性指定Clazz实体类中定义的List的名称 , ofType指定Clazz实体类中定义的List中的存储对象-->
<collection property="stus" <!--select指定第二步的SQL语句ID , column指定将cid字段作为参数传入第二步-->select="com.sunsplanter.mapper.StudentMapper.selectByCidStep2" column="cid"/>
</resultMap><select id="selectByIdStep1" resultMap="clazzResultMapStep">selectcid,cname from t_clazz where cid = #{cid}
</select>
<select id="selectByCidStep2" resultType="com.sunsplanter.pojo.Student">selectsid,sname from t_student where sid = #{sid}
</select>
测试结果

1.4 多对多和一对一
多对多实际就是分解为两个一对多
2. 缓存
缓存的作用: 通过减少IO的方式,来提高程序的执行效率
常用的缓存技术有: 字符串常量池 , 整型数常量池 , 线程池 , 连接池
mybats的缓存存:将select语的查询结果放到到缓存(内存)
下次还是这条select的话,直接从缓存(内存)中取,不再从外存中查.
mybatis缓存包括:
- 一级缓存:将查询到的数据存储到SqlSession中。
- 二级缓存:将查询到的数据存储到SqlSessionFactory中 , 缓存空间更大
- 或者集成其它第三方的缓存: 比如EhCache[Java语言开发的]、Memcache[C语言开发的]
缓存只针对于DQL语句,也就是说缓存机制只对应select语句.
2.1 一级缓存
一级缓存默认是开启的。不需要做任何配置
2.1.1 一级缓存生效
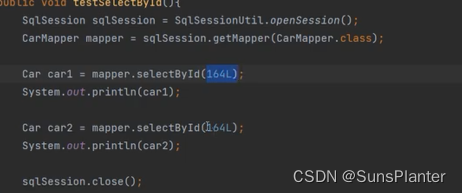
原理:只要使用同一个SqlSession对象执行同一条SQL语句,就会走缓存
可以看到 ,当使用同一个sqlSession对象执行相同的SQL语句时, 后台实际只执行了一次, 却输出了两条结果

2.1.1 一级缓存失效
- sqlSession对象不是同一个肯定不走缓存
- 查询条件不一样肯定不走缓存
- 即使上述同时两个条件, 如果在第一次DQL和第二次DQL之间发生以下两件事情的任意一件, 会令缓存清空
a. 执行了sqlSession的clearCache()方法 , 这会手动清空一级缓存
b. 执行了INSERT/DELETE/UPDATE任意一个语句时 , 不管是操作哪张表 都会直接清空一级缓存(思想是避免修改了数据后 , 输出缓存中的假数据)
2.2 二级缓存
2.2.1 二级缓存生效
使用二级缓存必须同时具备以下条件