婚恋网站女孩子做美容优帮云排名优化
卡奥斯智能交互引擎是卡奥斯基于海尔近40年工业生产经验积累和卡奥斯7年工业互联网平台建设的最佳实践,基于大语言模型和RAG技术,集合海量工业领域生态资源方优质产品和知识服务,旨在通过智能搜索、连续交互,实时生成个性化的内容和智能化产品推荐,为用户提供快速、可靠的交互式搜索服务,首创了聚焦工业领域的智能交互引擎。
详情戳:卡奥斯智能交互引擎![]() https://datayi.cn/w/DPWgDgjP
https://datayi.cn/w/DPWgDgjP
什么AI应用每秒处理20000个AI推理请求,达到2024年谷歌搜索流量的1/5?
答案是独角兽Character.ai,由Transformer作者Noam Shazeer(后面简称沙哥)创办。
刚刚,沙哥公布了推理优化独门秘诀,迅速引起业界热议。

具体来说Character.ai在整个服务堆栈中实现了如下成绩:
-
内存高效架构设计:将KV缓存大小减少20倍以上,而不会降低质量
-
Attention状态缓存:95%请求无需重算
-
直接用in8精度量化训练:推理零损失还省显存
Character.AI通过以上种种优化,已经把推理成本降低到最初的1/33,如果用市场上最好的商业API来支撑这种级别的流量,成本会比现在高出13.5倍!
众多公布的方法中,原生int8训练是最受关注的。
虽然大多数技巧都来自公开研究,但是正如网友所说,知道如何把它们高效整合在一起实现的团队才是真正的护城河。

秘诀1:高效利用显存,attention 参数量降低20倍
大模型的一大痛点是显存占用高,导致无法支持大批量推理。Attention 层中的 Key-Value(KV)缓存便是罪魁祸首之一。
为了降低显存占用,Character.AI在Attention层大动手术:
-
全面采用MQA(Multi-Query Attention)
与大多数开源模型中采用的GQA(Grouped-Query Attention)相比,将KV缓存大小减少了 8 倍。
而MQA正是沙哥本人2019年在谷歌期间提出的,有网友评价“当一个人能在生产环境中引用自己的论文,就达到了一个新的高度”。

-
混合注意力视野
将局部注意力与全局注意力层交织在一起,使用滑动窗口训练局部注意力,将复杂度从 O(length^2 ) 降低到 O(length)。
团队发现,将大多数注意力层的注意力范围减少到1024不会对评估指标产生重大影响,包括长上下文大海捞针基准。在Character.ai生产模型中,每6层中只有1层使用全局注意力。
-
跨层KV共享
团队将KV缓存绑定在相邻的注意力层上,这进一步将 KV缓存大小减少了 2-3 倍。
对于全局注意力,跨块绑定多个全局层的KV缓存,因为全局注意力层在长上下文用例中主导KV缓存大小,团队发现跨层共享KV不会降低质量。
下图中左半部分是标准Transformer设计,每个注意力都是全局注意力。右半部分为Character.ai的设计,蓝色框表示全局注意力,绿色框表示局部注意力,连线表示KV共享。
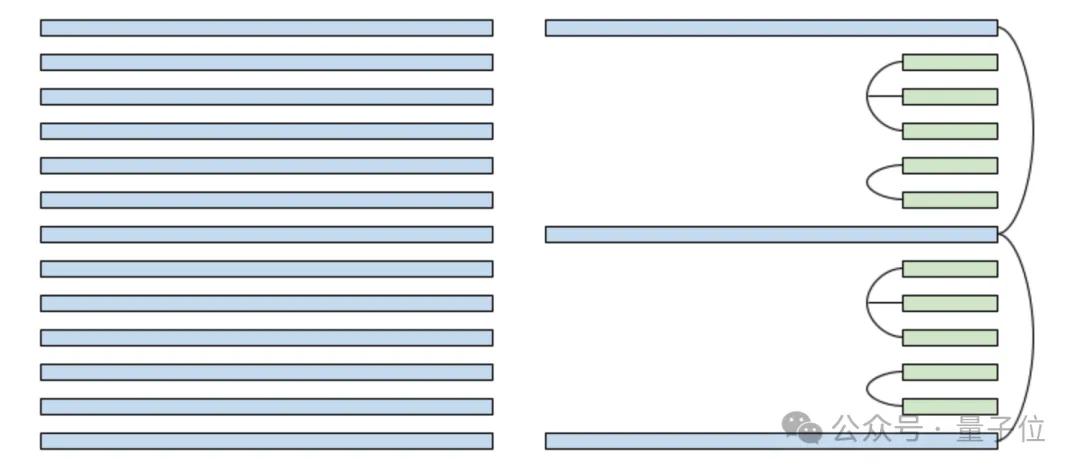
这一套组合拳下来,KV缓存大小减少20倍以上,显存再也不是瓶颈了。
秘诀2:巧用状态缓存,95%请求无需重算
Character.AI还有一招神来之笔,就是在不同对话之间缓存Attention状态。
作为聊天机器人角色扮演服务,Character.AI上大部分对话都是连续多轮的,平均每个对话包含180条消息。如果每次都要重新计算前面的状态,成本可想而知。
于是团队设计了一个缓存机制,把每个对话的Prefix和生成的消息都缓存在内存中,供后续调用。
借鉴RadixAttention的思路,树状结构的LRU缓存组织缓存的KV张量。缓存的KV值由前缀token的Rolling Hash速检索最长匹配的缓存,即使前缀只有部分匹配也能命中。
更妙的是,他们还用会话保持(Sticky Session)把同一对话路由到同一个服务器,进一步提高缓存命中率。最终做到95%的请求都能复用已有缓存,大幅降低了计算成本。
下图中,蓝色框表示主机内存上的缓存张量。绿色和黄色框表示CUDA内存上的KV缓存。当新查询到达时,它检索最长匹配前缀的KV缓存,Rolling Hash系统允许检索部分匹配消息的缓存。
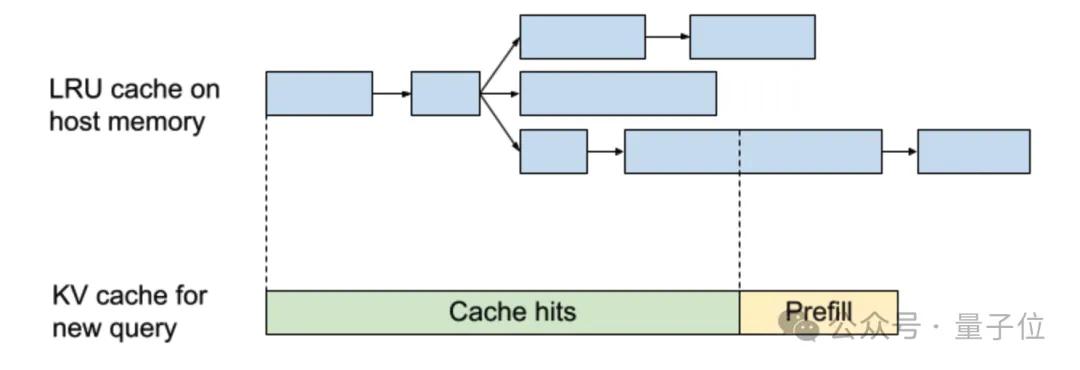
秘诀3:直接量化训练,推理零损失还省显存
最后一招,Character.AI没有采用常见的“训练后量化”,而是直接用Int8精度训练模型。
这种格式虽然表达精度降低,但通过精心设计定制的矩阵乘和 Attention 内核,不仅把训练效率提高了好几倍,而且还能无损用于推理。
不过沙哥在这里暂时留了一手,表示“量化训练本身就是一个复杂的话题,将在以后的文章中继续讨论。”
沙哥其人
最后再来介绍一下传奇人物Noam Shazeer本人。

他1994年拿了信息学奥赛IOI金牌,后来毕业于杜克大学。
2000年加入谷歌,当时全公司只有200人左右,他参与了谷歌搜索的拼写纠正功能,后来也负责过早期广告系统。
据知情人透露,在当初面试谷歌时,沙哥就被问到如何实现拼写纠正。他描述了一种根据其他用户的输入输入记录,进行统计验证的方法。
面试官Gmail之父Paul Buchheit意识到,沙哥的方案比谷歌当时使用的要好。沙哥成功入职之后就把他的面试方案写出来了。
在Transformer开山之作《Attention is All You Need》研究中,沙哥最后一个加入团队,一来就负责重新编写了整个代码。
在沙哥出手之前,Transformer早期原型性能并没有超越当时流行的LSTM方案,是他把早期设计中的卷积等模块都拿掉,给出了一个极简主义方案。最终破了BLEU测试的记录,同时计算效率也更高。
队友用“他是一个巫师”来评价他的工程和代码能力。
除此之外,沙哥还有惊人的远见。在Transformer架构问世不久,他就给谷歌高层写信,提议公司放弃整个搜索索引,并用Transformer架构训练一个巨大的神经网络替代。
2021年,沙哥离开谷歌后创办了Character.AI,让玩家简单自创个性化AI陪聊,目前估值约50亿美元。
最近有消息称,Meta与马斯克的𝕏都在争取与他们合作,把聊天机器人引入社交平台。