业余从事网站开发免费建站系统哪个好用吗
ZooKeeper应用的开发主要通过Java客户端API去连接和操作ZooKeeper集群。可供选择的Java客户端API有:
- ZooKeeper官方的Java客户端API。
- 第三方的Java客户端API,比如Curator。
接下来我们将逐一学习一下这两个java客户端是如何操作zookeeper的。
1. ZooKeeper官方的Java客户端
1.1 简介
ZooKeeper官方的客户端API提供了基本的操作。例如,创建会话、创建节点、读取节点、更新数据、删除节点和检查节点是否存在等。不过,对于实际开发来说,ZooKeeper官方API有一些不足之处,具体如下:
- ZooKeeper的Watcher监听是一次性的,每次触发之后都需要重新进行注册。
- 会话超时之后没有实现重连机制。
- 异常处理烦琐,ZooKeeper提供了很多异常,对于开发人员来说可能根本不知道应该如何处理这些抛出的异常。
- 仅提供了简单的byte[]数组类型的接口,没有提供Java POJO级别的序列化数据处理接口。
- 创建节点时如果抛出异常,需要自行检查节点是否存在。
- 无法实现级联删除。
总之,ZooKeeper官方API功能比较简单,在实际开发过程中比较笨重,一般不推荐使用。
1.2 基础使用
使用zookeeper原生客户端,需要引入zookeeper客户端的依赖。
<dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.8.3</version></dependency>注意:保持与服务端版本一致,不然会有很多兼容性的问题。
ZooKeeper原生客户端主要使用org.apache.zookeeper.ZooKeeper这个类来调用ZooKeeper服务的。
1.2.1 连接zk集群
ZooKeeper构造器:
public ZooKeeper(String connectString, int sessionTimeout, Watcher watcher) throws IOException {this(connectString, sessionTimeout, watcher, false);}connectString:使用逗号分隔的列表,每个ZooKeeper节点是一个host.port对,host 是机器名或者IP地址,port是ZooKeeper节点对客户端提供服务的端口号。客户端会任意选取connectString 中的一个节点建立连接。
sessionTimeout : session timeout时间。
watcher:用于接收到来自ZooKeeper集群的事件。
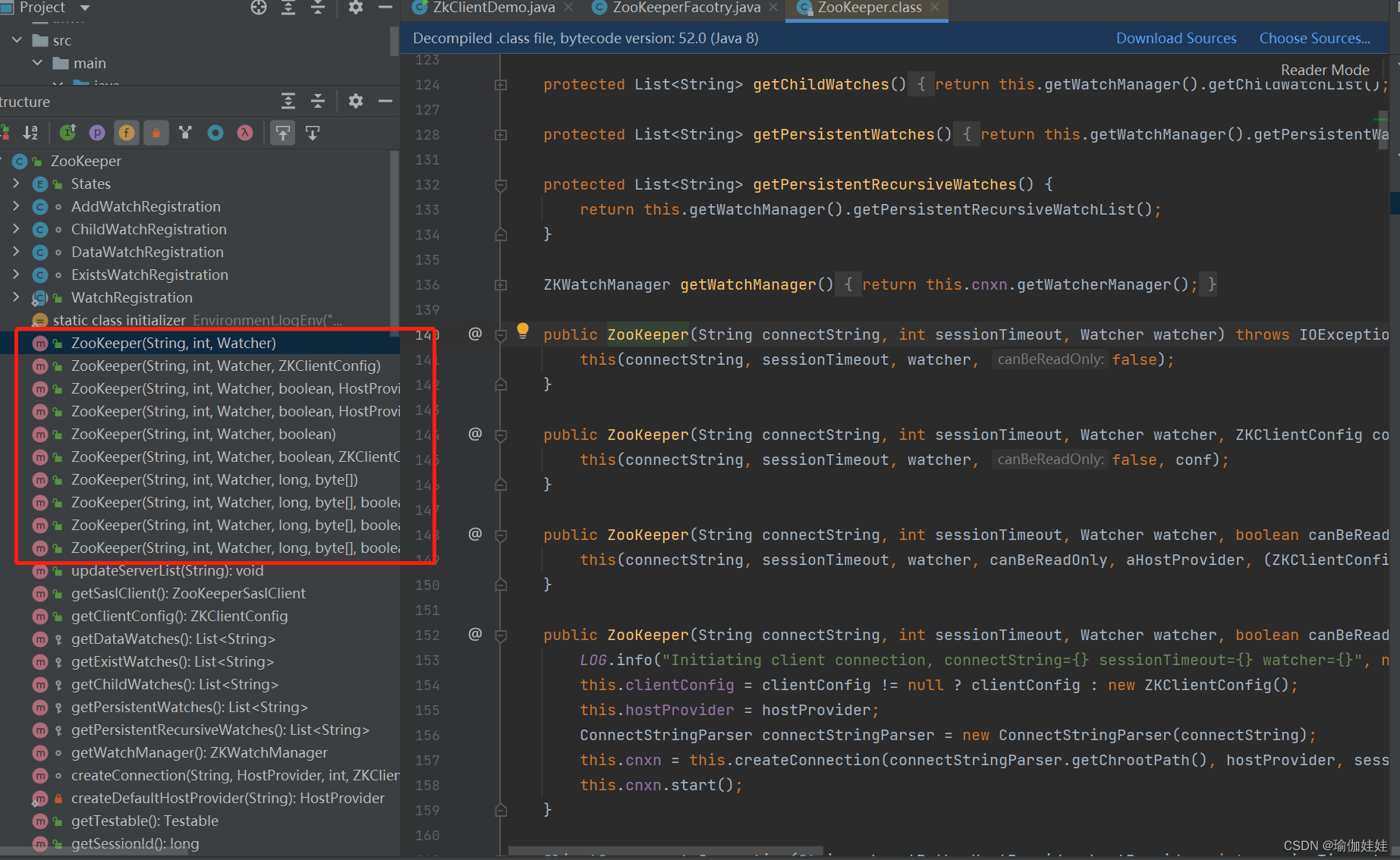
如何使用客户端构造器与服务端建立连接:
建立连接的工具类;因为zookepper建立连接时特别慢,所以采用了CountDownLatch同步工具类,等待zookeeper客户端与服务端建立完成后,继续后续操作。
public class ZooKeeperFacotry {private static final int SESSION_TIMEOUT = 5000;public static ZooKeeper create(String connectionString) throws Exception {final CountDownLatch connectionLatch = new CountDownLatch(1);ZooKeeper zooKeeper = new ZooKeeper(connectionString, SESSION_TIMEOUT, new Watcher() {@Overridepublic void process(WatchedEvent event) {if (event.getType()== Event.EventType.None&& event.getState() == Watcher.Event.KeeperState.SyncConnected) {connectionLatch.countDown();System.out.println("连接建立");}}});System.out.println("等待连接建立...");connectionLatch.await();return zooKeeper;}}public class ZkClientDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//创建zookeeper对象ZooKeeper zooKeeper = ZooKeeperFacotry.create(CLUSTER_CONNECT_STR);//连接System.out.println(zooKeeper.getState()); }运行结果:

1.2.2 操作节点
以下是Zookeeper原生客户端操作服务端的一些主要API:
- create(path, data, acl,createMode): 创建一个给定路径的 znode,并在 znode 保存 data[]的 数据,createMode指定 znode 的类型。
- delete(path, version):如果给定 path 上的 znode 的版本和给定的 version 匹配, 删除 znode。
- exists(path, watch):判断给定 path 上的 znode 是否存在,并在 znode 设置一个 watch。
- getData(path, watch):返回给定 path 上的 znode 数据,并在 znode 设置一个 watch。
- setData(path, data, version):如果给定 path 上的 znode 的版本和给定的 version 匹配,设置znode 数据。
- getChildren(path, watch):返回给定 path 上的 znode 的孩子 znode 名字,并在 znode 设置一个 watch。
- sync(path):把客户端 session 连接节点和 leader 节点进行同步。
API特点:
- 所有获取 znode 数据的 API 都可以设置一个 watch 用来监控 znode 的变化。
- 所有更新 znode 数据的 API 都有两个版本: 无条件更新版本和条件更新版本。如果 version 为 -1,更新为无条件更新。否则只有给定的 version 和 znode 当前的 version 一样,才会进行更新,这样的更新是条件更新。
- 所有的方法都有同步和异步两个版本。同步版本的方法发送请求给 ZooKeeper 并等待服务器的响 应。异步版本把请求放入客户端的请求队列,然后马上返回。异步版本通过 callback 来接受来 自服务端的响应。
接下来,我们利用这些API对zk的节点进行简单的操作
1.2.2.1 创建持久节点
代码:
public class ZkClientDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//创建zookeeper对象ZooKeeper zooKeeper = ZooKeeperFacotry.create(CLUSTER_CONNECT_STR);//连接System.out.println(zooKeeper.getState());Stat stat = zooKeeper.exists("/order",false);if(null ==stat){//创建持久节点zooKeeper.create("/order","001".getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);}System.out.println("执行完了");
}运行的结果:

我们在服务器的客户端查看一下数据:

有数据,创建成功了。
1.2.2.2 永久监听节点
代码:
public class ZkClientDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//创建zookeeper对象ZooKeeper zooKeeper = ZooKeeperFacotry.create(CLUSTER_CONNECT_STR);//连接System.out.println(zooKeeper.getState());Stat stat = zooKeeper.exists("/order",false);//永久监听 addWatch -m modezooKeeper.addWatch("/order",new Watcher() {@Overridepublic void process(WatchedEvent event) {System.out.println(event);//TODO}},AddWatchMode.PERSISTENT);Thread.sleep(Integer.MAX_VALUE);
}启动程序后,在服务器的客户端修改监听的节点。
 程序监听到 /order这个节点被修改了。
程序监听到 /order这个节点被修改了。

1.2.2.3 根据版本更新
代码:
public class ZkClientDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//创建zookeeper对象ZooKeeper zooKeeper = ZooKeeperFacotry.create(CLUSTER_CONNECT_STR);//连接System.out.println(zooKeeper.getState());Stat stat = zooKeeper.exists("/order",false);stat = new Stat();byte[] data = zooKeeper.getData("/order", false, stat);System.out.println(" data: "+new String(data));// -1: 无条件更新//zooKeeper.setData("/user", "third".getBytes(), -1);// 带版本条件更新int version = stat.getVersion();zooKeeper.setData("/order", "updateByVersion".getBytes(), version);Thread.sleep(Integer.MAX_VALUE);}}第一次打印的数据结果:

待程序执行完,在服务器客户端查询的结果:更具版本更新数据成功了。

对于zookeeper java原生客户端的使用,就简单介绍这么多,不在过多赘述,只是为了是让大家感受一下,原生客户端的使用。实际开发中并不推荐使用zk的原生客户端,过于笨重。
2. 开源的第三方客户端:Curator
2.1 简介
官网:https://curator.apache.org/
Curator是Netflix公司开源的一套ZooKeeper客户端框架,和ZkClient一样它解决了非常底层的细节开发工作,包括连接、重连、反复注册Watcher的问题以及NodeExistsException异常等。
Curator是Apache基金会的顶级项目之一,Curator具有更加完善的文档,另外还提供了一套易用性和可读性更强的Fluent风格的客户端API框架。
Curator还为ZooKeeper客户端框架提供了一些比较普遍的、开箱即用的、分布式开发用的解决方案,例如Recipe、共享锁服务、Master选举机制和分布式计算器等,帮助开发者避免了“重复造轮子”的无效开发工作。
在实际的开发场景中,使用Curator客户端就足以应付日常的ZooKeeper集群操作的需求。
2.2 基础使用
使用Curator我们需要引入依赖,官网上介绍到,Curator有多个 artifacts,使用者根据自己的需求,进行引入依赖。对于大多数使用者来说,引入curator-recipes就足够了。
Curator的几个重要包介绍:
curator-framework:是对ZooKeeper的底层API的一些封装。
curator-client:提供了一些客户端的操作,例如重试策略等。
curator-recipes:封装了一些高级特性,如:Cache事件监听、选举、分布式锁、分布式计数器、分布式Barrier等。

依赖: 以防Curator中的zookeeper版本和我们的服务端不匹配,我们需要排除Curator中的zookeeper的客户端,自己手动引入合适版本的zk的客户端。
<!-- zookeeper client --><dependency><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId><version>3.8.3</version></dependency><!--curator--><dependency><groupId>org.apache.curator</groupId><artifactId>curator-recipes</artifactId><version>5.1.0</version><exclusions><exclusion><groupId>org.apache.zookeeper</groupId><artifactId>zookeeper</artifactId></exclusion></exclusions></dependency>
2.2.1 连接zk集群
连接zk集群,我们需要创建一个客户端示例,然后启动客户端。创建客户端实例的方法有两种。
方法一:使用工厂类CuratorFrameworkFactory的静态newClient()方法。
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {// 重试策略RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 3);//创建客户端实例CuratorFramework client = CuratorFrameworkFactory.newClient(CLUSTER_CONNECT_STR, retryPolicy);//启动客户端client.start();Thread.sleep(Integer.MAX_VALUE);} }

方法二:使用工厂类CuratorFrameworkFactory的静态builder构造者方法。
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();Thread.sleep(Integer.MAX_VALUE);} }

参数解释:
connectionString:服务器地址列表,在指定服务器地址列表的时候可以是一个地址,也可以是多个地址。如果是多个地址,那么每个服务器地址列表用逗号分隔, 如 host1:port1,host2:port2,host3;port3 。
retryPolicy:重试策略,当客户端异常退出或者与服务端失去连接的时候,可以通过设置客户端重新连接ZooKeeper 服务端。而 Curator 提供了 一次重试、多次重试等不同种类的实现方式。在 Curator 内部,可以通过判断服务器返回的 keeperException 的状态代码来判断是否进行重试处理,如果返回的是 OK 表示一切操作都没有问题,而 SYSTEMERROR 表示系统或服务端错误。
超时时间:Curator 客户端创建过程中,有两个超时时间的设置。一个是 sessionTimeoutMs 会话超时时间,用来设置该条会话在 ZooKeeper 服务端的失效时间。另一个是 connectionTimeoutMs 客户端创建会话的超时时间,用来限制客户端发起一个会话连接到接收 ZooKeeper 服务端应答的时间。sessionTimeoutMs 作用在服务端,而 connectionTimeoutMs 作用在客户端。

2.2.2 节点操作
描述一个节点要包括节点的类型,即临时节点还是持久节点、节点的数据信息、节点是否是有序节点等属性和性质。接下来,我们逐一看一下利用Curator如何操作一个节点的。
2.2.2.1 创建节点
那么如何用Curator来创建一个节点呢?
在 Curator 中,可以使用 create 函数创建数据节点,并通过 withMode 函数指定节点类型(持久化节点,临时节点,顺序节点,临时顺序节点,持久化顺序节点等),默认是持久化节点,之后调用forPath 函数来指定节点的路径和数据信息。
第一步: 我们在服务器客户端,查看一下当前服务端有哪些节点

第二步:利用Curator创建一个持久节点,运行下述代码
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();String path = "/users/user";// 检查节点是否存在Stat stat = curatorFramework.checkExists().forPath(path);if (stat != null) {// 删除节点curatorFramework.delete().deletingChildrenIfNeeded() // 如果存在子节点,则删除所有子节点.forPath(path); // 删除指定节点}// 创建节点curatorFramework.create().creatingParentsIfNeeded() // 如果父节点不存在,则创建父节点.withMode(CreateMode.PERSISTENT).forPath(path, "user".getBytes());Thread.sleep(Integer.MAX_VALUE);} }
第三步: 我们再次在服务器的客户端查看一下,节点创建成功了没有
创建了users和其子节点user成功。

如果我们需要创建有序节点,临时节点则只需要改变代码中的withMode的参数。具体参数如下:
PERSISTENT:持久节点
PERSISTENT_SEQUENTIAL:持久有序节点
EPHEMERAL:临时节点
EPHEMERAL_SEQUENTIAL:临时有序节点
CONTAINER:容器节点
PERSISTENT_WITH_TTL:持久TTL节点
PERSISTENT_SEQUENTIAL_WITH_TTL:持久有序TTL节点

2.2.2.2 更新节点
那么我们如何更新一个节点呢?
我们通过客户端实例的 setData() 方法更新 ZooKeeper 服务上的数据节点,在setData 方法的后边,通过 forPath 函数来指定更新的数据节点路径以及要更新的数据。
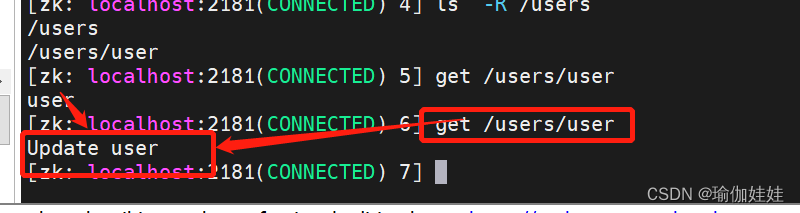
第一步:服务器端的客户端查看节点/users/user原始数据:

第二步:更改/users/user节点的数据,执行以下代码
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();String path = "/users/user";// 更新节点数据 set //users/user Update usercuratorFramework.setData().forPath(path, "Update user".getBytes());Thread.sleep(Integer.MAX_VALUE);} }
第三步:再次使用服务器端的客户端查看/users/user的数据有没有更新成功
更新成功了。
2.2.2.3 查看节点
那么我们如何查看一个节点呢?
我们通过客户端实例的 getData() 方法更新 ZooKeeper 服务上的数据节点,在getData 方法的后边,通过 forPath 函数来指定查看的节点路径。
第一步: 服务器端的客户端查看/users/user的节点数据

第二步:执行以下代码,在java客户端,查看/users/user的数据
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();String path = "/users/user";byte[] bytes = curatorFramework.getData().forPath(path);System.out.println("get data from node :{/users/user} successfully."+new String(bytes));Thread.sleep(Integer.MAX_VALUE);} }执行结果:

2.2.2.4 删除节点
那么我们如何删除一个节点呢?
我们通过客户端实例的 delete() 方法删除 ZooKeeper 服务上的数据节点,在delete方法的后边,通过 forPath 函数来指定删除的节点路径。
第一步:服务器端查看节点

第二步:执行以下代码 删除users节点
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();String path = "/users";//删除节点curatorFramework.delete().guaranteed().deletingChildrenIfNeeded().forPath(path);Thread.sleep(Integer.MAX_VALUE);} }
第三步:服务器端客户端查看节点是否还存在:users和其子节点user都被删除了

删除中一些函数含义:
guaranteed:该函数的功能如字面意思一样,主要起到一个保障删除成功的作用,其底层工作方式是:只要该客户端的会话有效,就会在后台持续发起删除请求,直到该数据节点在ZooKeeper 服务端被删除。
deletingChildrenIfNeeded:指定了该函数后,系统在删除该数据节点的时候会以递归的方式直接删除其子节点,以及子节点的子节点。
2.2.2.4 监听
Curator Caches:Curator 引入了 Cache 来实现对 Zookeeper 服务端事件监听,Cache 事件监听可以理解为一个本地缓存视图与远程 Zookeeper 视图的对比过程。Cache 提供了反复注册的功能。Cache 分为两类注册类型:节点监听和子节点监听。
2.2.2.4.1 监听节点数据变化
第一步: 服务器端客户端查看数据

第二步: 启动以下代码,监听/user节点数据
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();String path = "/users";// 创建节点缓存,用于监听指定节点的变化final NodeCache nodeCache = new NodeCache(curatorFramework, path);// 启动NodeCache并立即从服务端获取最新数据nodeCache.start(true);// 注册节点变化监听器nodeCache.getListenable().addListener(new NodeCacheListener() {@Overridepublic void nodeChanged() throws Exception {byte[] newData = nodeCache.getCurrentData().getData();System.out.println("Node data changed: " + new String(newData));}});Thread.sleep(Integer.MAX_VALUE);} }
第三步:服务器端的客户端更新/users节点的数据,更改了4次

第四步:查看java客户端 监听到了数据

2.2.2.4.2 监听一级子节点
第一步服务器端客户端查看节点数据:

第二步: 执行以下代码,监听节点:
注意:PathChildrenCache 会对子节点进行监听,但是不会对二级子节点进行监听
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();String path = "/users";// 创建PathChildrenCachePathChildrenCache pathChildrenCache = new PathChildrenCache(curatorFramework, path, true);pathChildrenCache.start();// 注册子节点变化监听器pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() {@Overridepublic void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception {if (event.getType() == PathChildrenCacheEvent.Type.CHILD_ADDED) {ChildData childData = event.getData();System.out.println("Child added: " + childData.getPath());} else if (event.getType() == PathChildrenCacheEvent.Type.CHILD_REMOVED) {ChildData childData = event.getData();System.out.println("Child removed: " + childData.getPath());} else if (event.getType() == PathChildrenCacheEvent.Type.CHILD_UPDATED) {ChildData childData = event.getData();System.out.println("Child updated: " + childData.getPath());}}});Thread.sleep(Integer.MAX_VALUE);} }
第三步:服务器端客户端增加子节点、修改子节点、删除子节点

第四步:查看java客户端控制台消息,监听到了对应修改

2.2.2.4.3 监听所有子节点
第一步:服务器端客户端查看节点:

第二步:执行以下代码,进行监听
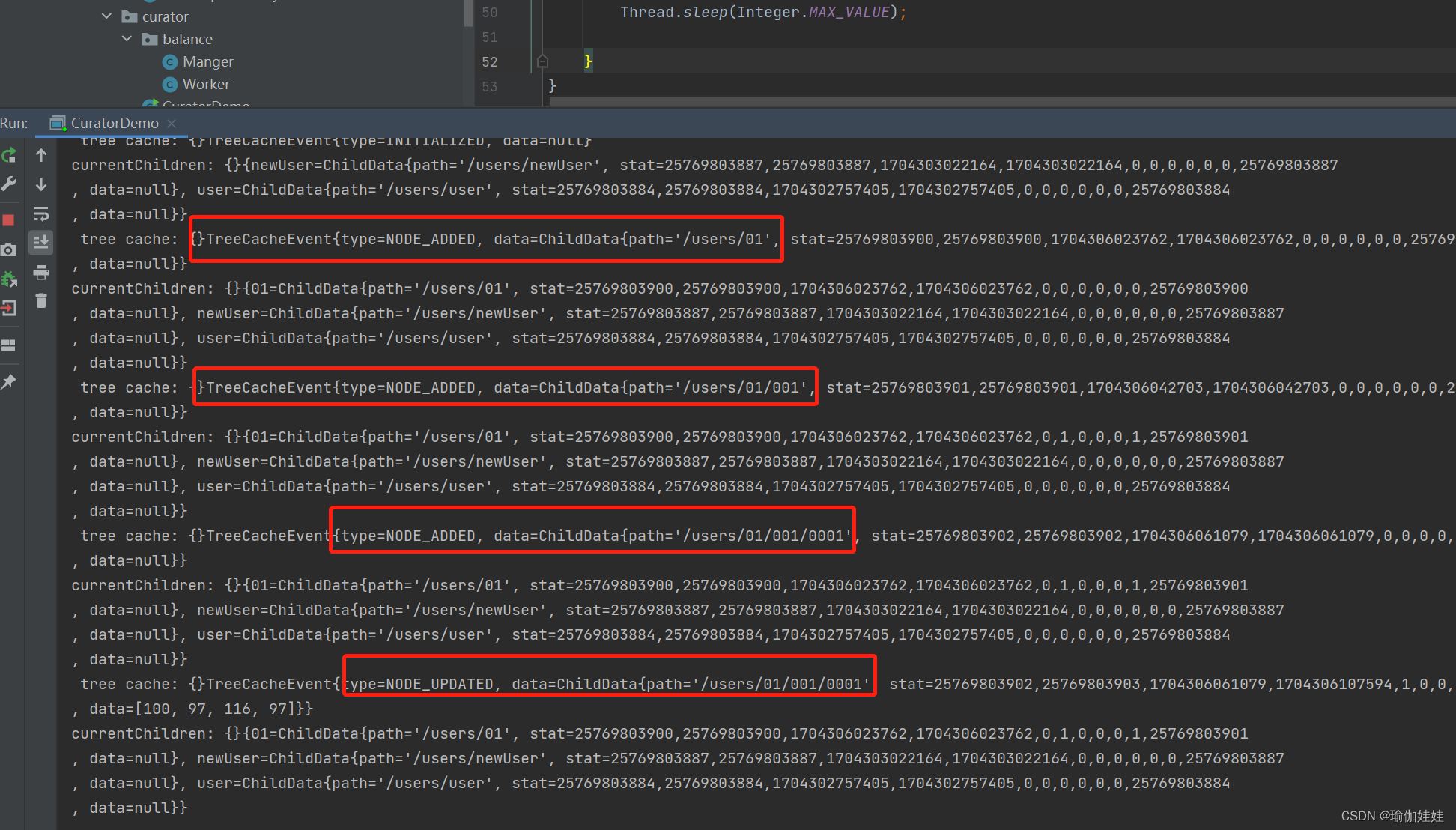
public class CuratorDemo {private final static String CLUSTER_CONNECT_STR="192.168.31.5:2181,192.168.31.176:2181,192.168.31.232:2181";public static void main(String[] args) throws Exception {//构建客户端实例CuratorFramework curatorFramework= CuratorFrameworkFactory.builder().connectString(CLUSTER_CONNECT_STR).retryPolicy(new ExponentialBackoffRetry(1000,3)) // 设置重试策略.build();//启动客户端curatorFramework.start();String path = "/users";Stat stat = curatorFramework.checkExists().forPath(path);if (stat==null){String s = curatorFramework.create().forPath(path);}TreeCache treeCache = new TreeCache(curatorFramework, path);treeCache.getListenable().addListener(new TreeCacheListener() {@Overridepublic void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {System.out.println(" tree cache: {}"+event.toString());Map<String, ChildData> currentChildren = treeCache.getCurrentChildren(path);System.out.println("currentChildren: {}"+ currentChildren.toString());}});treeCache.start();Thread.sleep(Integer.MAX_VALUE);} }
第三步:服务器端客户端对节点进行一些操作

第四步:查看java客户端控制台信息:监听到了对应操作
3. 总结
以上是对zookeeper java客户端对zookeeper的基本操作,到此zookeeper java客户端的介绍到此为止,更详细的实践应用,后续会出一些zk常用场景是如何实现的文章。