网站搭建修改收费依据google谷歌搜索引擎
Word2Vec
- CBOW连续词袋模型
- 例子
- CBOW模型的embeddings层
- CBOW模型的线性层
- 总结
- skip-gram跳字模型
- 例子
- Skip-Gram模型的结构
CBOW和skip-gram的目标都是迭代出词向量字典(嵌入矩阵)——embeddings
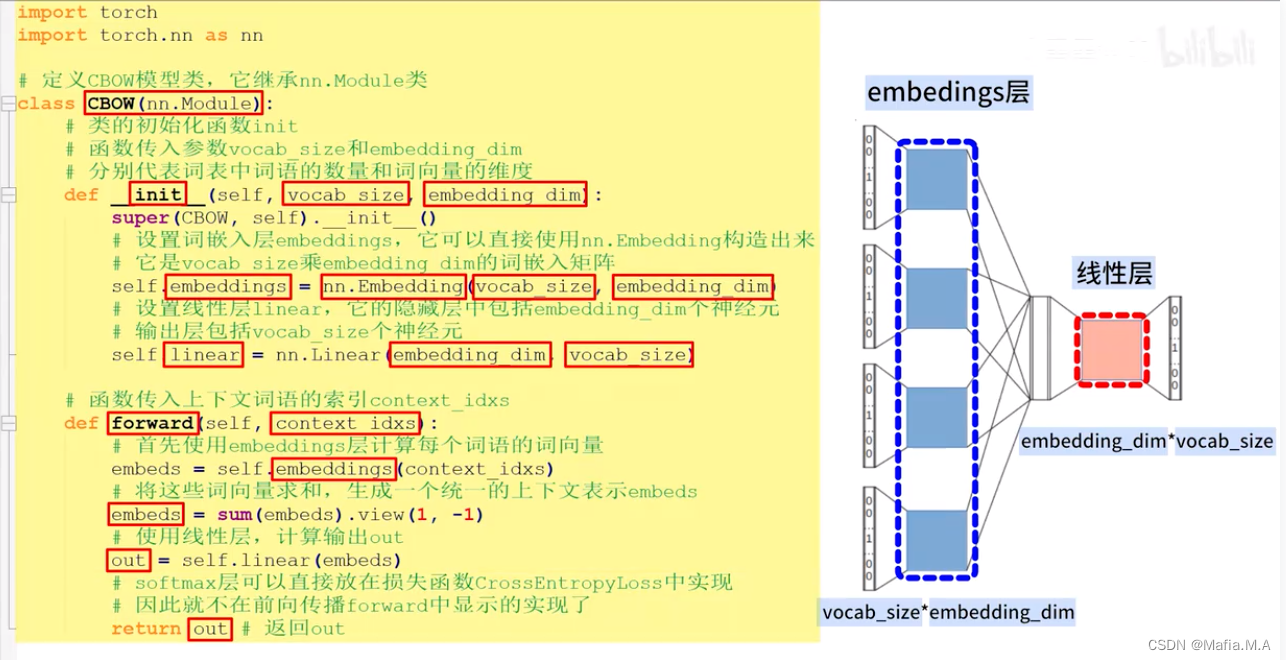
CBOW连续词袋模型
根据上下文词汇预测目标词汇
例子
使用study的上下文,表示出study
例句:We are about to study the idea of deep learning.
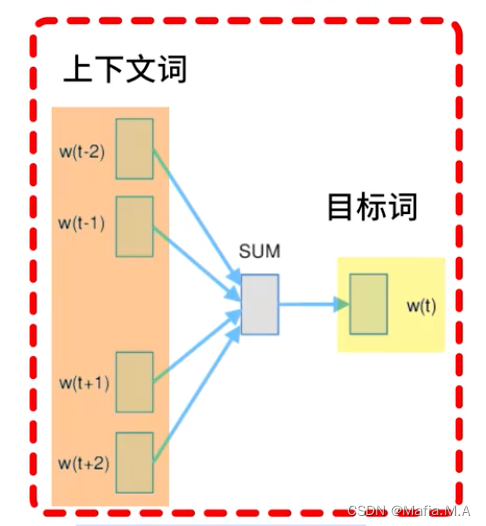
- 某个词的上下文,需要提前设置一个上下文窗口长度
窗口长度为1:We are about to study the idea of deep learning. (上下文分别问to和the)
窗口长度为2:We are about to study the idea of deep learning. (上下文分别为about to 和 the idea)
- 设置好窗口的长度后,需要通过窗口内的词语,预测目标词:
窗口长度为2时,则有如下对应关系:
We、are、to、study -预测> about
are、about、study、the -预测> to
about、to、the、idea -预测> study
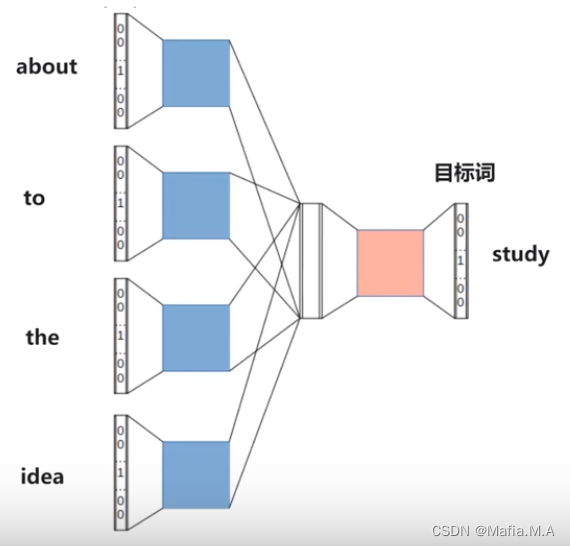
- CBOW模型是一个神经网络:该神经网络会将接收上下文词语,将上下文词语转换为最有可能得到的目标词。
eg.如果向神经网络输入 about、to、the、idea四个词,神经网络则输出study这个词。
CBOW模型的embeddings层
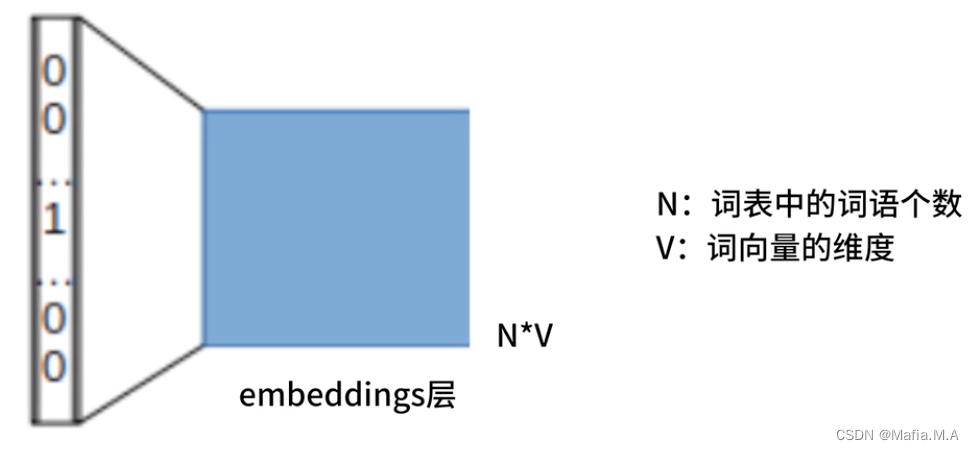
CBOW模型中有一个特殊的层——embeddings层
embeddings层是一个N*V的矩阵
N——词表中的词语个数;
V——词向量的维度
他就是我们最终希望得到的嵌入矩阵
embeddings层的作用是将我们输入的词语转换成词向量
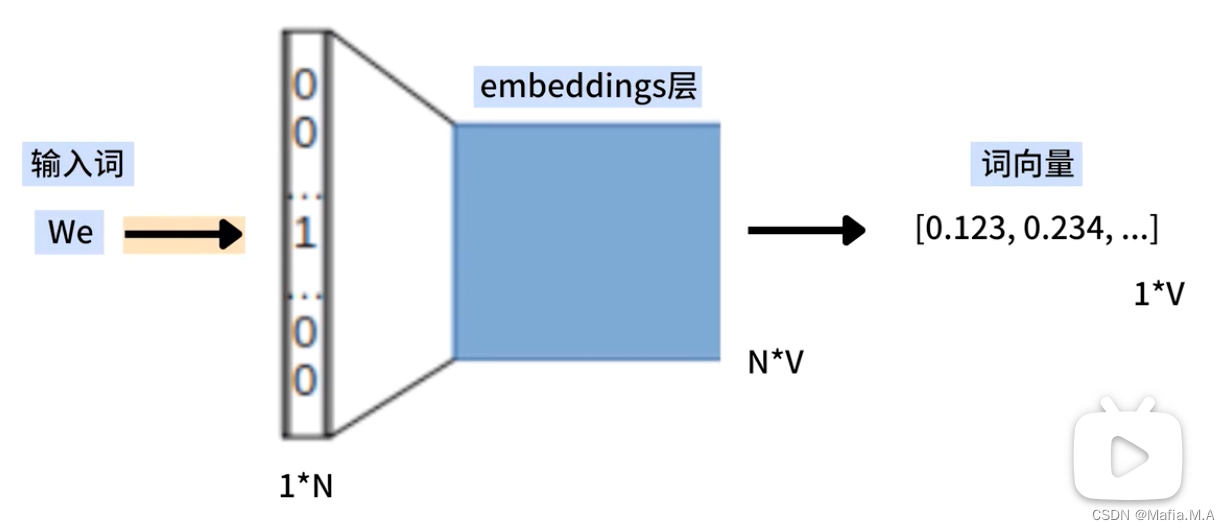
1.将词语we输入至CBOW,将we转换为One-Hot编码形式,是一个1xN的向量,其中只有与We对应的位置是1,其余位置都是0
2.将we的One-Hot编码(1xN的向量)与embeddings(NxV的矩阵)相乘,得到we的词向量(1xV的向量)
相当于从矩阵中选择一个特定的行,从embeddings中查找we的词向量。
由于某个词的上下文中包括了多个词语,这些词语会同时输入embeddings层,每个词语都会被转换为一个词向量。
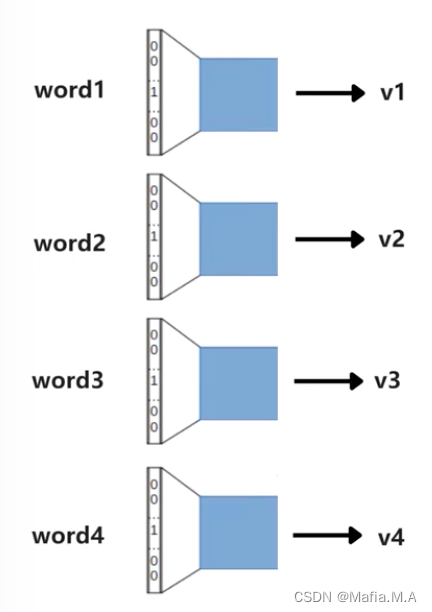
多个上下文词的一个统一表示:v=(v1+v2+v3+v4)/ 4
embeddings层的输出结果:是一个将语义信息平均的向量v
CBOW模型的线性层
在embeddings层后会连接一个线性层
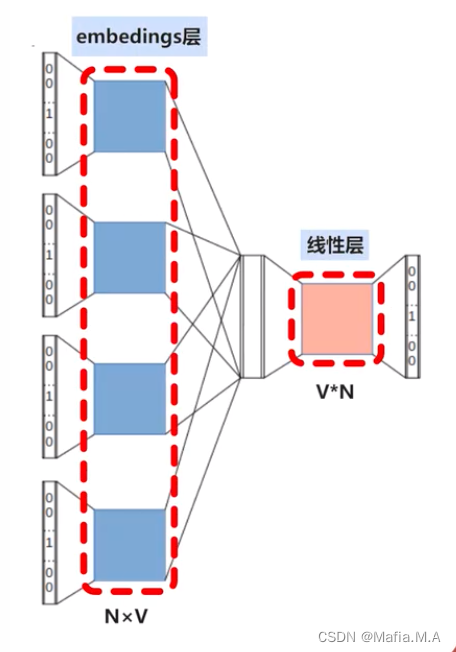
橙色标记的线性层
不设置激活函数
权重矩阵的维度:VxN
词向量维度:V
词表中词语的个数:N
V个隐藏神经元、N个输出神经元的神经网络
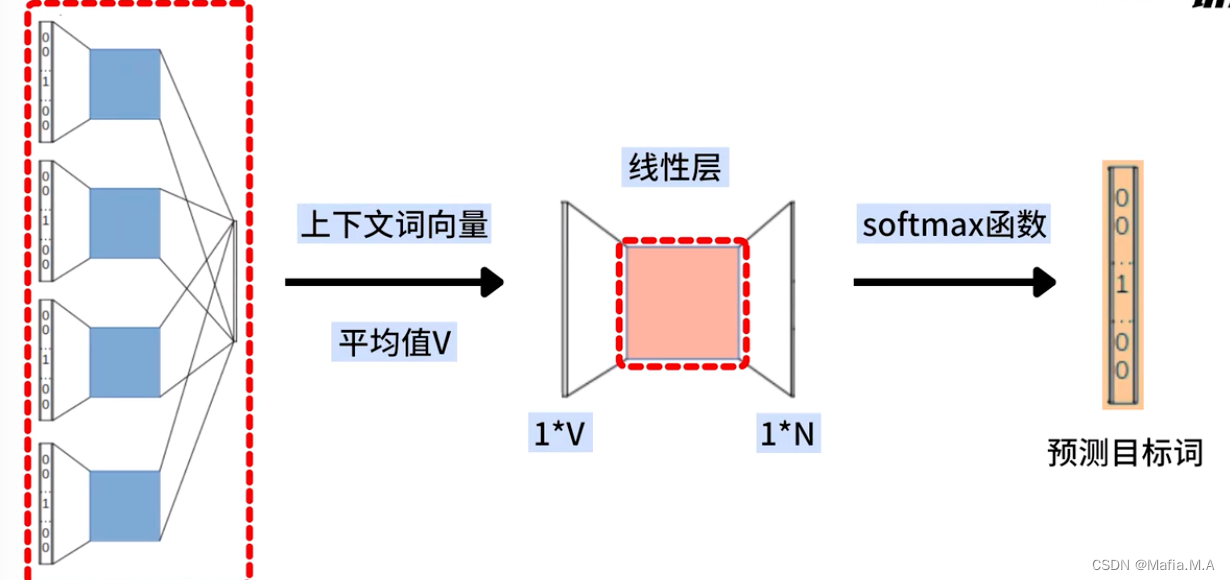
- 我们将所有上下文词向量的平均值(向量V),输入该线性层
- 通过线性层的计算得到一个1xN的向量
- 将1xN的向量再输入至softmax层,最终计算出一个最有可能的输出词,这个词就是CBOW模型的预测目标词
总结
CBOW模型包括两部分:embeddings层和线性层
embeddings层:将输入的上下文词语,都转换为一个上下文词向量,并继续求出这些上下文词向量的平均值(代表整个上下文的向量)
线性层:接收该向量,并将其转换为一个输出向量(输出向量的维度与词汇表的大小相同)
最后使用softmax函数,将输出向量转换为一个概率分布,表示每个词作为目标词的概率,概率最大的词就是CBOW模型的预测结果
skip-gram跳字模型
根据目标词汇预测上下文
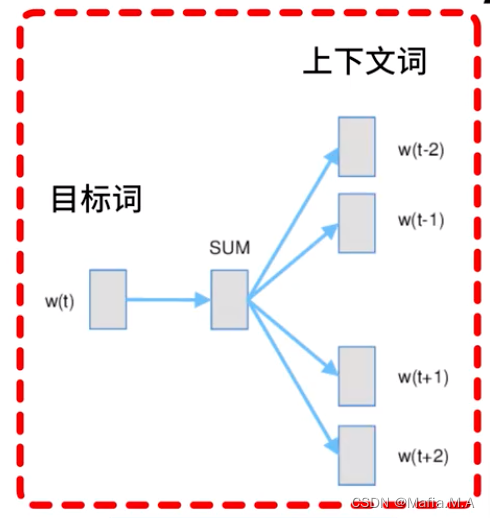
例子
使用词语study,预测出它的上下文
例句:We are about to study the idea of deep learning.
- 某个词的上下文,需要提前设置一个上下文窗口长度
设置窗口长度为2后,根据目标词,预测窗口内的上下文词,study -预测-> about、to、the、idea
如何使用一个词预测另一个词:
使用一个词,预测另一个词,尽量使这两个词的词向量接近
Skip-gram在迭代时,调整词向量:
使目标词的词向量与其上下文的词向量尽可能的接近;
使目标词的词向量与非上下文词的词向量尽可能的远离。
因此我们对于给定的目标词,它与它的上下文的词向量相似,与非上下文词的词向量不相似。
在skip模型中,判断两个词向量是否相似,使用向量点积:
A·B=a1b1+a2b2+…+anbn
A=(a1,a2,…,an)
B=(b1,b2,…,bn)
向量的点积:衡量了两个向量在同一方向上的强度,点积越大——两个向量越相似,它们对应的词语语义就越接近

需要想办法让study与about的词向量的点积尽可能大
Skip-Gram模型的结构
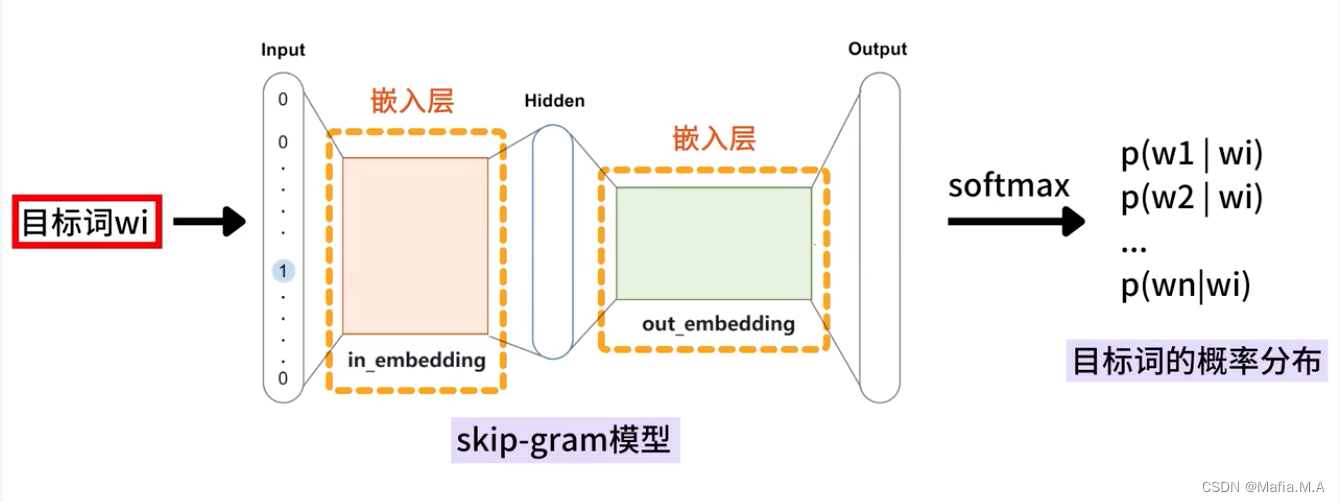
目标词的概率分布——词汇表中的每个词是目标词的上下文的可能性

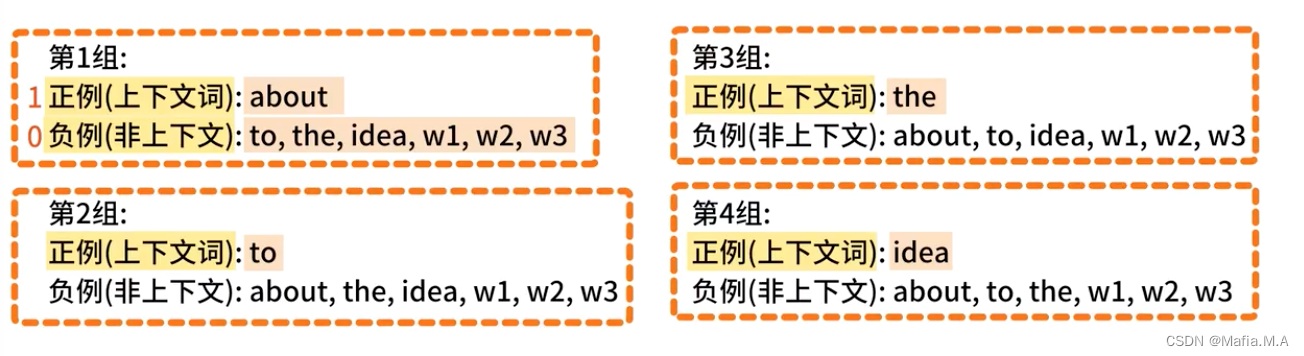
词表中的词,与目标词有两种关系:
- 上下文词——正样本,标记为1
- 非上下文词——负样本,标记为0
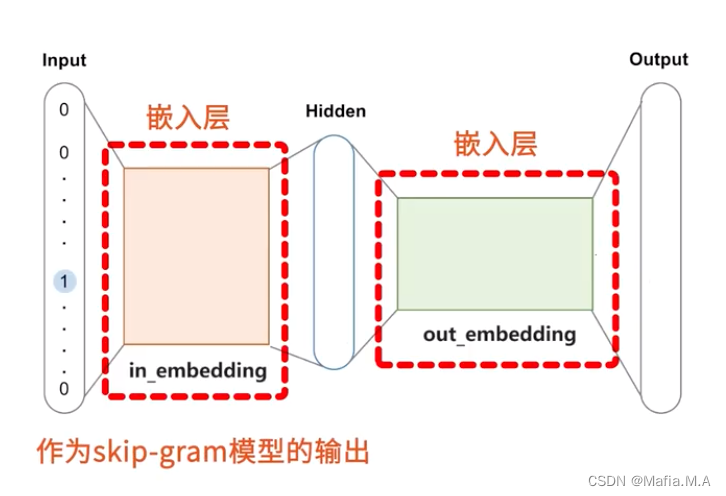
基于这一点来优化模型中两个嵌入层——in_embedding和out_embedding
最后将in_embedding作为skip-gram模型的输出

由此产生的训练数据:有4个上下文词,因此产生4组训练数据