网站建设服务器端软件营销网络的建设有哪些
论文链接:https://arxiv.org/pdf/1408.5882.pdf
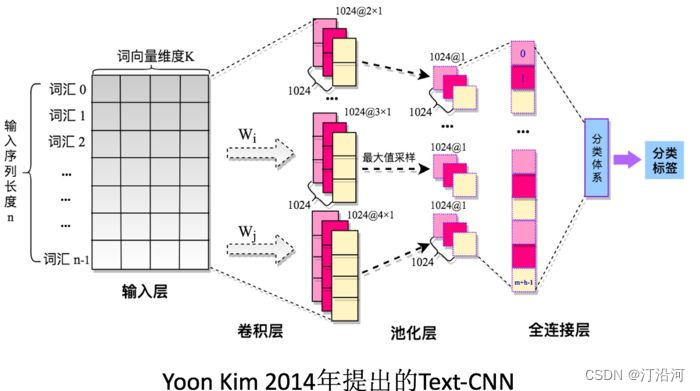
TextCNN 是一种用于文本分类的卷积神经网络模型。它在卷积神经网络的基础上进行了一些修改,以适应文本数据的特点。
TextCNN 的主要思想是使用一维卷积层来提取文本中的局部特征,并通过池化操作来减少特征的维度。这些局部特征可以捕获词语之间的关系和重要性,从而帮助模型进行分类。
nn.Conv2d
nn.Conv2d的构造函数包含以下参数:
in_channels:输入数据的通道数。out_channels:卷积核的数量,也是输出数据的通道数。kernel_size:卷积核的大小,可以是一个整数或一个元组,表示宽度和高度。stride:卷积核的步幅,可以是一个整数或一个元组,表示水平和垂直方向的步幅。nn.Conv2d(1, config.num_filters, (k, config.embed))
输入通道是1 , 输出通道的维度, 卷积核(k, config.embed))
代码部分:
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import pickle as pkl
from tqdm import tqdm
import time
from torch.utils.data import Datasetfrom datetime import timedeltafrom sklearn.model_selection import train_test_split
from torch.utils.data import Dataset, DataLoader
from collections import defaultdict
from torch.optim import AdamWdf = pd.read_csv("./data/online_shopping_10_cats.csv")
UNK, PAD = '<UNK>', '<PAD>' # 未知字,padding符号
RANDOM_SEED = 2023file_path = "./data/online_shopping_10_cats.csv"
vocab_file = "./data/vocab.pkl"
emdedding_file = "./data/embedding_SougouNews.npz"
vocab = pkl.load(open(vocab_file, 'rb'))class MyDataSet(Dataset):def __init__(self, df, vocab,pad_size=None):self.data_info = dfself.data_info['review'] = self.data_info['review'].apply(lambda x:str(x).strip())self.data_info = self.data_info[['review','label']].valuesself.vocab = vocab self.pad_size = pad_sizeself.buckets = 250499 def biGramHash(self,sequence, t):t1 = sequence[t - 1] if t - 1 >= 0 else 0return (t1 * 14918087) % self.bucketsdef triGramHash(self,sequence, t):t1 = sequence[t - 1] if t - 1 >= 0 else 0t2 = sequence[t - 2] if t - 2 >= 0 else 0return (t2 * 14918087 * 18408749 + t1 * 14918087) % self.bucketsdef __getitem__(self, item):result = {}view, label = self.data_info[item]result['view'] = view.strip()result['label'] = torch.tensor(label,dtype=torch.long)token = [i for i in view.strip()]seq_len = len(token)# 填充if self.pad_size:if len(token) < self.pad_size:token.extend([PAD] * (self.pad_size - len(token)))else:token = token[:self.pad_size]seq_len = self.pad_sizeresult['seq_len'] = seq_len# 词表的转换words_line = []for word in token:words_line.append(self.vocab.get(word, self.vocab.get(UNK)))result['input_ids'] = torch.tensor(words_line, dtype=torch.long) # bigram = []trigram = []for i in range(self.pad_size):bigram.append(self.biGramHash(words_line, i))trigram.append(self.triGramHash(words_line, i))result['bigram'] = torch.tensor(bigram, dtype=torch.long)result['trigram'] = torch.tensor(trigram, dtype=torch.long)return resultdef __len__(self):return len(self.data_info)#myDataset[0]
df_train, df_test = train_test_split(df, test_size=0.1, random_state=RANDOM_SEED)
df_val, df_test = train_test_split(df_test, test_size=0.5, random_state=RANDOM_SEED)
df_train.shape, df_val.shape, df_test.shape#((56496, 3), (3139, 3), (3139, 3))def create_data_loader(df,vocab,pad_size,batch_size=4):ds = MyDataSet(df,vocab,pad_size=pad_size)return DataLoader(ds,batch_size=batch_size)MAX_LEN = 256
BATCH_SIZE = 4
train_data_loader = create_data_loader(df_train,vocab,pad_size=MAX_LEN, batch_size=BATCH_SIZE)
val_data_loader = create_data_loader(df_val,vocab,pad_size=MAX_LEN, batch_size=BATCH_SIZE)
test_data_loader = create_data_loader(df_test,vocab,pad_size=MAX_LEN, batch_size=BATCH_SIZE)class Config(object):"""配置参数"""def __init__(self):self.model_name = 'FastText'self.embedding_pretrained = torch.tensor(np.load("./data/embedding_SougouNews.npz")["embeddings"].astype('float32')) # 预训练词向量self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 设备self.dropout = 0.5 # 随机失活self.require_improvement = 1000 # 若超过1000batch效果还没提升,则提前结束训练self.num_classes = 2 # 类别数self.n_vocab = 0 # 词表大小,在运行时赋值self.num_epochs = 20 # epoch数self.batch_size = 128 # mini-batch大小self.learning_rate = 1e-4 # 学习率self.embed = self.embedding_pretrained.size(1)\if self.embedding_pretrained is not None else 300 # 字向量维度self.hidden_size = 256 # 隐藏层大小self.n_gram_vocab = 250499 # ngram 词表大小self.filter_sizes = [2,3,4]self.num_filters = 256 # 卷积核数量(channels数)class Model(nn.Module):def __init__(self, config):super(Model, self).__init__()if config.embedding_pretrained is not None:self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)else:self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)self.convs = nn.ModuleList([nn.Conv2d(1, config.num_filters, (k, config.embed)) for k in config.filter_sizes])# self.convs = nn.ModuleList(# [nn.Conv1D(1, config.num_filters, k) for k in config.filter_sizes]# )self.dropout = nn.Dropout(config.dropout)self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)def conv_and_pool(self, x, conv):x = F.relu(conv(x)).squeeze(3)x = F.max_pool1d(x, x.size(2)).squeeze(2)return xdef forward(self, x):out = self.embedding(x['input_ids'])out = out.unsqueeze(1)out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)out = self.dropout(out)out = self.fc(out)return outconfig = Config()
model = Model(config)
sample = next(iter(train_data_loader))device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)EPOCHS = 5 # 训练轮数
optimizer = AdamW(model.parameters(),lr=2e-4)
total_steps = len(train_data_loader) * EPOCHS
# schedule = get_linear_schedule_with_warmup(optimizer,num_warmup_steps=0,
# num_training_steps=total_steps)
loss_fn = nn.CrossEntropyLoss().to(device)def train_epoch(model,data_loader,loss_fn,device, optimizer,n_examples,schedule=None):model = model.train()losses = []correct_predictions = 0for d in tqdm(data_loader):# input_ids = d['input_ids'].to(device)# attention_mask = d['attention_mask'].to(device)targets = d['label']#.to(device)outputs = model(d)_,preds = torch.max(outputs, dim=1)loss = loss_fn(outputs,targets)losses.append(loss.item())correct_predictions += torch.sum(preds==targets)loss.backward()nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)optimizer.step()#scheduler.step()optimizer.zero_grad()#break#print(n_examples)return correct_predictions.double().item() / n_examples, np.mean(losses)def eval_model(model, data_loader, loss_fn, device, n_examples):model = model.eval() # 验证预测模式losses = []correct_predictions = 0with torch.no_grad():for d in data_loader:targets = d['label']#.to(device)outputs = model(d)_, preds = torch.max(outputs, dim=1)loss = loss_fn(outputs, targets)correct_predictions += torch.sum(preds == targets)losses.append(loss.item())return correct_predictions.double() / n_examples, np.mean(losses)# train model
EPOCHS = 10
history = defaultdict(list) # 记录10轮loss和acc
best_accuracy = 0for epoch in range(EPOCHS):print(f'Epoch {epoch + 1}/{EPOCHS}')print('-' * 10)train_acc, train_loss = train_epoch(model,train_data_loader,loss_fn = loss_fn,optimizer=optimizer,device = device,n_examples=len(df_train))print(f'Train loss {train_loss} accuracy {train_acc}')val_acc, val_loss = eval_model(model,val_data_loader,loss_fn,device,len(df_val))print(f'Val loss {val_loss} accuracy {val_acc}')print()history['train_acc'].append(train_acc)history['train_loss'].append(train_loss)history['val_acc'].append(val_acc)history['val_loss'].append(val_loss)if val_acc > best_accuracy:torch.save(model.state_dict(), 'best_model_state.bin')best_accuracy = val_acc一维卷积模型,直接替换就行了
class Model(nn.Module):def __init__(self, config):super(Model, self).__init__()if config.embedding_pretrained is not None:self.embedding = nn.Embedding.from_pretrained(config.embedding_pretrained, freeze=False)else:self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)# self.convs = nn.ModuleList(# [nn.Conv2d(1, config.num_filters, (k, config.embed)) for k in config.filter_sizes])self.convs = nn.ModuleList([nn.Conv1d(MAX_LEN, config.num_filters, k) for k in config.filter_sizes])self.dropout = nn.Dropout(config.dropout)self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)def conv_and_pool(self, x, conv):#print(x.shape)x = F.relu(conv(x))#.squeeze(3)#print(x.shape)x = F.max_pool1d(x, x.size(2))#.squeeze(2)return xdef forward(self, x):out = self.embedding(x['input_ids'])#print(out.shape)#out = out.unsqueeze(1)out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)out = out.squeeze(-1)#print(out.shape)out = self.fc(out)return outEpoch 1/10 ----------
100%|█████████████████████████████████████| 14124/14124 [08:19<00:00, 28.29it/s]
Train loss 0.32963800023092527 accuracy 0.889903709997168 Val loss 0.2872631916414839 accuracy 0.9197196559413826Epoch 2/10 ----------
100%|█████████████████████████████████████| 14124/14124 [08:19<00:00, 28.25it/s]
Train loss 0.26778308933985917 accuracy 0.925392948173322 Val loss 0.29051536209677714 accuracy 0.9238611022618668Epoch 3/10 ----------
100%|█████████████████████████████████████| 14124/14124 [08:17<00:00, 28.39it/s]
Train loss 0.23998896145841375 accuracy 0.9368450863777966 Val loss 0.29530937147389363 accuracy 0.9238611022618668Epoch 4/10 ----------
100%|█████████████████████████████████████| 14124/14124 [08:21<00:00, 28.14it/s]
Train loss 0.21924698638110582 accuracy 0.9446863494760691 Val loss 0.3079132618505083 accuracy 0.9260911118190507Epoch 5/10 ----------
100%|█████████████████████████████████████| 14124/14124 [08:21<00:00, 28.15it/s]
Train loss 0.1976975509786261 accuracy 0.9515717926932881 Val loss 0.3294101043627459 accuracy 0.9267282574068174Epoch 6/10 ----------
100%|█████████████████████████████████████| 14124/14124 [08:14<00:00, 28.56it/s]
Train loss 0.18130036814091913 accuracy 0.9575899178702917 Val loss 0.34197808585767564 accuracy 0.9260911118190507Epoch 7/10 ----------
100%|█████████████████████████████████████| 14124/14124 [09:03<00:00, 26.00it/s]
Train loss 0.16165128718584662 accuracy 0.9624044180118947 Val loss 0.34806641904714486 accuracy 0.924816820643517
conv1D:
Epoch 1/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:53<00:00, 48.14it/s]Train loss 0.4587948323856965 accuracy 0.7931711979609176 Val loss 0.3846700458902963 accuracy 0.8738451736221726Epoch 2/10 ----------100%|█████████████████████████████████████| 14124/14124 [05:21<00:00, 43.93it/s]Train loss 0.3450994613828836 accuracy 0.8979219767771169 Val loss 0.39124348195663816 accuracy 0.8932781140490602Epoch 3/10 ----------100%|█████████████████████████████████████| 14124/14124 [05:14<00:00, 44.93it/s]Train loss 0.3135276534462201 accuracy 0.9156046445766072 Val loss 0.38953639226077036 accuracy 0.9041095890410958Epoch 4/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:32<00:00, 51.76it/s]Train loss 0.29076329547278607 accuracy 0.926224865477202 Val loss 0.4083191853780146 accuracy 0.9063395985982797Epoch 5/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:33<00:00, 51.70it/s]Train loss 0.2712314691068196 accuracy 0.9351989521382045 Val loss 0.44957431750859633 accuracy 0.9063395985982797Epoch 6/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:28<00:00, 52.56it/s]Train loss 0.2521194787317903 accuracy 0.9424561030869442 Val loss 0.4837963371119771 accuracy 0.9082510353615801Epoch 7/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:28<00:00, 52.64it/s]Train loss 0.2317749120263705 accuracy 0.9494831492495044 Val loss 0.5409662437294889 accuracy 0.9063395985982797Epoch 8/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:29<00:00, 52.39it/s]Train loss 0.2093608888886245 accuracy 0.9562269895213821 Val loss 0.5704389385299592 accuracy 0.9037910162472125Epoch 9/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:28<00:00, 52.68it/s]Train loss 0.1867563983566425 accuracy 0.9619088077032002 Val loss 0.6150021497048127 accuracy 0.9015610066900287Epoch 10/10 ----------100%|█████████████████████████████████████| 14124/14124 [04:29<00:00, 52.45it/s]Train loss 0.16439846786478746 accuracy 0.9669003115264797 Val loss 0.6261858006026605 accuracy 0.9098438993309972
使用Conv2D 的效果比Conv1D的效果好。
最近在忙着打一个数据挖掘的比赛,后续会持续输出,请大家关注,谢谢!