南宁网站建设产品介绍网络营销策划与推广

以下内容整理自2023年夏季学期大数据能力提升项目《大数据实践课》同学们所做的期末答辩汇报。
我们汇报的题目是基于在线监控数据的非现场监管问题识别模型研究,我们的汇报将从五个部分展开。首先是项目背景说明,该项目是为了遏制企业逃避监管行为的发生,快速识别企业可能存在的数据篡改和数据造假的行为,提高识别企业这些行为的效率和准确度。
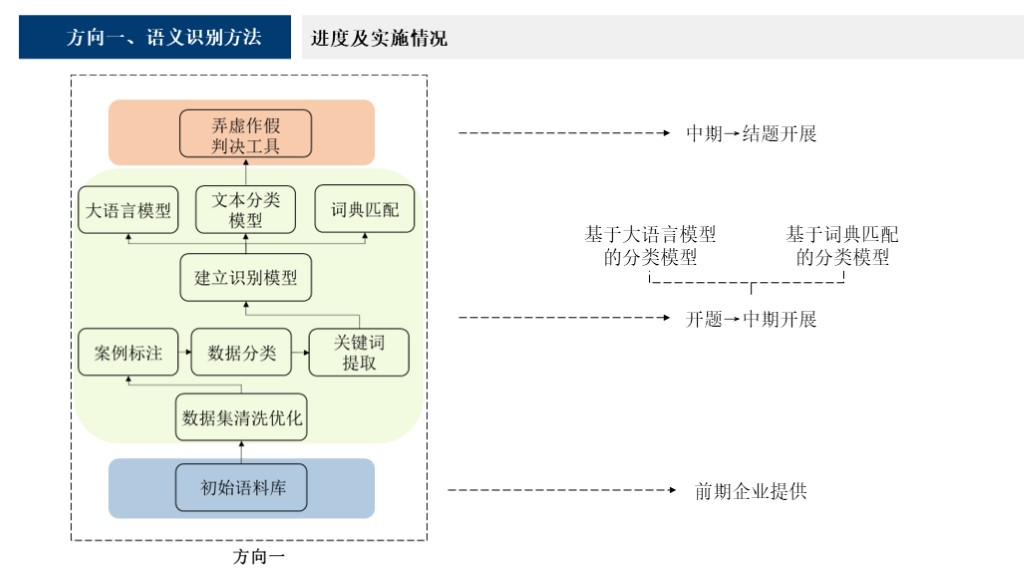
我们的项目从两个方向进行展开。第一个方向是语义识别,上图展现了我们的整体进度和实施情况,目前已经按照项目前期计划全部完成。首先,我们根据老师给的文本内容划分了水污染、大气污染和其他三种类型,确定了其中弄虚造假的行为,对所有的案例都进行了人工标注和分类并且从这些案例文本中提取了特征作为关键词。

为了提高准确率,我们采用了两种方法,第一种是基于词典匹配的文本分类模型,建立了阴性词典和阳性词典进行全局的精确匹配。建立词典后,我们发现假阴性和假阳性比例较高,因此对词库进行了优化,对数值类和短句类案例文本进行了处理,最后达到了80%的准确率。方法二使用了大语言模型,我们通过调研现有开源的对话类模型可能存在数据泄露及API无法调用的问题,所以我们最后采用了基于RoBERTa的文本分类模型,在我们标注的案例上进行了训练和微调。
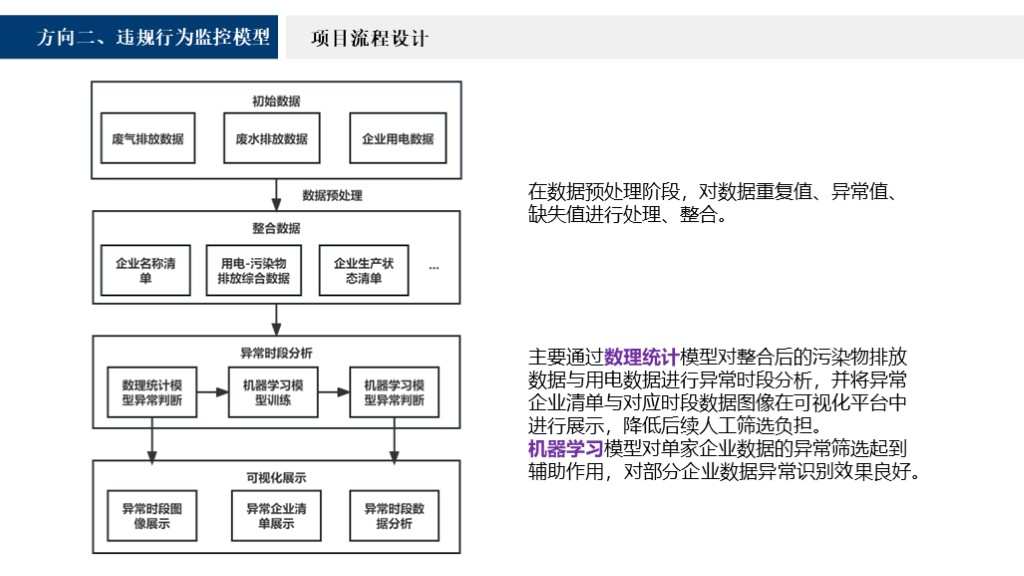
接下来是违规行为监控模型。上图是我们模型流程的整体设计,首先对数据进行预处理,通过数理统计模型对整合后污染物排放数据与用电数据进行异常时段分析,并得出异常企业清单进行展示,降低后续的人工筛选负担。机器学习模型主要是对单企业数据异常筛选起到辅助作用,对部分企业的数据异常识别效果良好。
以下是数据预处理部分。这部分问题在于按照原有构想,项目实现的方案为建立污染物排口、排放量及用电数据的一一对应关系,通过识别二者相关性来识别企业是否有弄虚作假现象。但到实际情况中,是无法获得污染物排口到具体用电设备的映射关系的,因此需要对数据进行进一步处理。
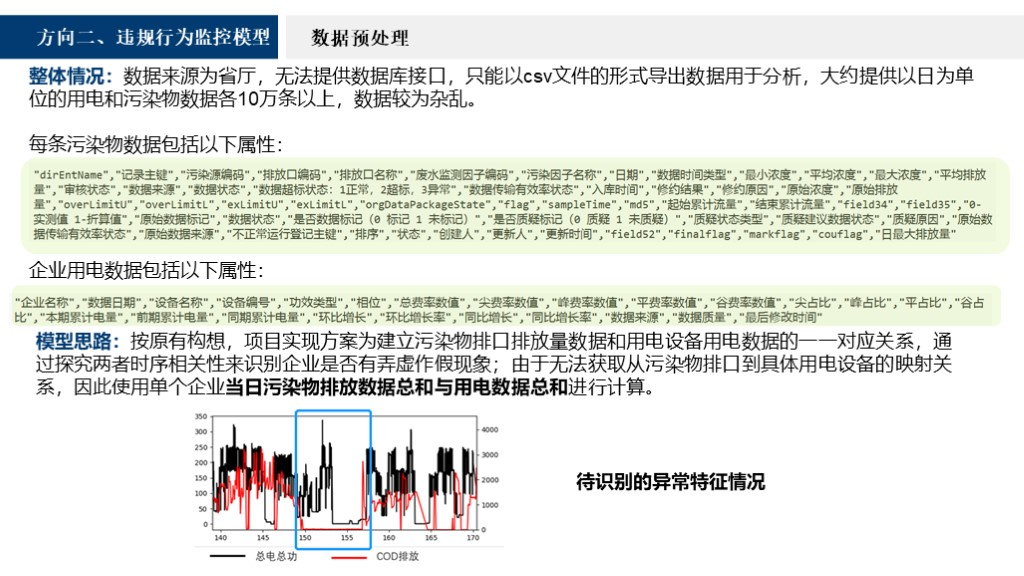
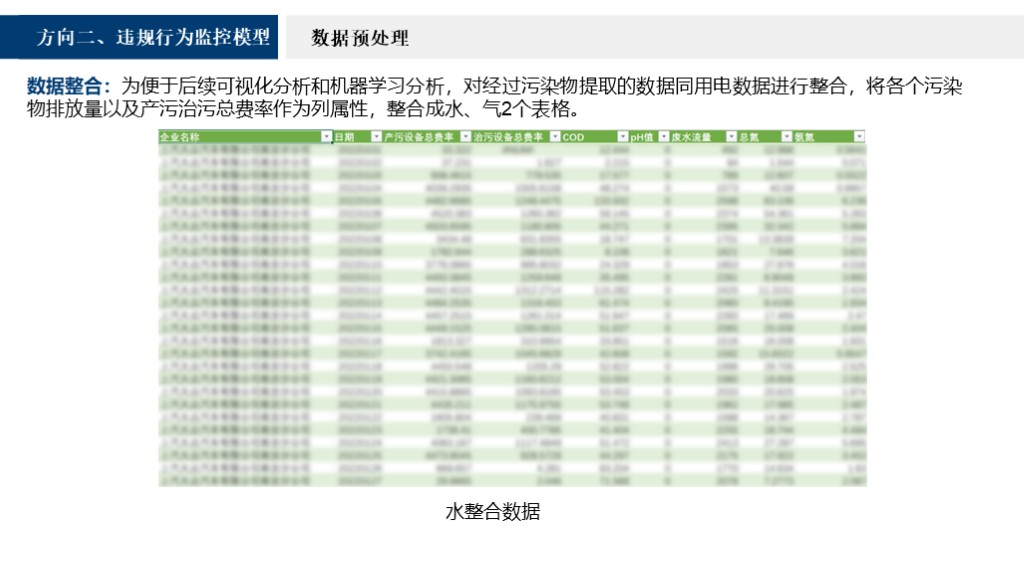
我们对数据进行聚合提取,包括对一些污染物排口及用电设备不同类型进行求和处理然后提取出相应的表格。为了便于后续数据统计分析和机器学习,我们对数据进行整合,最终提取出如下的表,每一行是一个样本数据,包括日期、用电量以及各个污染物的数据。
之后首先进行了可视化分析,对单个企业一年内对应的用电与污染数据进行了综合时序分析。结合先验知识,对时序图的部分时段进行了异常特征提取,作为后续判断异常时段的准则。
对于异常判断的算法,我们使用了一种基于滑动窗口的无监督学习方法,判断企业用电数据与污染物排放数据是否出现异常状态。该算法的优点在于其采用无监督的方法对企业数据进行判断,可以不依赖于历史异常规则数据库,从而根据企业需求的特定异常状态进行针对性分析判断,提高准确性。该方法将污染物判断与用电数据多维时间序列全局点异常检测放缩到一个窗口的局部异常检测,并高度利用弄虚作假场景下的相关实际需求完成知识驱动,从而达成目标。
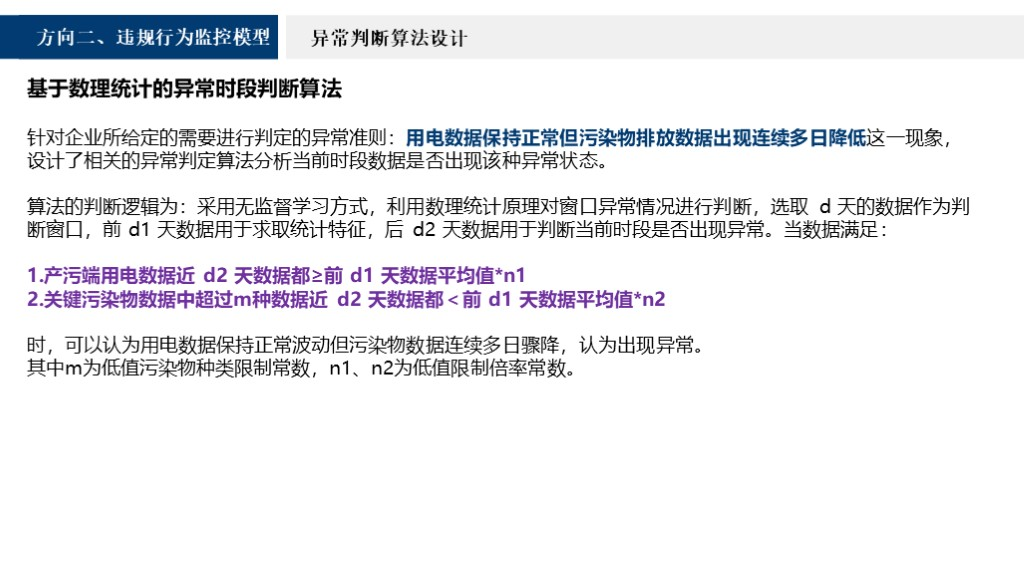
具体的准则就是用电数据正常但污染物排放数据出现连续多日降低,具体的算法是,数据要满足产污端用电数据近d2天数据都大于等于前d1天数据平均值,关键污染物数据中超过m种数据近d2天数据都小于前d1一天数据平均值,此时可以认为用电数据保持正常波动但污染物数据连续多日骤降,认为出现异常。
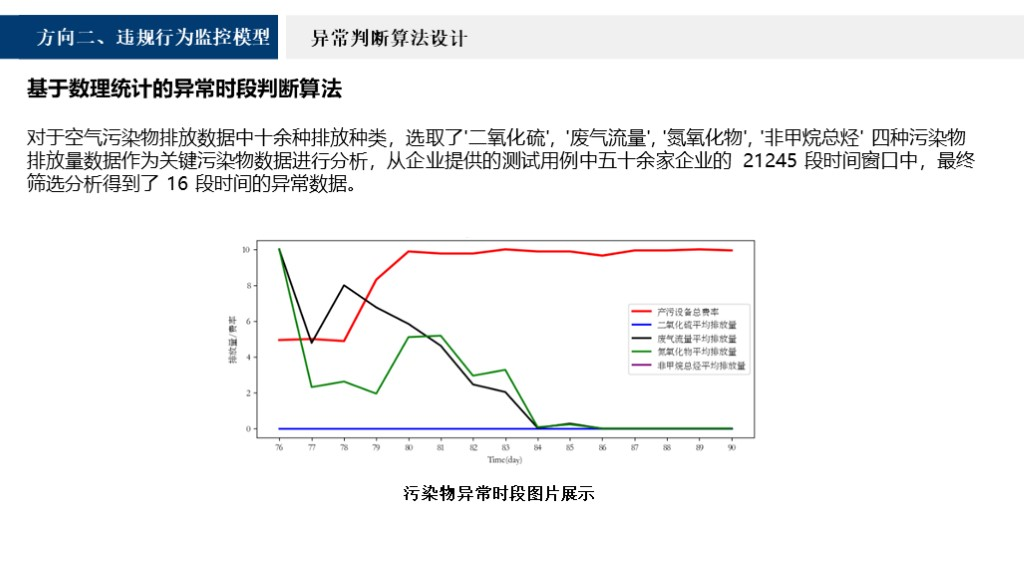
对于空气污染排放数据中的十余种排放种类,选取了“二氧化硫”、“废气流量”、“氮氧化物”,“非甲烷总烃”四种污染物排放数据作为关键污染物数据进行分析,从企业提供的测试用例中五十余家企业的21234段时间窗口中,最终筛选分析得到了16段时间的异常数据。
之后是机器学习的算法,主要有以下几点问题,不同企业得到的模型泛化性非常差,不同企业污染物种类差异很大,用电量和污染物之间的关系也有很大不同;虽然数据整体量很大,但这是基于多家企业的,实际上单企业一年半的时间跨度只有500条数据;由于第一部分提供的数据量较小,对于同一家公司来说,第一部分提供的标签数据量不足以识别出第二部分的所有异常;实际测试下来还有一部分预测效果并不佳。
我们讨论得出了一些解决方案。首先,在数据预处理和整合阶段,区别于数理统计分析可以针对所有企业,机器学习模型只针对某一家公司构建。第二点,我们经过讨论认定当天用电量基本只与当天污染物排放有关,因此没有采用常见的时序建模,而是采用了常规机器学习模型。我们选定预测用电量这种方法进行异常识别。选取“治污设备总费率”作为标签,使用其他污染物数据以及“产污设备总费率”去预测,当测试集实际偏差大于验证集RMSE时,认为测试集当天数据出现异常;另一方面,我们没有根据精确调参,而是在初步调参的基础上搭建机器学习训练的框架,方便企业后续得到更多优质数据集后训练优质模型。最后,我们使用一个默认的随机森林模型对各个公司数据进行一个初步判断,当初步训练验证集RMSE值较小时认为该企业数据适合机器学习模型。由于不同企业用电量数值波动范围不同,当我们用Ta=RMSE/Xmax这个参数来对比各企业的效果,最终结合具体数据的图像,设定Ta<0.1为企业可考虑使用上述机器学习方法进行异常初步判断的标准,该值越小,识别精确度越高。
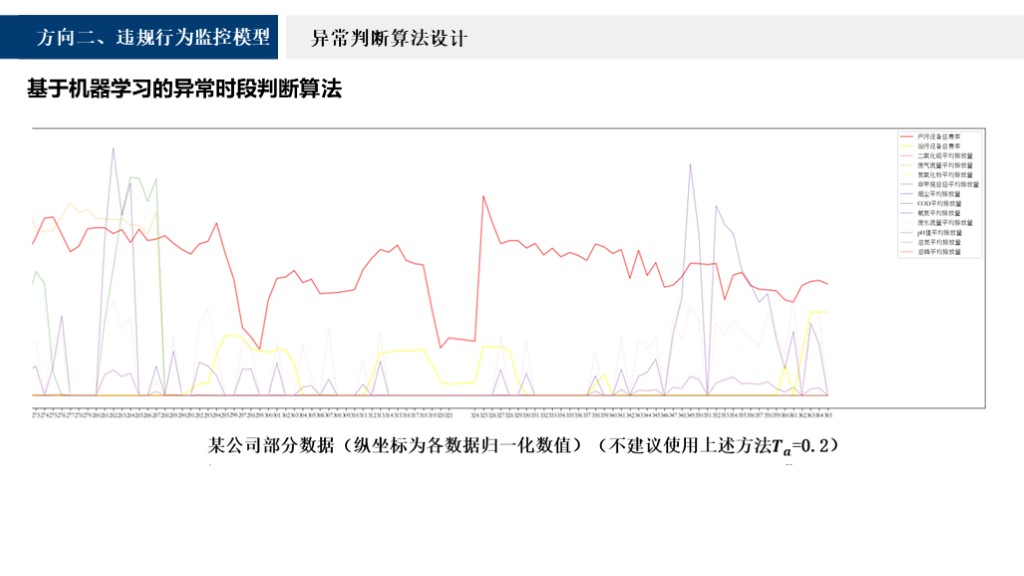
上图展示了某公司的部分模型预测数据。从上图可以发现,产污设备总费率以及污染物之间有很明显的一一对应的相关关系,这种数据用机器学习训练的模型Ta值等于0.05,是比较小的,当Ta等于0.2时,该方法效果变得比较差,污染物与产污设备总费率之间也难以看出一一对应的相关关系。
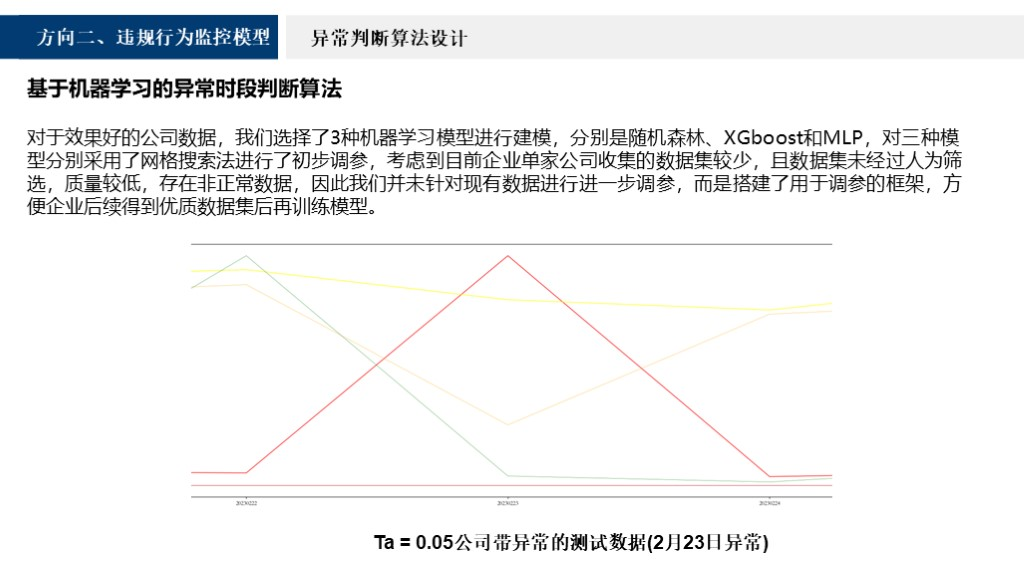
对于效果好的公司数据,我们选择三种机器学习模型进行建模,分别是随机森林、XGboost和MLP,对三种模型分别采用网格搜索法进行初步调参。考虑到目前企业单家公司收集的数据集较少,且无法经过人为筛选,第一部分提供的标签异常量不足,所以我们并未针对现有数据进行进一步调参,而是搭建了用于调参的框架,方便企业后续得到优质数据集后再训练模型。如下图所示,Ta等于0.05公司带异常的测试数据,可以看到2月23号有一个反常的治污用电量增量,通过模型就可以直接识别出来。
最后是项目总结部分。下图分别展示了我们在语义识别和违规监控方向上的成果及未来改进方向。


以上是本次汇报的全部内容。
编辑:文婧
校对:林亦霖
