满山红厦门网站建设嘉兴seo外包服务商
本文在笔者之前研发的大模型智能文档问答项目中,开发更进一步,支持多种类型文档和URL链接,支持多种大模型接入,且使用更方便、高效。
项目介绍
在文章NLP(六十一)使用Baichuan-13B-Chat模型构建智能文档中,笔者详细介绍了如何使用Baichuan-13B-Chat模型来构建智能文档问答助手。
一般,使用大模型来实现文档问答功能的流程图如下:
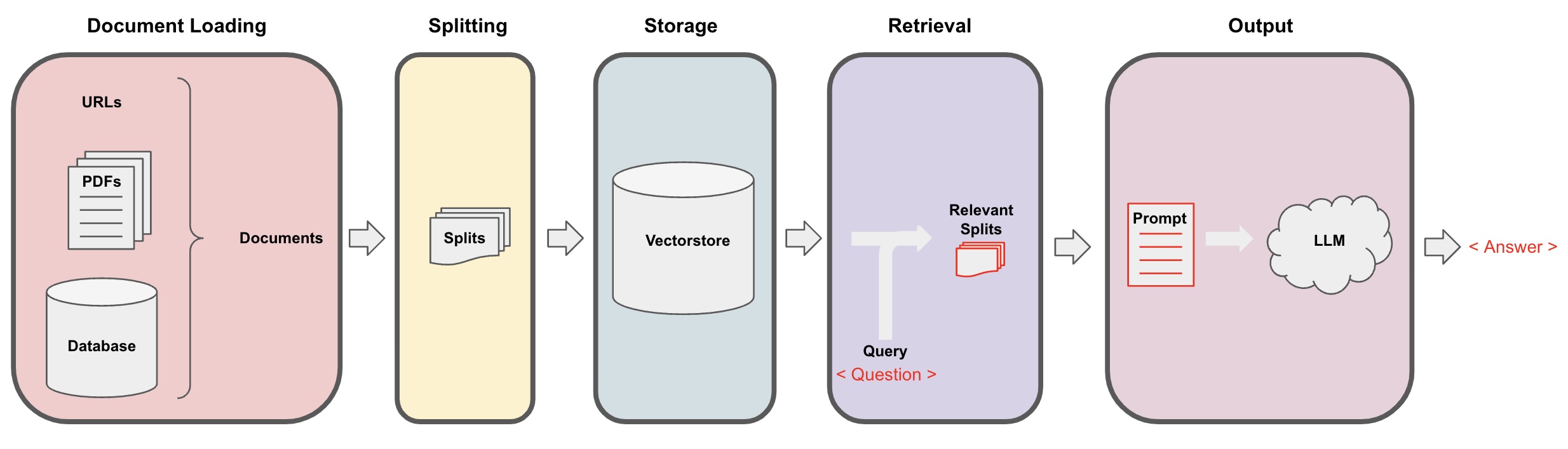
本次,笔者在之前的项目中更进一步,支持的功能如下:
- 支持多种格式文档(包括txt, pdf, docx)和URL链接
- 问答可视化页面
- 问答可追溯,加入高亮显示
- 单/多模型调用
- 模型效果对比
说明如下:
- 支持的文档格式由
LangChain提供,URL链接的解析由LangChain中的 selenium 和 unstructured,可支持JavaScript渲染的页面。但网页解析(或者说爬虫)是一项复杂而艰巨的任务,不可能在本项目中实现所有的网页解析。 - 可视化问答页面由Gradio模块实现
- 支持单模型或多模型调用,并且可以提供问答溯源。同时,还支持不同模型回答结果的比对,该想法来源于OpenCompass .
在工程开发上,加入的特性(features)如下:
- 丰富使用文档
- 加入配置文件
- 增加日志调用
- ES分词器支持用户词典
- Milvus支持初步筛选的阈值配置
本项目已开源至Github,代码实现可参考document_qa_with_llm,这里不再讲解代码细节。
支持文档格式
本项目原先只支持txt格式,现在已支持多种格式文档(包括txt, pdf, docx)和URL链接,这得益于LangChain框架中的文档加载模块,使得各种格式的文档加载变得更加统一、简洁、高效。
本项目中的文件解析脚本如下:
# -*- coding: utf-8 -*-
from langchain.document_loaders import TextLoader, PyPDFLoader, Docx2txtLoader, SeleniumURLLoaderfrom utils.logger import loggerclass FileParser(object):def __init__(self, file_path):self.file_path = file_pathdef txt_loader(self):documents = TextLoader(self.file_path, encoding='utf-8').load()return documentsdef pdf_loader(self):loader = PyPDFLoader(self.file_path)documents = loader.load_and_split()return documentsdef docx_loader(self):loader = Docx2txtLoader(self.file_path)documents = loader.load()return documentsdef url_loader(self):loader = SeleniumURLLoader(urls=[self.file_path])documents = loader.load()return documentsdef parse(self):logger.info(f'parse file: {self.file_path}')if self.file_path.endswith(".txt"):return self.txt_loader()elif self.file_path.endswith(".pdf"):return self.pdf_loader()elif self.file_path.endswith(".docx"):return self.docx_loader()elif "http" in self.file_path:return self.url_loader()else:logger.error("unsupported document type!")return []if __name__ == '__main__':txt_file_path = "/Users/admin/PycharmProjects/document_qa_with_llm/files/gdp.txt"content = FileParser(txt_file_path).parse()print(content)pdf_file_path = "/Users/admin/PycharmProjects/document_qa_with_llm/files/oppo_n3_flip.pdf"content = FileParser(pdf_file_path).parse()print(content)docx_file_path = "/Users/admin/PycharmProjects/document_qa_with_llm/files/haicaihua.docx"content = FileParser(docx_file_path).parse()print(content)url = "https://gaokao.xdf.cn/202303/12967078.html"url = "https://www.hntv.tv/50rd/article/1/1700396378818207745?v=1.0"content = FileParser(url).parse()print(content)
问答测试
文档上传页面如下,支持多种格式文档上传和URL解析(依赖于页面解析能力),页面较为粗糙。

上传后的文件会放至files文件夹上,示例文档可在Github项目中files文件夹中参考。
- txt文件
我们以files/dengyue.txt为例,问答如下:
你知道格里芬的职务吗?
格里芬的职务是美国宇航局局长。
格里芬发表演说时讲了什么?
根据文档知识,格里芬发表演说时讲了如下内容:他认为如果中国人愿意,2020年他们可以实现载人登月工程。此外,叶培建院士也曾发表自己的观点,认为2025年比较合适。然而,根据中国科学院编制的50年长远规划,中国要实现载人登月工程是2030年。
- pdf文件
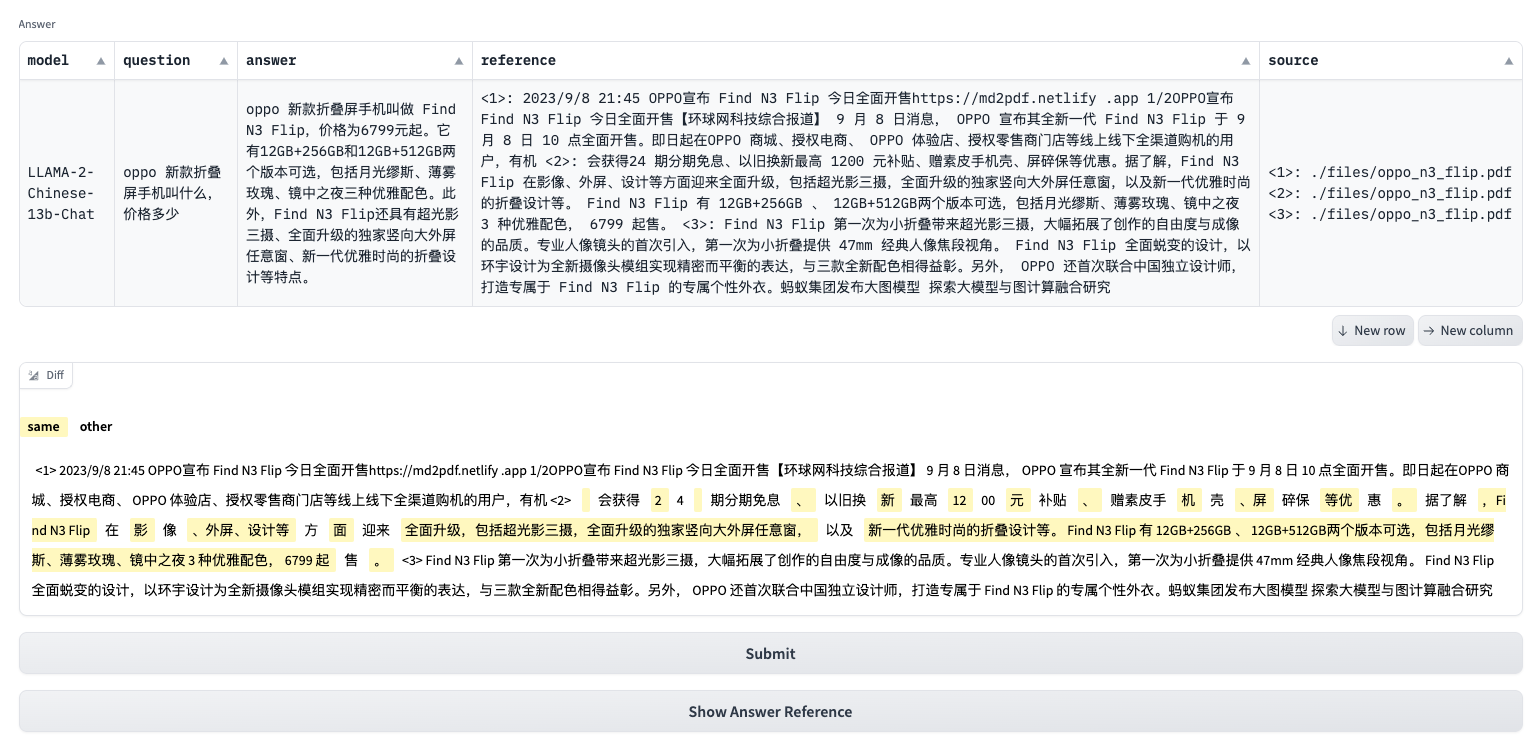
我们以files/oppo_n3_flip.pdf为例,回答如下:
OPPO最新款折叠屏手机叫什么?
OPPO最新款折叠屏手机是OPPO Find N3 Flip。
腾讯有发布自研的大模型吗,什么时候发布的?
是的,腾讯已经发布了自研的大语言模型,名为 “ 混元大模型 ” 。它在 2023 年腾讯全球数字生态大会上正式对外亮相。具体时间为 9 月 7 日。
- docx文件
我们以files/haicaihua.docx为例,回答如下:
海菜花对生长环境有什么要求?
海菜花对生长环境要求极高,只能在水体洁净、透明度较高的水体中生长,被誉为水质的“试金石”。
- URL链接
我们以https://gaokao.xdf.cn/202303/12967078.html 为例,回答如下:
电子科技大学2022年招生多少人?
电子科技大学2022年招生总计划是5030人,其中“电子科技大学”将面向全国招生3300余人,“电子科技大学(沙河校区)”将面向部分省份招生1700余人。
电子科技大学的官网?
电子科技大学的官网是:http://www.zs.uestc.edu.cn/
可视化问答
除了之前的API调用,本项目还支持可视化问答。该功能由Gradio模块实现,支持在页面上进行可视化问答,同时还支持多模型调用,支持的大模型如下:
- Baichuan-13B-Chat: 百川智能发布的模型,现已更新至Baichuan2
- LLAMA-2-Chinese-13b-Chat: 在LLAMA 2模型上进行微调得到的中文对话模型
- internlm-chat-7b:上海人工智能实验室发布的书生(InternLM)对话模型
这些都是中文大模型。理论上,支持的模型由FastChat 和 部署的GPU型号、数量决定,本项目只考虑以上三种。
该页面支持多模型或单模型的问答。多模型问答时,可比较不同模型在相同的Prompt下的回答效果,作为模型评估的一种方式。
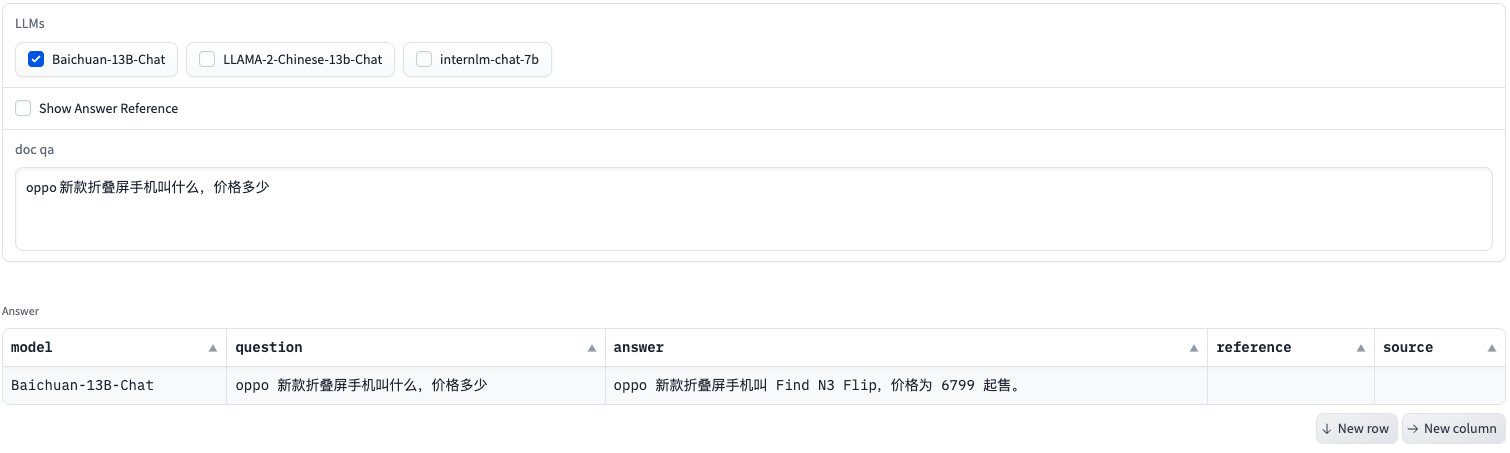
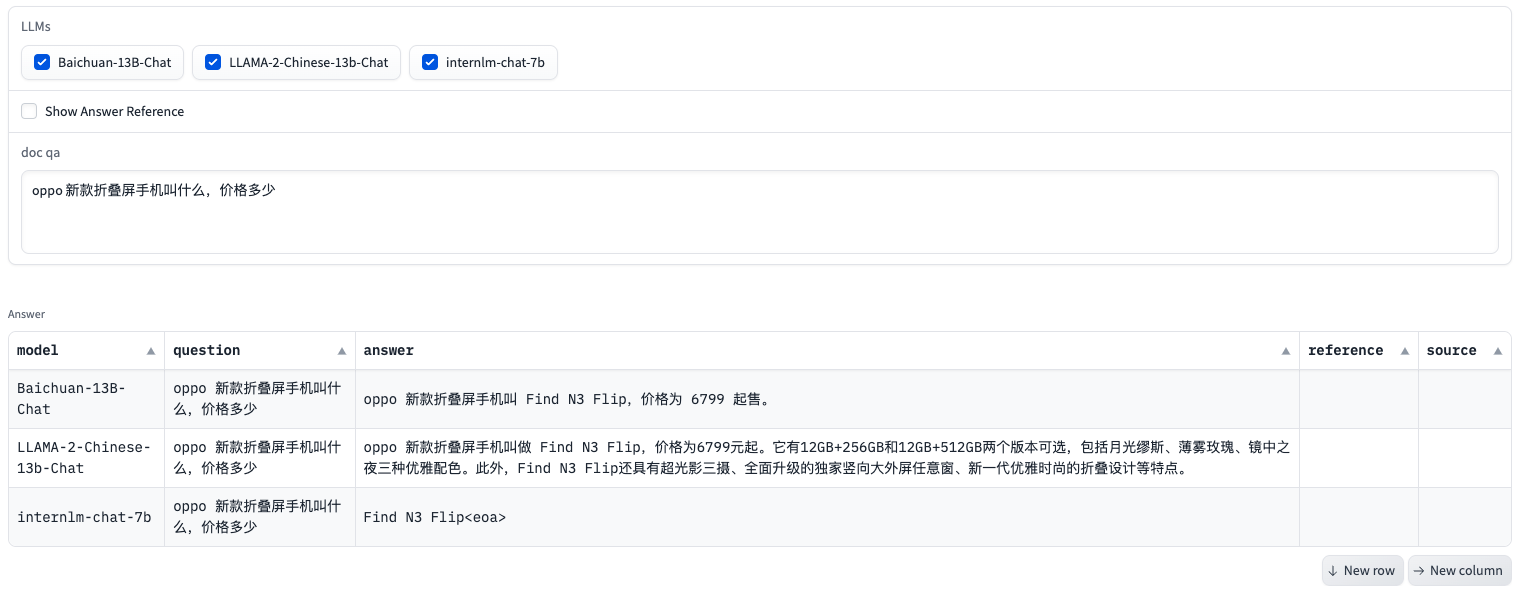
同时,该页面还支持问答溯源,可追踪文档问答得到的答案所需的引用文本和对用的数据来源。
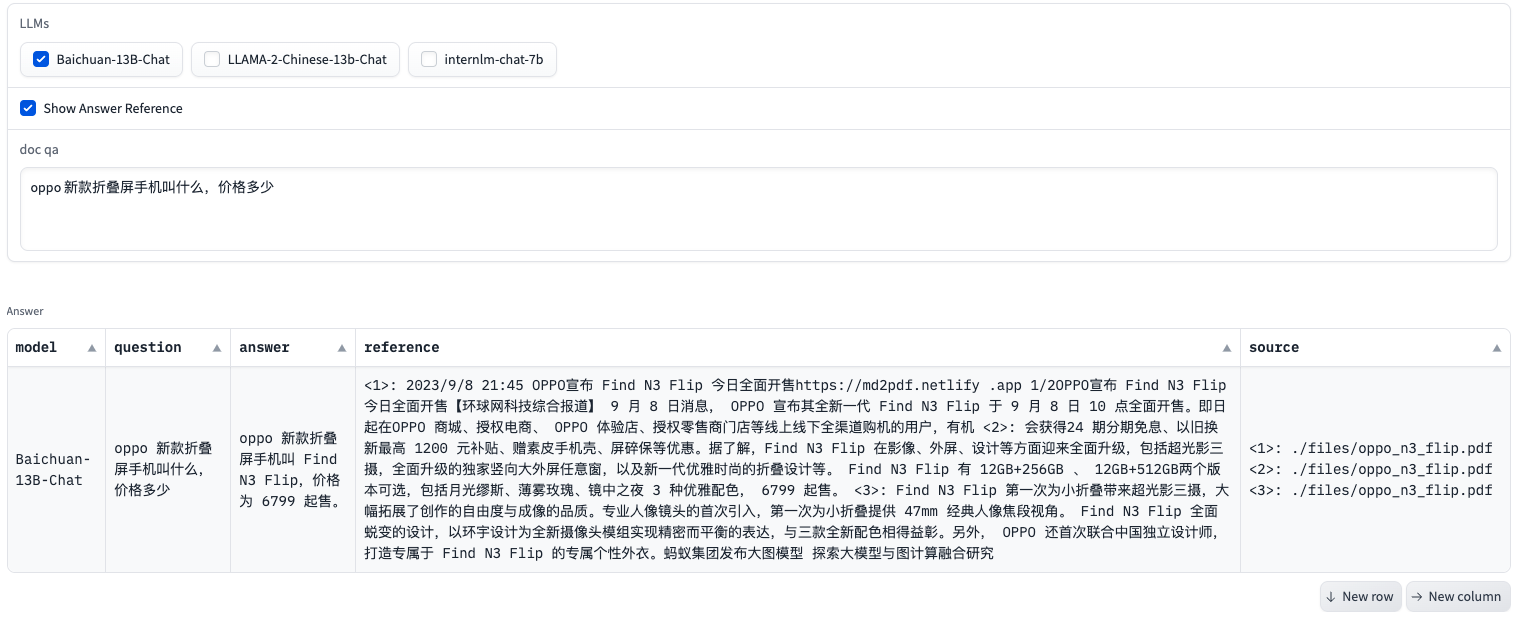
问答溯源中的文本高亮
由于Gradio中的表格不支持单元格内文本高亮,因此,我们所用它自带的高亮文本控件对问答溯源中的引用文本进行文本高亮,方便我们对回答内容在原文中的位置进行确认,避免大模型幻觉问题。
问答溯源中的文本高亮算法如下:
- 找到问答所在的引用文本列表,由ES和Milvus产生
- 对引用文本拆分成列表
- 得到与回答相似度最高的文本,相似度采用Jaccard系数
- 将相似度最高文本中与回答重合的部分,进行高亮显示
总结
本项目在之前开源的基础上,加入了更丰富的功能,包括支持多种格式文档解析和URL解析,支持问答可视化页面,支持单/多模型调用,支持多模型效果对比。
本项目已开源至Github,代码实现可参考document_qa_with_llm 。
推荐阅读
- NLP(六十一)使用Baichuan-13B-Chat模型构建智能文档
- Gradio入门(1)输入输出、表格、文本高亮
欢迎关注我的公众号NLP奇幻之旅,原创技术文章第一时间推送。

欢迎关注我的知识星球“自然语言处理奇幻之旅”,笔者正在努力构建自己的技术社区。

引用链接
[1] 大模型智能文档问答项目: https://github.com/percent4/document_qa_with_llm
[2] OpenCompass: https://opencompass.org.cn/
[3] document_qa_with_llm: https://github.com/percent4/document_qa_with_llm
[4] 文档加载模块: https://python.langchain.com/docs/integrations/document_loaders/
[5] FastChat: https://github.com/lm-sys/FastChat
[6] document_qa_with_llm: https://github.com/percent4/document_qa_with_llm