做网站难吗 挣钱吗百度电商平台app
原作者地址:
https://github.com/olixu/SJTU_Thesis_Crawler
问题:
http://thesis.lib.sjtu.edu.cn/的学位论文下载系统,该版权保护系统用起来很不方便,加载起来非常慢,所以该下载器实现将网页上的每一页的图片合并成一个PDF。
解决方案
:
使用PyMuPDF对图片进行合并
修改
在使用过程中发现我的mac python3执行有错,需要修改代码。
修改如下
修改fitz没有convertToPDF方法的问题
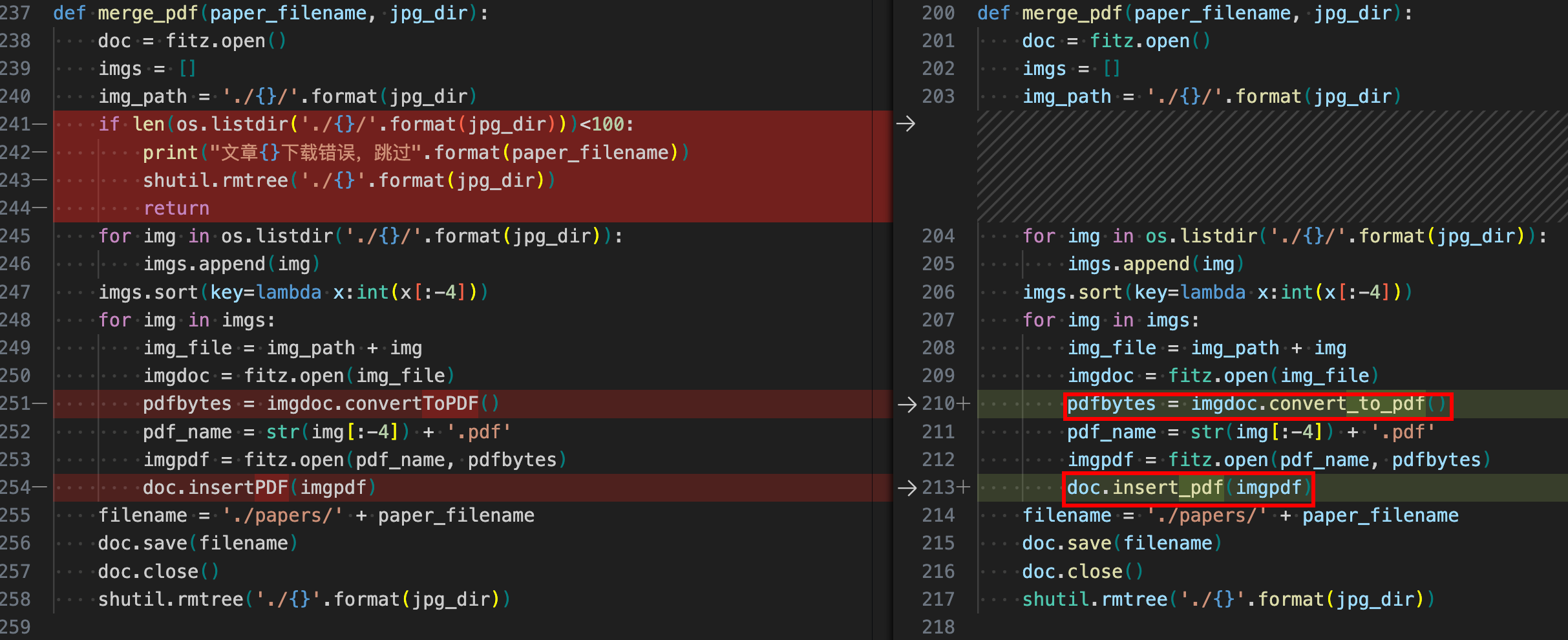
设置超时时间10s,如果超时则break
只下载电院的论文
根据题名来查询

完整代码
# -*- encoding: utf-8 -*-
'''
@File : downloader.py
@Time : 2021/06/27 10:24:10
@Author : olixu
@Version : 1.0
@Contact : 273601727@qq.com
@WebSite : https://blog.oliverxu.cn
'''# here put the import lib
from __future__ import print_function, unicode_literals
import os
import sys
import time
import random
import json
import shutil
from collections import defaultdict
from urllib.parse import quote
import requests
from lxml import etree
import fitz
from PyInquirer import style_from_dict, Token, promptdef main():"""下载学位论文入口程序:调用方式:python downloader.py --pages '1-2' --major '计算机'"""answers = search_arguments()info_url, pages = arguments_extract(answers)papers = download_main_info(info_url, pages)will_download = confirmation(papers)['confirmation']if will_download:paper_download(papers)else:print('Bye!')def paper_download(papers):jpg_dir = time.strftime("%Y-%m-%d-%H-%M-%S", time.localtime()) + "".join(random.sample('zyxwvutsrqponmlkjihgfedcba23429837498234',5))for paper in papers:print(100*'@')paper_filename = paper['year'] + '_' + paper['filename'] + '_' + paper['author'] + '_' + paper['mentor'] + '.pdf'if verify_name(paper_filename):print("论文{}已经存在".format(paper_filename))continueprint("正在下载论文:", paper['filename'])init(jpg_dir=jpg_dir)try:download_jpg(paper['link'], jpg_dir=jpg_dir)merge_pdf(paper_filename, jpg_dir=jpg_dir)except Exception as e:print(e)def search_arguments():style = style_from_dict({Token.Separator: '#cc5454',Token.QuestionMark: '#673ab7 bold',Token.Selected: '#cc5454', # defaultToken.Pointer: '#673ab7 bold',Token.Instruction: '', # defaultToken.Answer: '#f44336 bold',Token.Question: '',})questions = [{'type': 'input','name': 'content','message': '请输入你的检索词'}]answers = prompt(questions, style=style)return answersdef arguments_extract(answers):choose_key = {'主题':'topic', '题名':'title', '关键词':'keyword', '作者':'author', '院系':'department', '专业':'subject', '导师':'teacher', '年份':'year'}xuewei = {'硕士及博士':'0', '博士':'1', '硕士':'2'}px = {'按题名字顺序排序':'1', '按学位年度倒排序':'2'}info_url = "http://thesis.lib.sjtu.edu.cn/sub.asp?content={}&choose_key={}&xuewei={}&px={}&page=".format(quote(answers['content']), \'title', \'2', \'1')print(info_url)pages = [1, 1]return info_url, pagesdef confirmation(papers):print("\033[\033[1;32m 检索到了以下{}篇文章\033[0m".format(len(papers)))for i in papers:print('\033[1;31m 题目\033[0m', i['filename'], '\033[1;34m 作者\033[0m', i['author'], '\033[1;36m 导师\033[0m', i['mentor'], '\033[1;35m 年份\033[0m', i['year'])# 这里需要格式化输出对其一下questions = [{'type': 'confirm','message': "确认下载{}篇文章吗?".format(len(papers)),'name': 'confirmation','default': 'True'}]answers = prompt(questions)return answersdef verify_name(paper_filename):if not os.path.exists('./papers'):os.mkdir('./papers')if paper_filename in os.listdir('./papers'):return Truereturn Falsedef init(jpg_dir):"""初始化文件夹路径"""try:shutil.rmtree('./{}/'.format(jpg_dir))print("删除本地{}文件夹".format(jpg_dir))except Exception as e:print(e)try:os.mkdir('./{}/'.format(jpg_dir))print("新建本地{}文件夹".format(jpg_dir))except Exception as e:print(e)def download_main_info(info_url: str, pages: list):papers = []info_url = info_urlheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'}result = requests.Session()for page in range(pages[0], pages[1]+1):print("正在抓取第{}页的info".format(page))info_url_construction = info_url + str(page)response = result.get(info_url_construction, headers=headers, allow_redirects=False)html = etree.HTML(response.content, etree.HTMLParser())for i in range(2, 22):# 有些是论文保密,所以link需要错误处理info_dict = defaultdict(str)try:# deparment = html.xpath('/html/body/section/div/div[3]/div[2]/table/tr[{}]/td[4]/text()'.format(i))[0]# if deparment != '(030)电子信息与电气工程学院':# continuefilename = html.xpath('/html/body/section/div/div[3]/div[2]/table/tr[{}]//td[2]/text()'.format(i))[0]author = html.xpath('/html/body/section/div/div[3]/div[2]/table/tr[{}]/td[3]/div/text()'.format(i))[0]mentor = html.xpath('/html/body/section/div/div[3]/div[2]/table/tr[{}]/td[6]/div/text()'.format(i))[0]year = html.xpath('/html/body/section/div/div[3]/div[2]/table/tr[{}]/td[8]/div/text()'.format(i))[0]link = "http://thesis.lib.sjtu.edu.cn/" + html.xpath('/html/body/section/div/div[3]/div[2]/table/tr[{}]/td[9]/div/a[2]/@href'.format(i))[0]info_dict['filename'] = filenameinfo_dict['author'] = authorinfo_dict['mentor'] = mentorinfo_dict['year'] = yearinfo_dict['link'] = linkpapers.append(info_dict)except Exception as e:# print(e)passprint("总共抓取到{}个元数据信息".format(len(papers)))return papersdef download_jpg(url: str, jpg_dir: str):"""下载论文链接为jpg:param url: 阅读全文链接"""url = urlheaders = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36'}result = requests.Session()print("开始获取图片地址")response = result.get(url, headers=headers, allow_redirects=False)url = response.headers['Location']response = result.get(url, headers=headers, allow_redirects=False)url = response.headers['Location']response = result.get(url, headers=headers, allow_redirects=False)url_bix = response.headers['Location'].split('?')[1]url = "http://thesis.lib.sjtu.edu.cn:8443/read/jumpServlet?page=1&" + url_bixresponse = result.get(url, headers=headers, allow_redirects=False)urls = json.loads(response.content.decode())print("已经获取到图片地址")i = 1while(True):try:fig_url = "http://thesis.lib.sjtu.edu.cn:8443/read/" + urls['list'][0]['src'].split('_')[0] + "_{0:05d}".format(i) + ".jpg"response = result.get(fig_url, headers=headers, timeout=10).contentif len(response) < 2000:breakwith open('./{}/{}.jpg'.format(jpg_dir, i), 'wb') as f:f.write(response)i = i + 1print("正在采集第{}页".format(i))except requests.exceptions.Timeout:print("请求超时,退出循环")breakdef merge_pdf(paper_filename, jpg_dir):doc = fitz.open()imgs = []img_path = './{}/'.format(jpg_dir)for img in os.listdir('./{}/'.format(jpg_dir)):imgs.append(img)imgs.sort(key=lambda x:int(x[:-4]))for img in imgs:img_file = img_path + imgimgdoc = fitz.open(img_file)pdfbytes = imgdoc.convert_to_pdf()pdf_name = str(img[:-4]) + '.pdf'imgpdf = fitz.open(pdf_name, pdfbytes)doc.insert_pdf(imgpdf)filename = './papers/' + paper_filenamedoc.save(filename)doc.close()shutil.rmtree('./{}'.format(jpg_dir))if __name__=='__main__':main()